







ML Kit for Firebase + iOSで簡単テキスト認識やってみた
![]()
モバイルソリューショングループのarai.yaです。こんにちは。
先日のGoogle I/Oで、ML Kit for Firebaseなるものが発表されましたね。(ちなみに2018年5月ではまだβ版です。)
機械学習に関する技術をモバイルアプリで簡単に実行できるということで、非常に気になるプロダクトです。
今回はこのML Kitを使って、テキスト認識を行うシンプルなアプリをつくってみます。
ML Kit for Firebaseとは?
ML Kit for Firebaseは、機械学習に関する技術を、専門的な知識を必要とせずiOSやAndroidのアプリで簡単に実行するためのSDKです。
次のような一般的なユースケースに対応したAPIが予め用意されており、ML Kitを導入することでこれらの技術をすぐに実行できます。
- テキスト認識
- 顔検出
- バーコードスキャン
- 画像のラベリング
- 建物の認識
なお今後もAPIの種類は増えていくようです。
またこれらの検出処理は、デバイス上でオフラインで行うモードと、クラウドを利用してオンラインで行うモードがあります。
デバイス上での実行とクラウドでの実行は、以下のような特徴があります。
デバイス上での検出
-
インターネットに接続していなくても使用できる
-
素早い検出が可能
-
デバイスの限られた計算リソースで実行するため、精度は(クラウドでの実行に比べて)低い
クラウドでの検出
-
Googleが提供するクラウド上の強力な計算機で検出処理を実行することで、より高い精度の検出ができる
-
インターネットへの接続が必要
現在、デバイス上で実行できるタスク、クラウドで実行できるタスクは以下のようになっています。

デバイス上、クラウド上それぞれでできること
ここで紹介したタスクのクラウドでの実行では、検出にCloud Vision APIが使用されています。そのため、ML Kitの使用料金に加えてCloud Vision APIの使用料金も発生します。
(Cloud Vision APIの利用料金はこちら)
テキスト認識をやってみる
ここからはいよいよ、クラウドでのテキスト認識をiOSアプリに組み込んでみます。
今回行う手順は以下のとおりです。
-
Firebaseプロジェクトの作成
-
Blazeプランにアップグレードする
-
ML KitおよびVision APIを有効にする
-
ML Kitを導入する
-
コードを書く
-
遊んでみる
なおXcode 9.3、iPhone 7でやっていきます。
Firebaseプロジェクトの作成
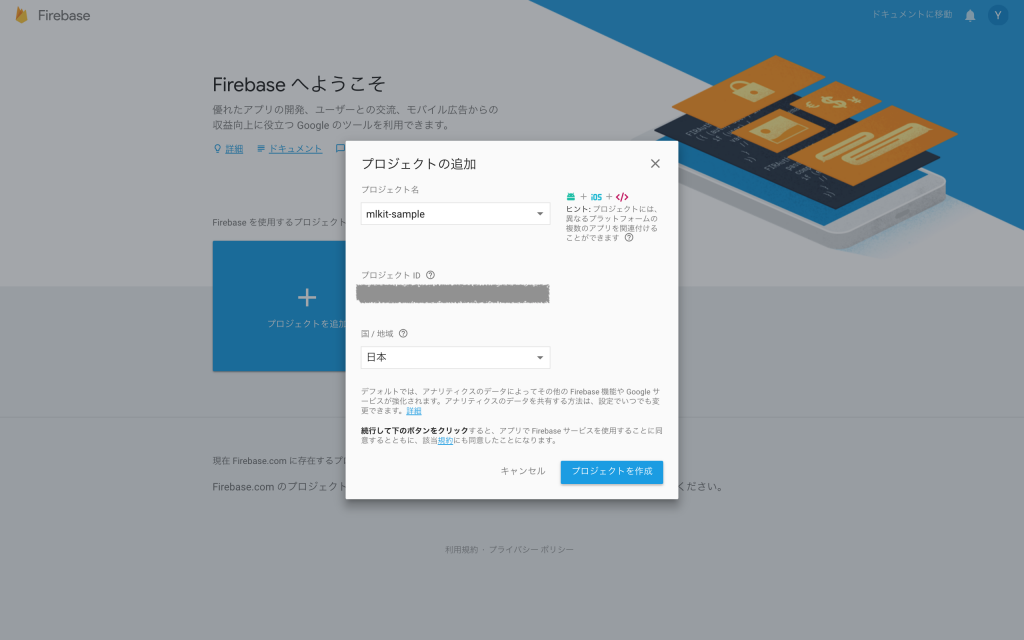
Firebaseコンソールにアクセスして、新しいプロジェクトをつくります。
プロジェクト名は好きな名前を入れて下さい。ここでは mlkit-sample とします。
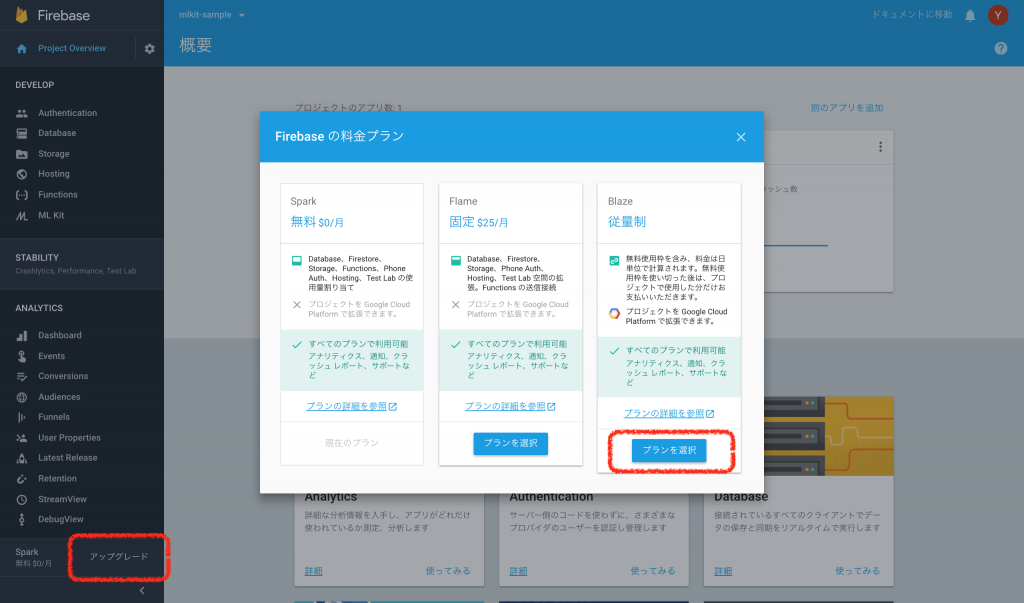
Blazeプランにアップグレードする
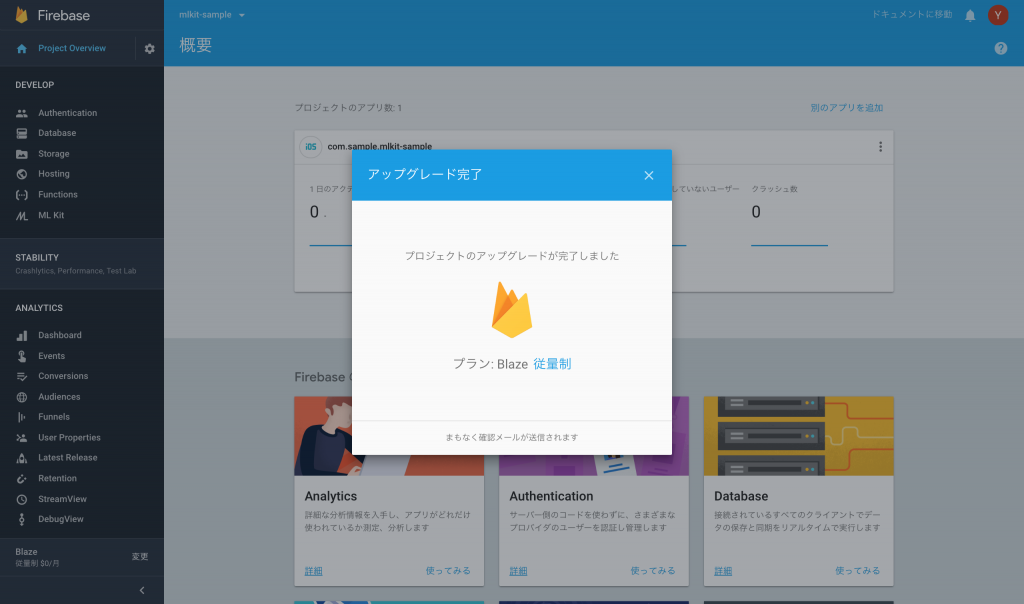
ML Kitのオンライン検出を行うため、課金を有効にする必要があります。FirebaseをBlazeプランにアップグレードします。
ML KitおよびVision APIを有効にする
料金プランをアップグレードしたら、ML KitとVision APIを有効にします。
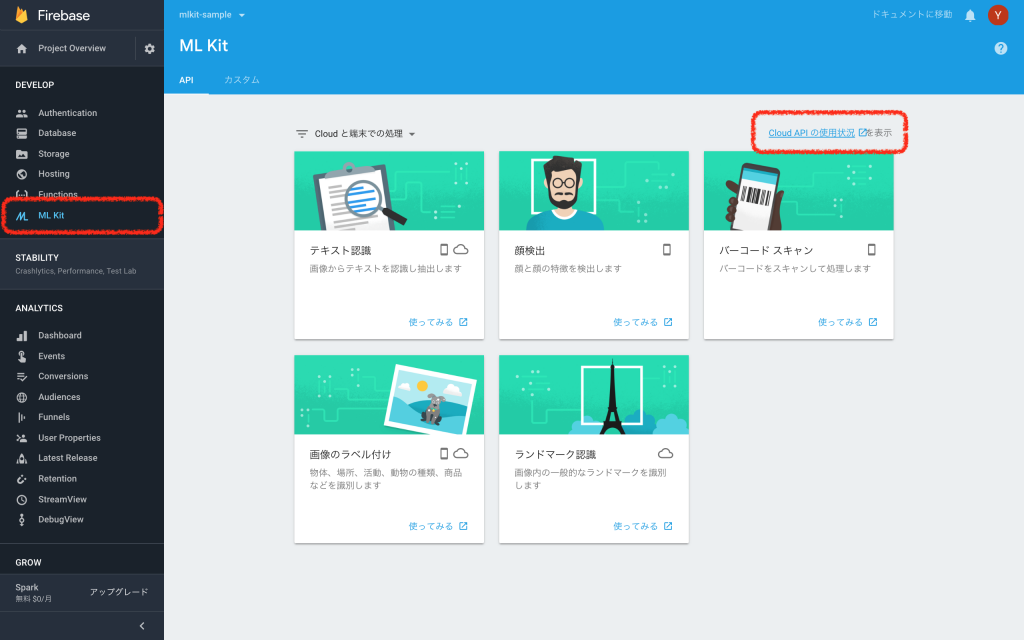
「Cloud APIの使用状況を表示」からGCPコンソールを開きます。
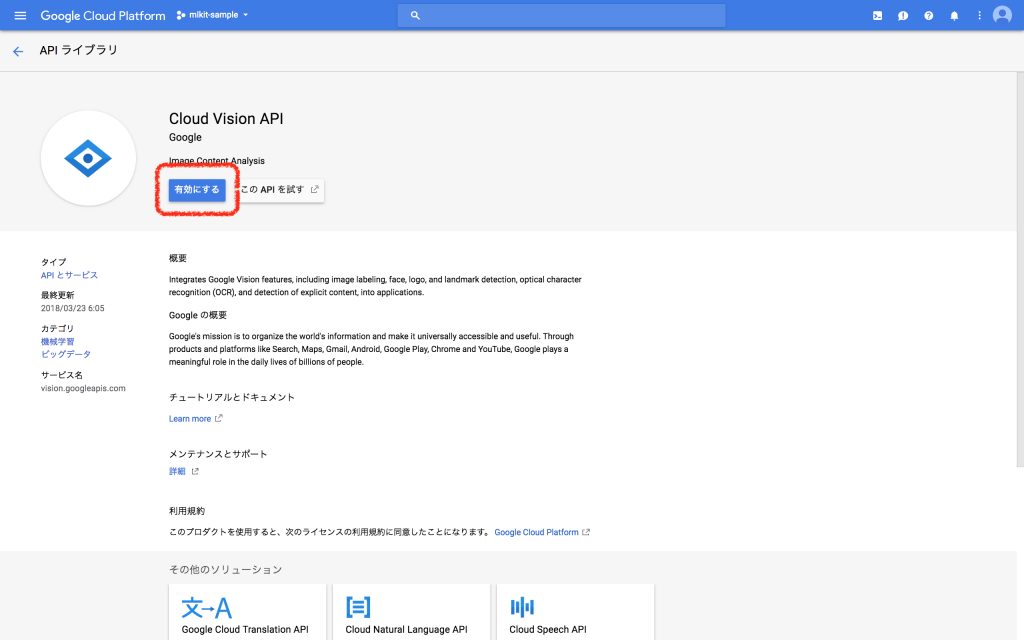
Cloud Vision APIを有効にします。
FirebaseをiOSプロジェクトに追加する
FirebaseをiOSプロジェクトに追加する を参考に、Firebase SDKを導入します。
ML Kit SDKを導入する
Podfileに次のポッドを追加して、インストールします。
pod 'Firebase/MLVision'
コードを書く
Recognize Text in Images with ML Kit on iOS を参考に、コードを書いていきます。
ViewController.swift
import UIKit
import AVFoundation
import Firebase
class ViewController: UIViewController {
@IBOutlet weak var imageView: UIImageView!
@IBOutlet weak var framesView: UIView!
@IBOutlet weak var textLabel: UILabel!
@IBOutlet weak var newButton: UIBarButtonItem!
private lazy var vision = Vision.vision()
override func viewDidLoad() {
super.viewDidLoad()
if !UIImagePickerController.isCameraDeviceAvailable(.front) || !UIImagePickerController.isCameraDeviceAvailable(.rear) {
newButton.isEnabled = false
}
let tapRecognizer = UITapGestureRecognizer(target: self, action: #selector(didTapFrameLayer(_:)))
self.framesView.addGestureRecognizer(tapRecognizer)
}
private func recognize() {
clear()
// テキスト検出する画像を指定
guard let image = imageView.image else { return }
let visionImage = VisionImage(image: image)
// テキスト検出を実行
vision.cloudTextDetector().detect(in: visionImage) { [weak self] (features, error) in
guard let strongSelf = self else { return }
guard let features = features else {
if let error = error { strongSelf.textLabel.text = error.localizedDescription }
return
}
guard let recognizedPages = features.pages else {
strongSelf.textLabel.text = "**** failed to detect."
return
}
// 検出結果を取得して表示する
for page in recognizedPages {
guard let blocks = page.blocks else { continue }
for block in blocks {
guard let blockText = strongSelf.buildBlockText(from: block) else { continue }
strongSelf.drawBlockFrame(block.frame, withText: blockText)
}
}
}
}
private func buildBlockText(from block: VisionCloudBlock) -> String? {
guard let paragraphs = block.paragraphs else { return nil }
return paragraphs
.compactMap { $0.words?
.compactMap { $0.symbols?.compactMap { $0.text }.joined() }
.joined(separator: " ") }
.joined(separator: "\n")
}
private func drawBlockFrame(_ frame: CGRect, withText text: String) {
guard let image = imageView.image else { return }
let scaleFactor = imageView.frame.width / image.size.width
let scaledImageHeight = image.size.height * scaleFactor
let scaledImageWidth = image.size.width * scaleFactor
let xOffset = (imageView.frame.width - scaledImageWidth) / 2
let yOffset = (imageView.frame.height - scaledImageHeight) / 2
let layer = CALayer()
layer.setValue(text, forKey: "BlockText")
layer.frame = CGRect(x: frame.origin.x * scaleFactor + xOffset,
y: frame.origin.y * scaleFactor + yOffset,
width: frame.width * scaleFactor,
height: frame.height * scaleFactor)
layer.borderWidth = 1.0
layer.borderColor = UIColor.red.cgColor
framesView.layer.addSublayer(layer)
}
private func clear() {
textLabel.text = ""
guard let sublayers = framesView.layer.sublayers else { return }
for sublayer in sublayers {
if let _ = sublayer.value(forKey: "BlockText") as? String {
sublayer.removeFromSuperlayer()
}
}
}
@objc func didTapFrameLayer(_ sender: Any) {
guard let tapRecognizer = sender as? UIGestureRecognizer,
let frameLayers = framesView.layer.sublayers else { return }
let tappedPoint = tapRecognizer.location(in: framesView)
let tappedLayers = frameLayers.filter { $0.frame.contains(tappedPoint) }
textLabel.text = ""
if let tappedLayer = tappedLayers.first {
if let text = tappedLayer.value(forKey: "BlockText") as? String {
textLabel.text = text
}
}
}
@IBAction func didTabNewButton(_ sender: Any) {
let imagePickerController = UIImagePickerController()
imagePickerController.sourceType = .camera
imagePickerController.delegate = self
present(imagePickerController, animated: true)
}
}
extension ViewController: UIImagePickerControllerDelegate {
func imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [String : Any]) {
if let image = info[UIImagePickerControllerOriginalImage] as? UIImage {
let scaleFactor = imageView.frame.width * UIScreen.main.scale / image.size.width
let scaledSize = CGSize(width: image.size.width * scaleFactor,
height: image.size.height * scaleFactor)
guard let resizedImage = image.resized(to: scaledSize) else { return }
imageView.image = resizedImage
recognize()
}
picker.dismiss(animated: true)
}
func imagePickerControllerDidCancel(_ picker: UIImagePickerController) {
picker.dismiss(animated: true)
}
}
extension ViewController: UINavigationControllerDelegate {}
extension UIImage {
func resized(to size: CGSize) -> UIImage? {
UIGraphicsBeginImageContextWithOptions(size, false, scale)
draw(in: CGRect(origin: .zero, size: size))
let resizedImage = UIGraphicsGetImageFromCurrentImageContext()
UIGraphicsEndImageContext()
return resizedImage
}
}コードの大部分はUIの設定などです。テキスト検出を行うコードは数えるほどの行数しか書いていません。
Main.storyboardはこんな感じにします。
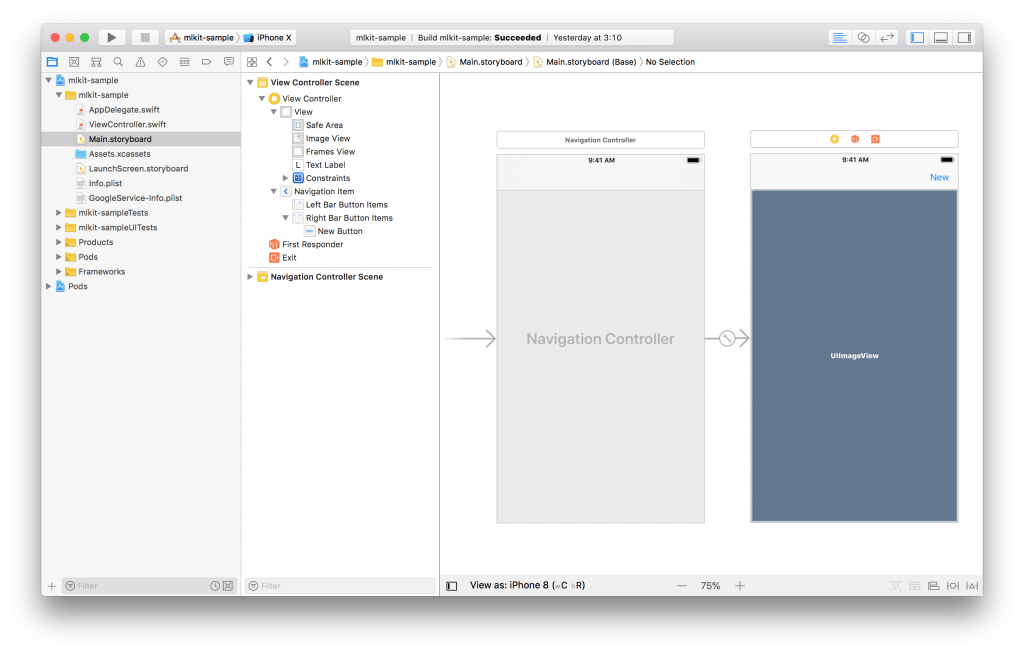
ImageViewのContent Modeは “Aspect Fit” を指定して下さい。
次に、カメラを利用するので、アクセス許可を求める際の説明文を設定します。
info.plist に追加します。
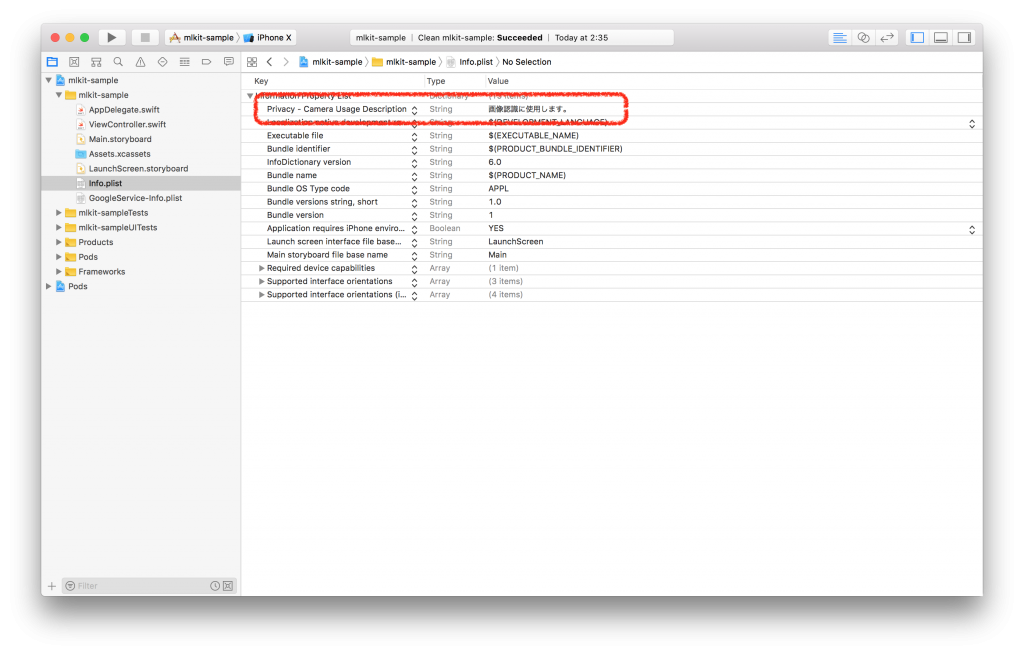
完成です! 🙂
遊んでみる
実機にビルドして、遊んでみます。
検出したいテキストの写真を撮ります。
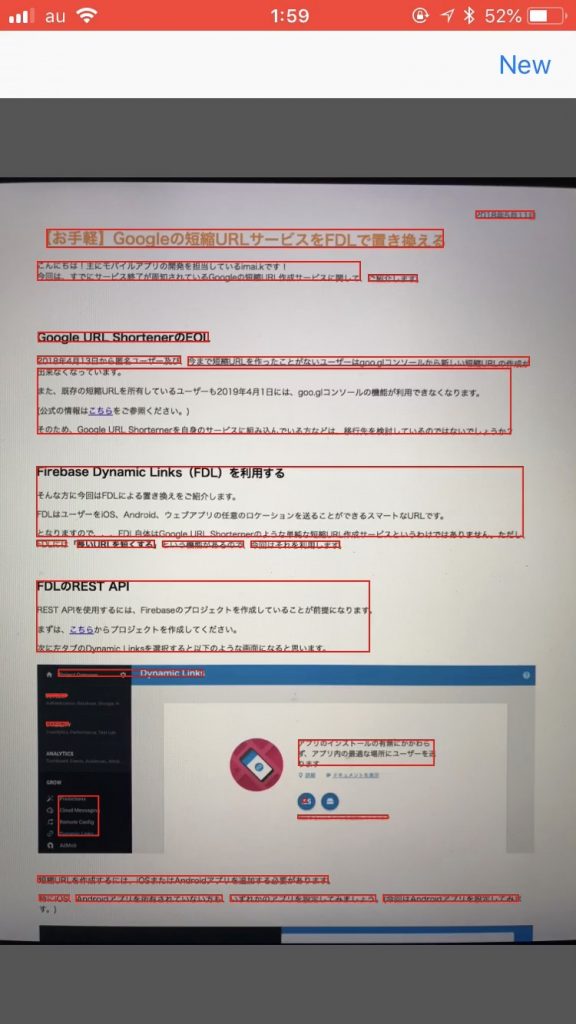
ML Kitが検出した テキストに枠を表示するようにしました。
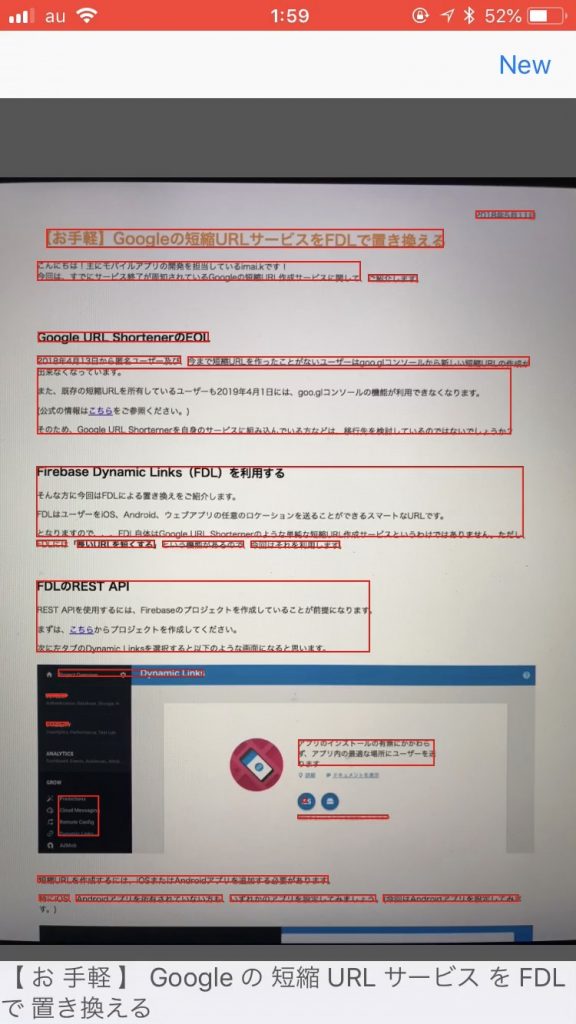
枠をタップすると、検出したテキストを表示します。
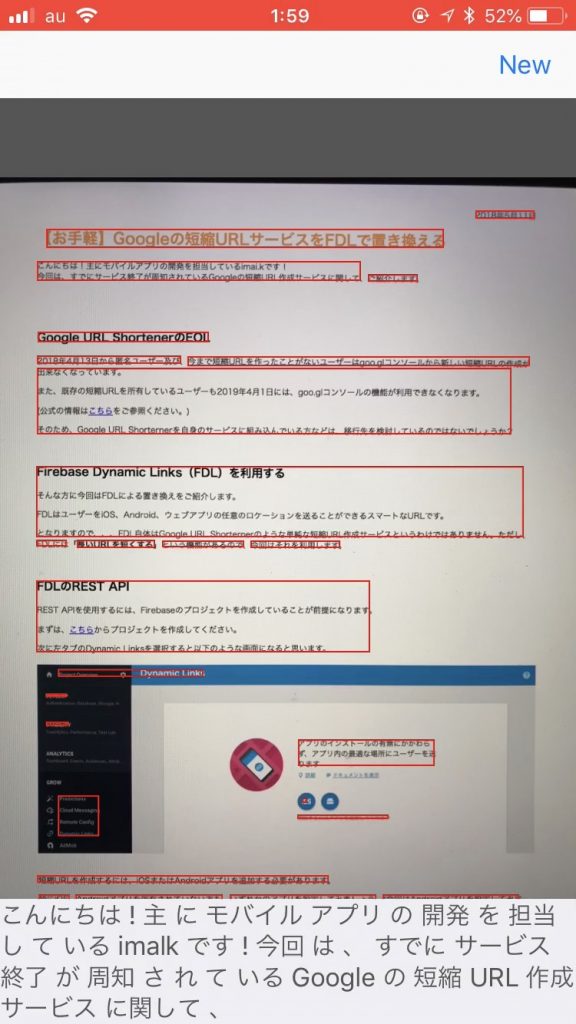
かなり正確に文章を認識しています 🙂
最後に
今回はML Kitでオンラインテキスト検出を行うiOSアプリをつくってみました。簡単なコードを書くだけでGoogleが提供するパワフルな機械学習APIを実行できたので、とても魅力的だと感じました。
そのうちオフラインでの顔検出やラベリングもやってみようと思います 🙂