







【AWS】Bedrock Knowledge BasesでフルマネージドなRAGを実装してみた!

こんにちは。システムサービス本部クラウドソリューショングループのshimizuyです。
今回はAWSで構築可能なRAGの中でも、フルマネージドでの実装が可能で、構築における手間を極限まで削減可能な構成をご紹介します。
(ちなみにサムネイルはChatGPTに生成してもらいました。)
前提: LLMとRAGの違いとは?
AIのビジネス活用において近年注目を集めているのが「RAG(ラグ)」です。RAGは「Retrieval-Augmented Generation」の略称で、日本語では「検索拡張生成」と呼ばれます。
では、ChatGPTやClaude、Geminiといった一般的なLLM(大規模言語モデル)をそのまま使う場合と、RAGを組み合わせた場合では、具体的に何が違うのでしょうか。
LLM単体の課題
LLMは膨大な知識を持っていますが、事前に学習したデータに含まれない情報(最新のニュースや、非公開の社内規定、独自のマニュアルなど)については、正確に回答することができません。無理に答えようとして、事実とは異なる回答(ハルシネーション)を生成してしまうリスクもあります。
RAGのアプローチ
この「学習していない内容については答えられない」というLLMの課題を解決するのがRAGです。
インターネットには公開されていない自社のドキュメントや最新のデータベースを連携させることで、LLM (Large Language Model: 大規模言語モデル) が持つ内部知識を補う外部知識を活用することが可能となり、より信頼性の高い回答を生成できるようになります。
RAGの仕組みとプロセス
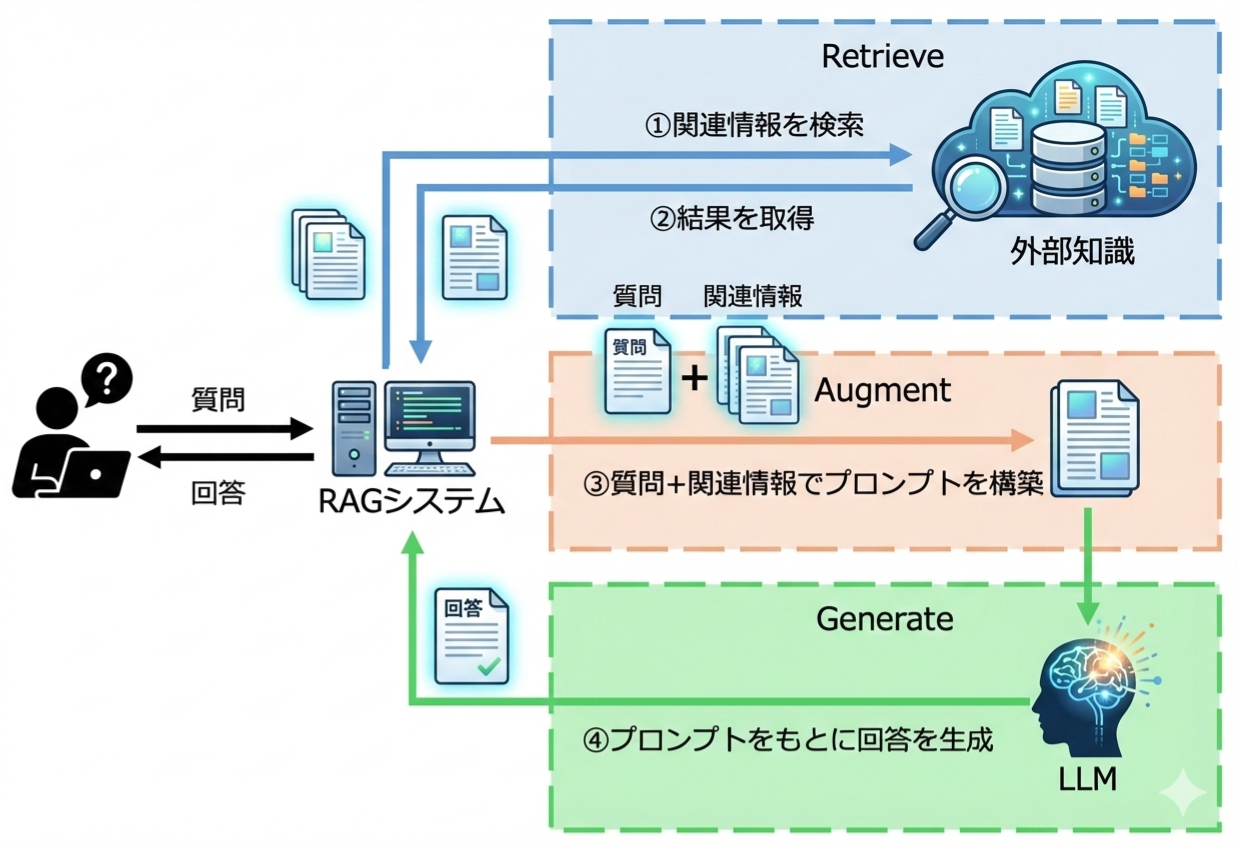
RAGは、その名前の通り、主に以下の3つのステップで機能します。
-
検索(Retrieve):
ユーザーの質問を受け、あらかじめ連携された社内資料やデータベースの中から、関連する情報を瞬時に探し出します。
具体的には、SQLのデータベースやベクトルデータ・ナレッジグラフなどを用いて、質問を検索し、回答のエビデンスとなる情報を取得します。
-
拡張(Augment):
探し出した関連情報をLLMへの指示文(プロンプト)に「参考情報(コンテキスト)」として組み込むことで、プロンプトを拡張します。
RAGではユーザーからの指示文だけでなく、検索(Retrieve)工程で取得した情報を組み合わせることで質問文の精度を向上させたプロンプトを利用します。
-
生成(Generate):
このフェーズでは、ユーザーの質問に対する最終的な回答を生成します。
基本的にはChatGPTやGeminiなどに直接質問する際の工程と同様ですが、違いがあるとすれば、拡張(Augment)工程で作成されたプロンプトを利用して最終的な指示を受け付けるという点です。
RAGについての大まかな仕組みの説明は上記の通りになります。
ざっくり概要の理解ができましたら、さっそくBedrock Knowledge Basesを用いたRAGの実装に移っていきましょう。
Bedrock Knowledge Basesを用いたRAGの実装
構成
今回作成する構成図は以下の通りです。
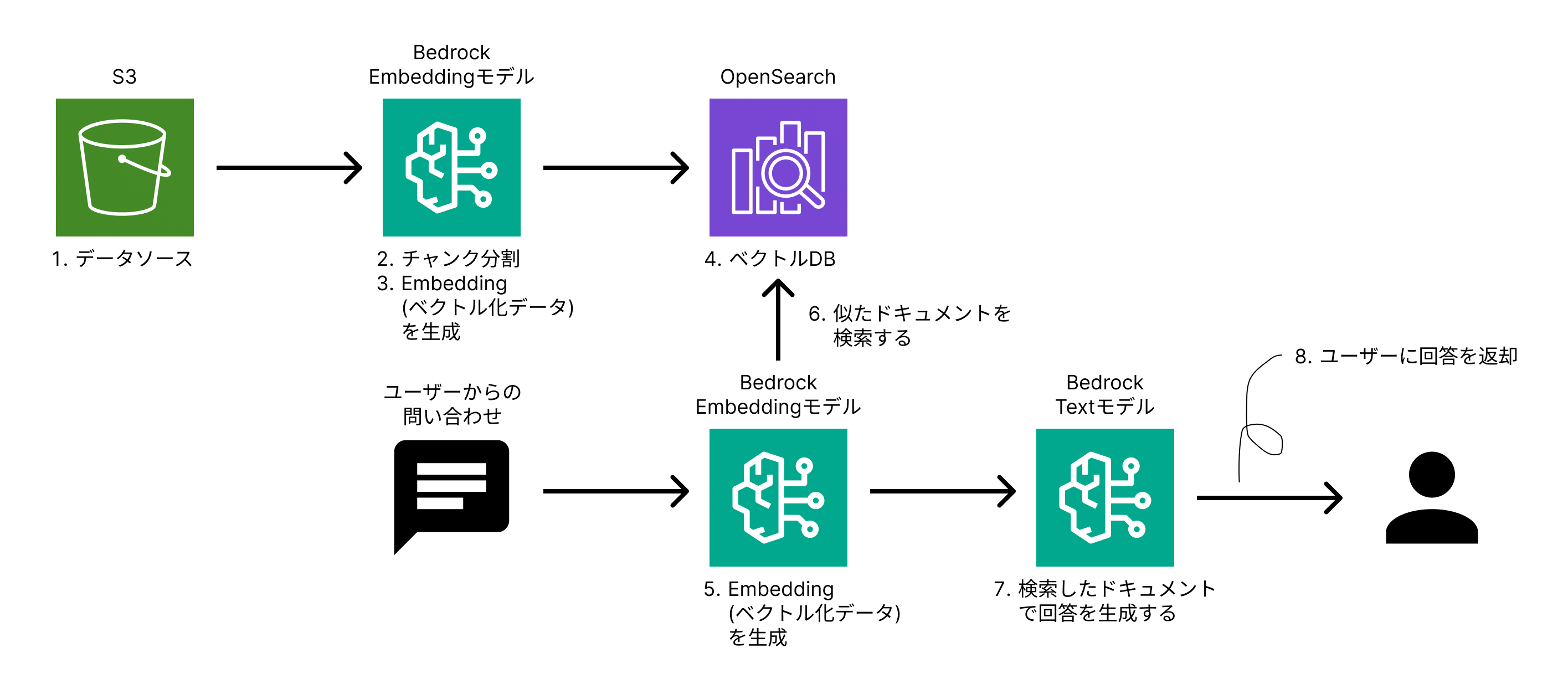
Bedrock Knowledge BasesとベクトルデータストアであるOpenSearch Serverlessを組み合わせた構成にしました。
なお、以降の手順において特別な設定は不要ですが、前提条件としてアクセス許可とリージョンの意識はするとよいでしょう。
1. S3にデータソースを配置する
S3バケットに配置したファイル内の情報をリソース元としたRAGを実装していきますので、事前にお好みでデータソースやドキュメントを用意してください。
Amazon S3 > バケット > 汎用バケット > バケットを作成 の順に押下してバケットを作成し、作成したバケットにデータソースをアップロードしましょう。
今回は架空の古本買取企業ISORAT社の書籍買取査定基準マニュアル(pdf)をChatGPTに作成してもらったので、そちらをデータソースとして利用していきます。
2. Bedrock Knowledge Basesを作成する
続いてBedrock Knowledge Basesを作成していきましょう。
Amazon Bedrock > ナレッジベース > 作成 > ベクトルストアを含むナレッジベースの順に押下していきます。
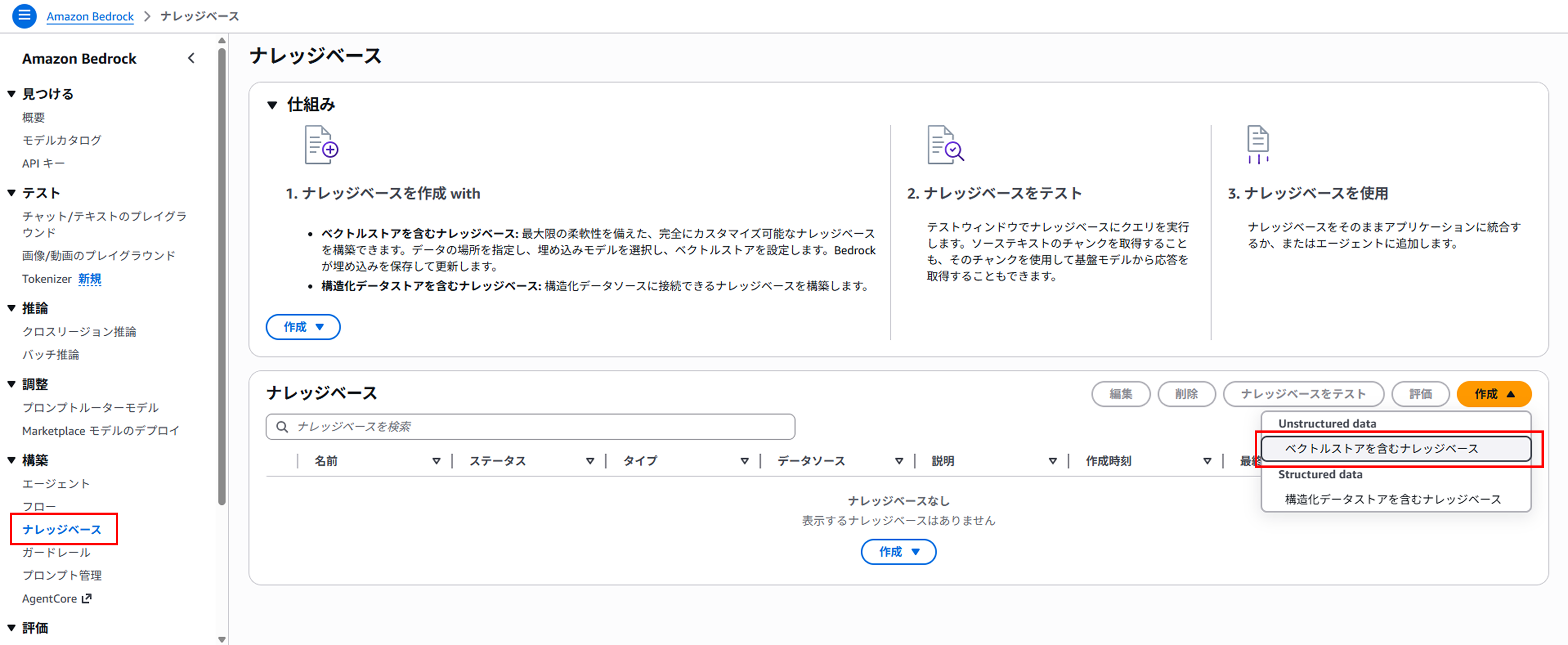
データソースでAmazon S3を選択してください。
その他の設定に関してはデフォルトでも大丈夫です。
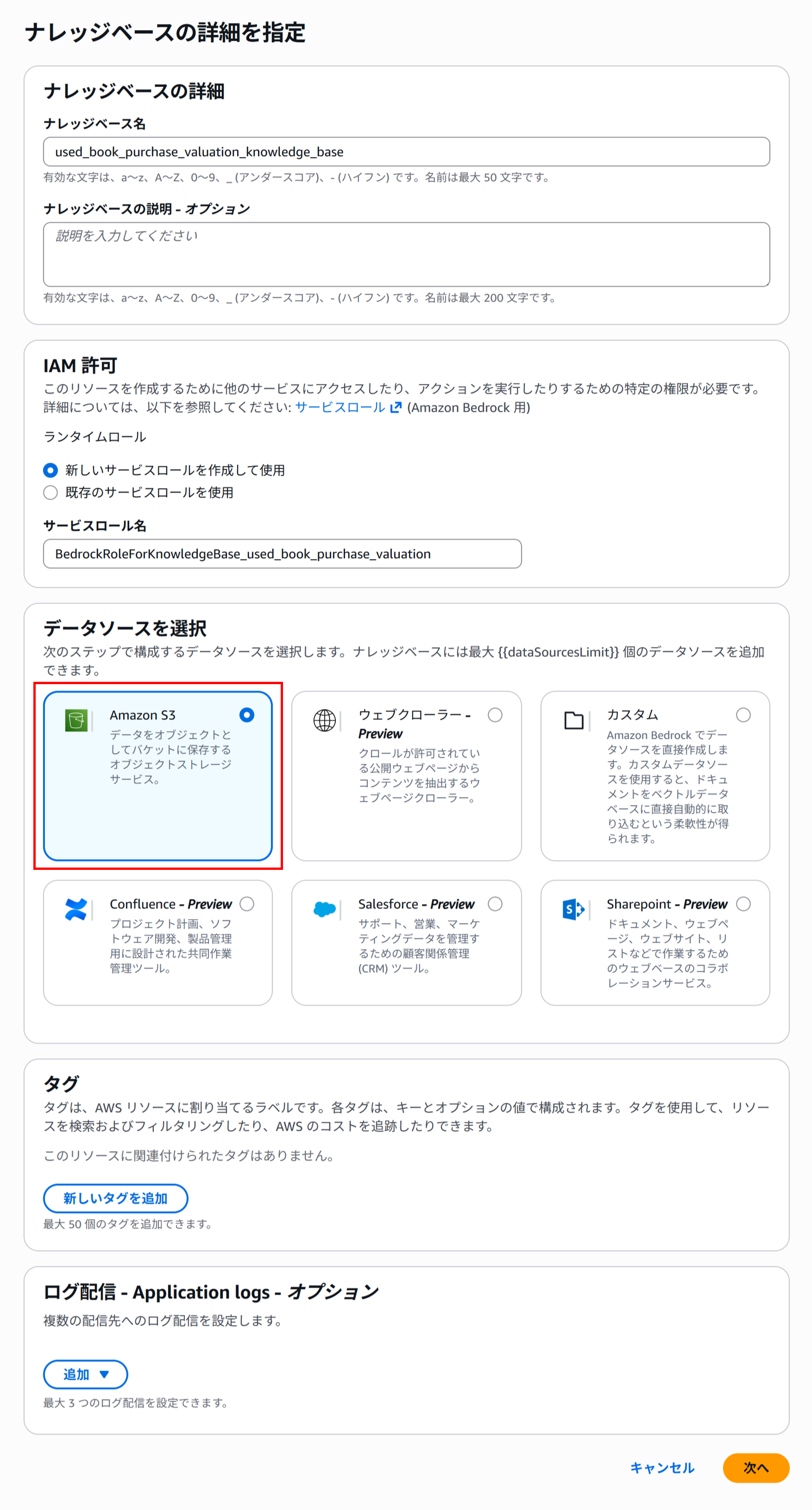
データソースとして、先ほど作成したS3を選択します。
こちらに関してもその他の設定に関してはデフォルトでも大丈夫です。
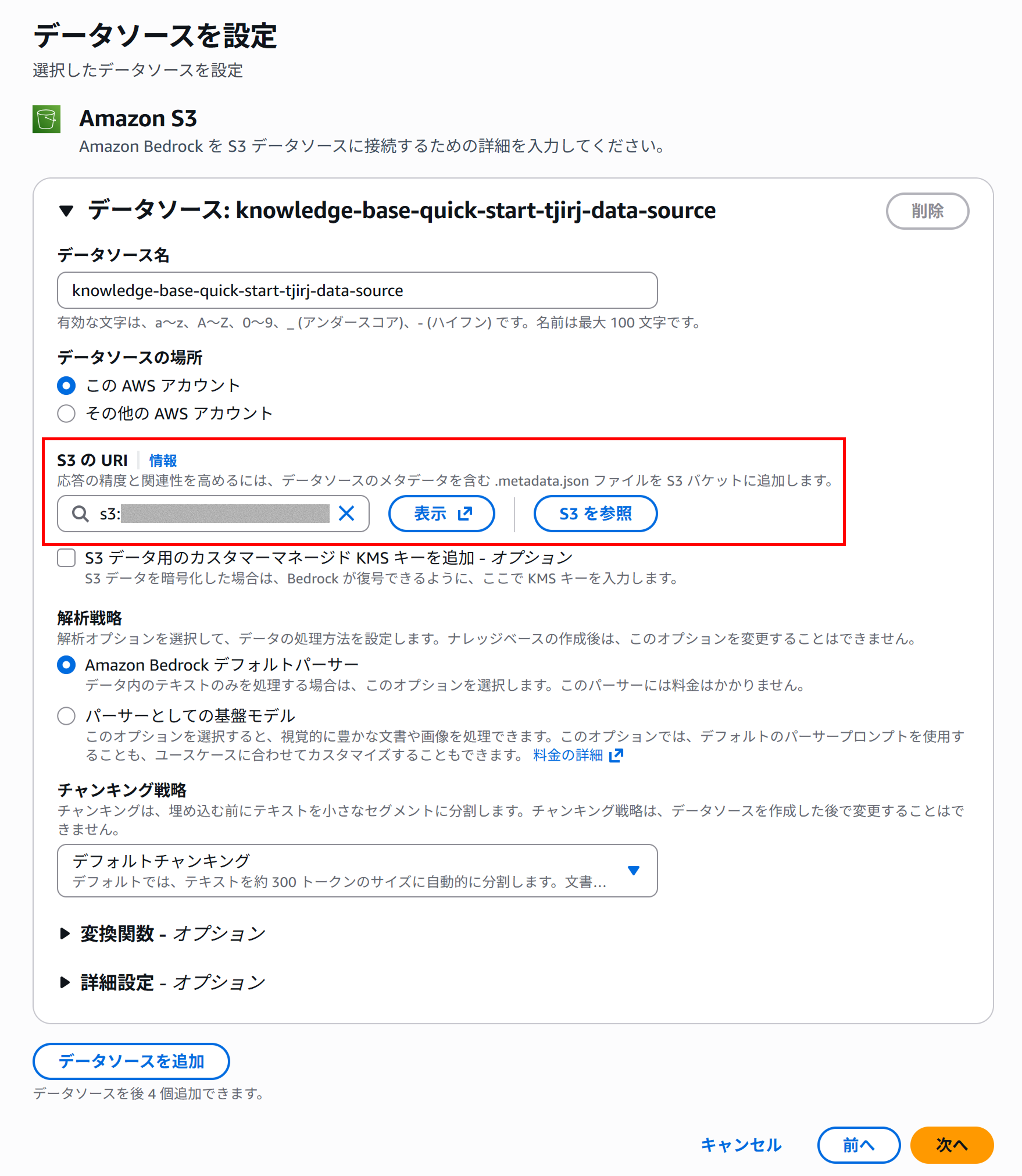
データストレージと処理の設定では、S3に保存したデータをベクトル化するための埋め込みモデルとベクトル化したデータを保存、更新、管理するためのベクトルストアを以下の通り選択します。
-
埋め込みモデル: Titan Text Embeddings V2
-
ベクトルストア: Amazon OpenSearch Serverless
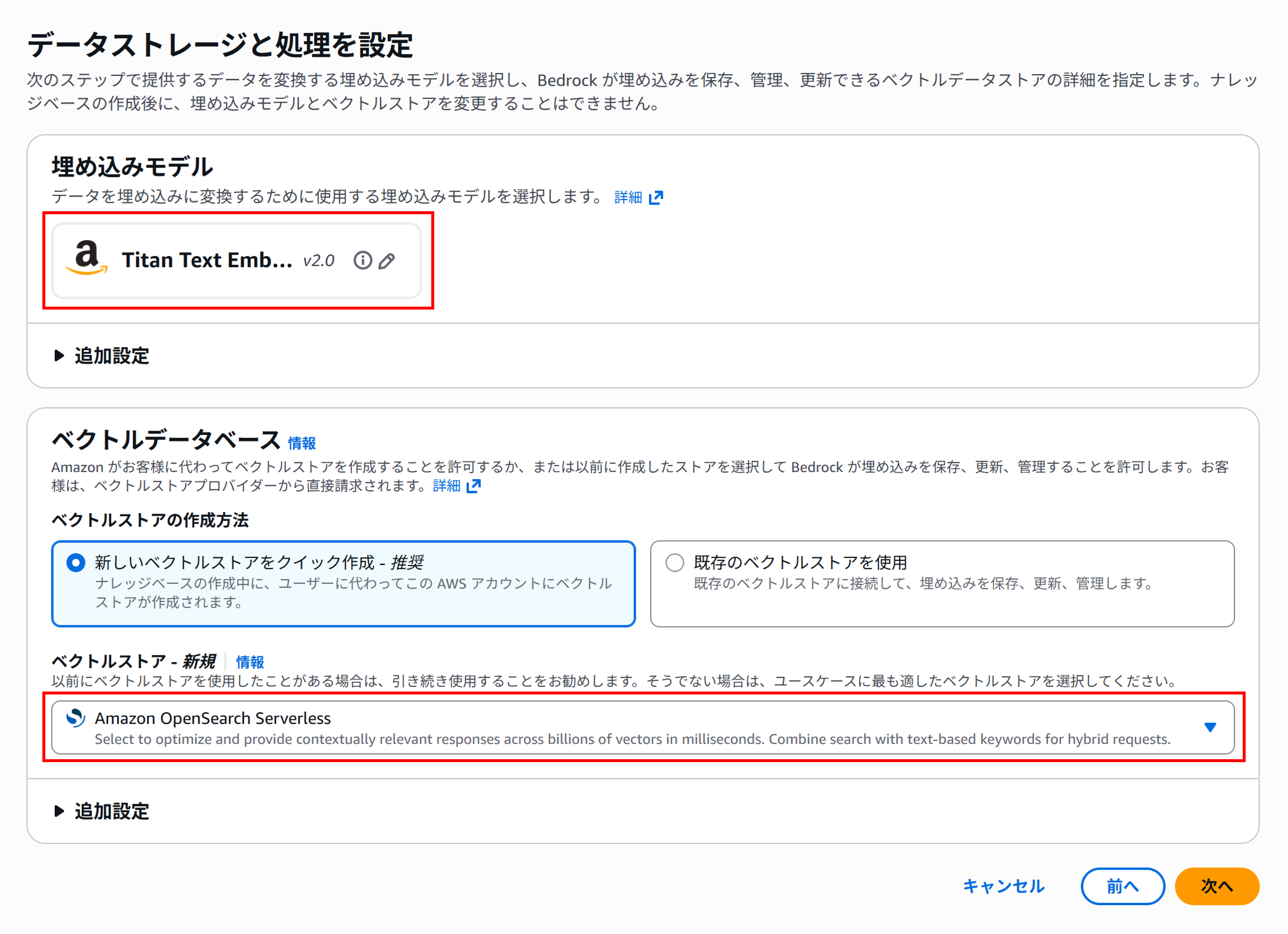
確認画面で設定に問題がなければ、作成してください。
3. データソースを同期する
ナレッジベースの作成が完了すると、ステータスが「✅利用可能」に変化します。
ただし、このままではOpenSearch Serverless側でベクトルデータが含まれていないためRAGとして機能しません。
データソースから対象のS3バケットを選択し、同期を実行することで、
-
S3上のデータを解析・分割(chunking)
-
埋め込み(ベクトル化されたデータ)の生成
-
OpenSearch Serverless のベクトルインデックスへ埋め込みの格納
上記処理が実行され、OpenSearch Serverlessでベクトルデータを取り扱うことが可能になります。
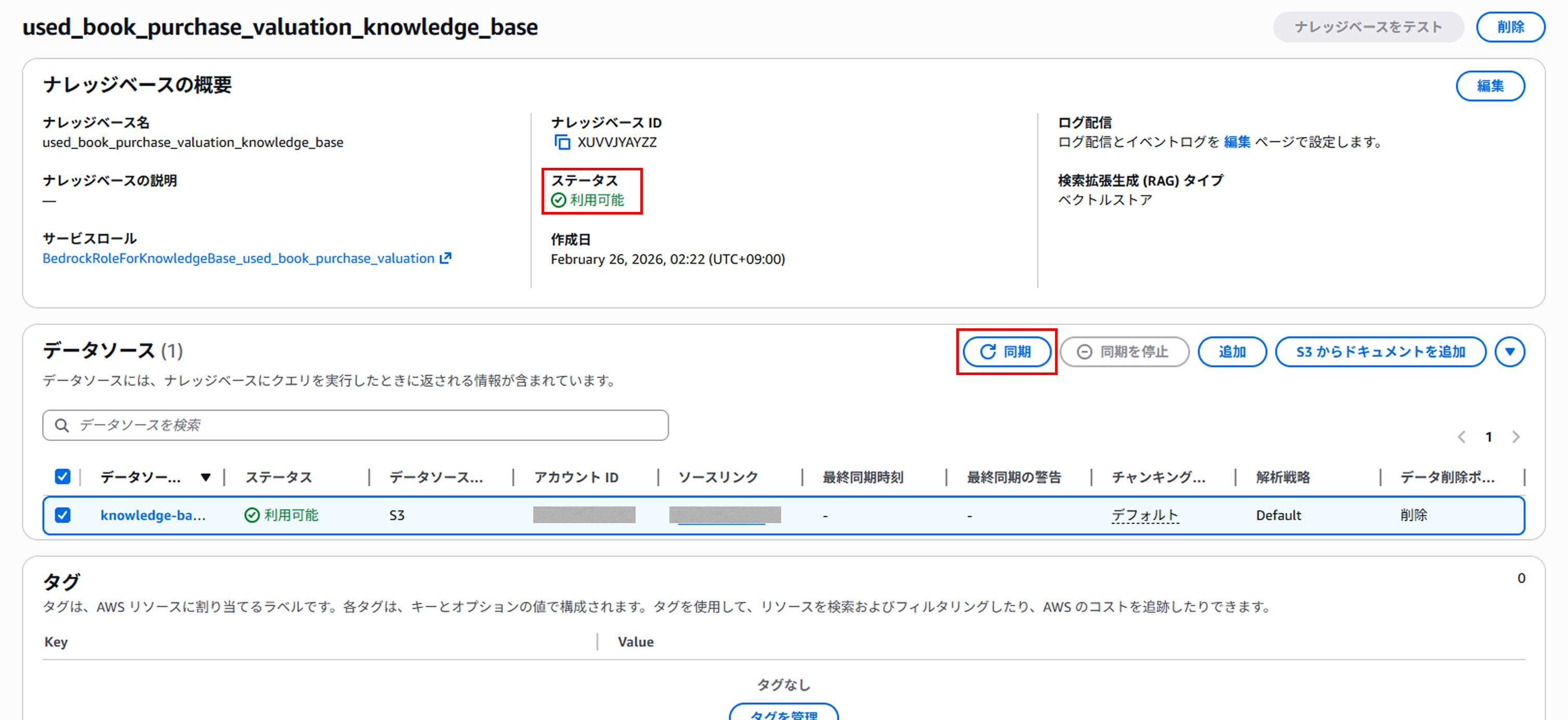
ここまででRAG構築はすべて完了となります。
RAGの検証
それではRAG機能の検証に移っていきましょう。
作成したナレッジベース画面の右上から「ナレッジベースのテスト」を押下することで動作検証画面に遷移できます。
こちらではユーザーからの質問に対してベクトル検索を実行した結果を元に回答を生成するためのモデルを選択します。
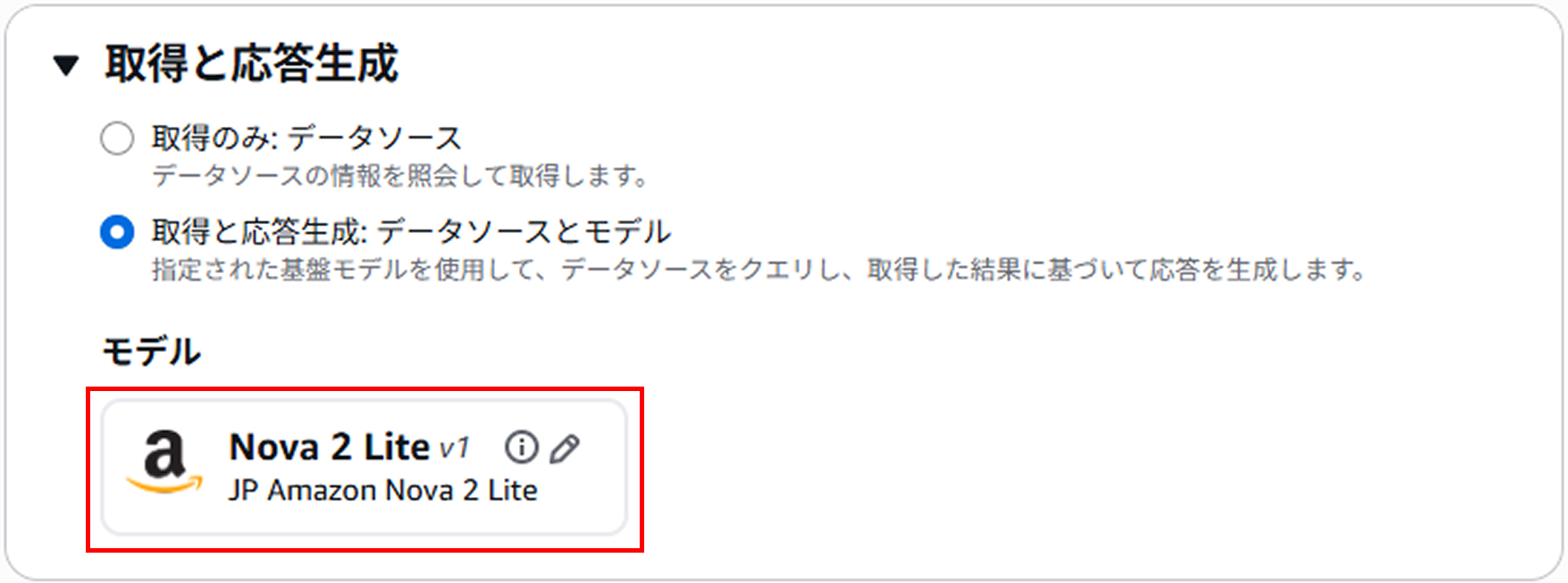
今回はAmazonが提供する「Nova 2 Lite」を選択しました。
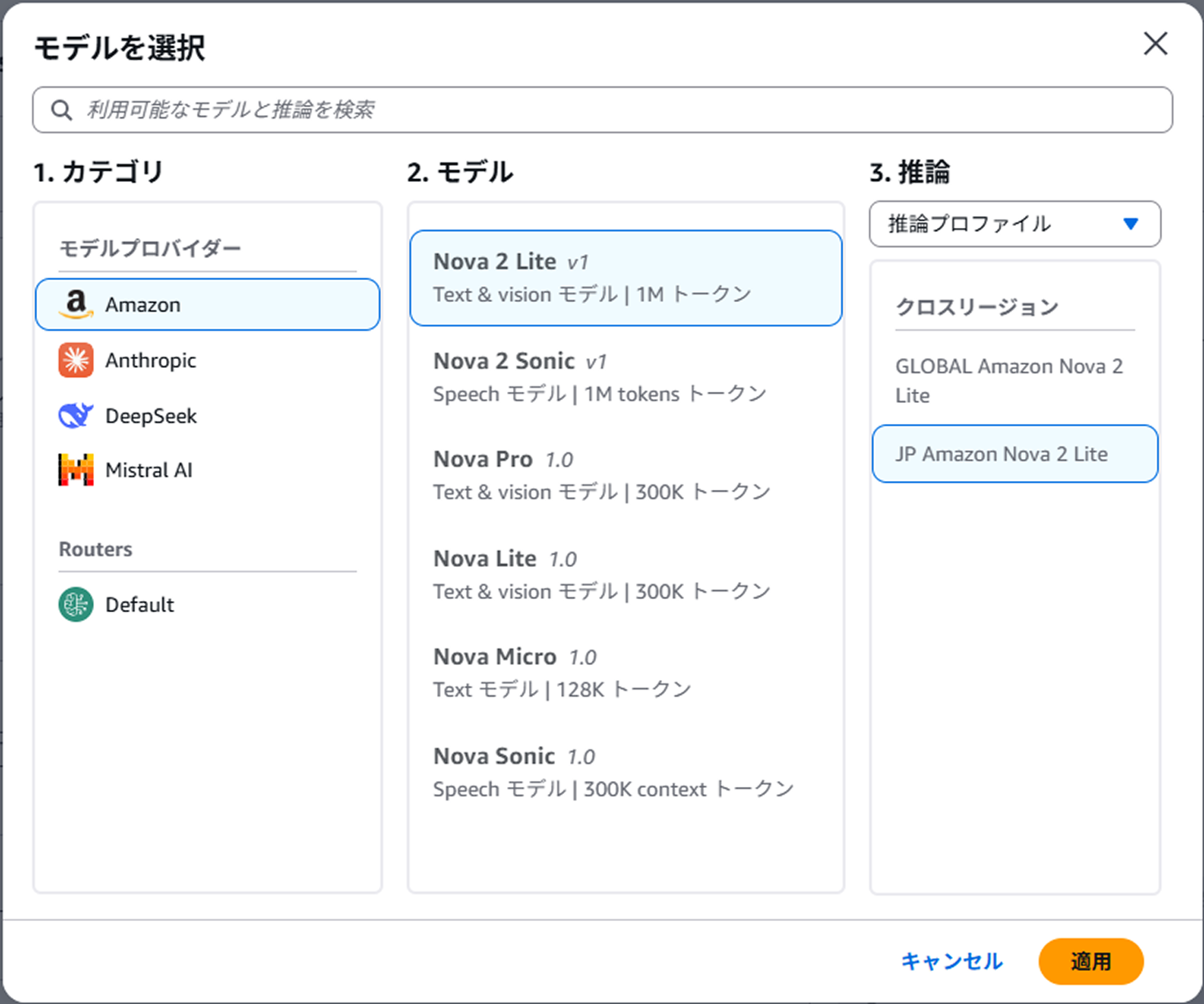
余談ですが、Anthropic社の最新モデルであるClaude Opus 4.6なんかも選択できます。(2026/2/26現在)
モデルの適用が完了すると、いよいよチャット形式でのRAG検証が可能になります。
テキストエリアから質問文を入力して古本の買取査定に関する質問を投げかけてみましょう。
質問①
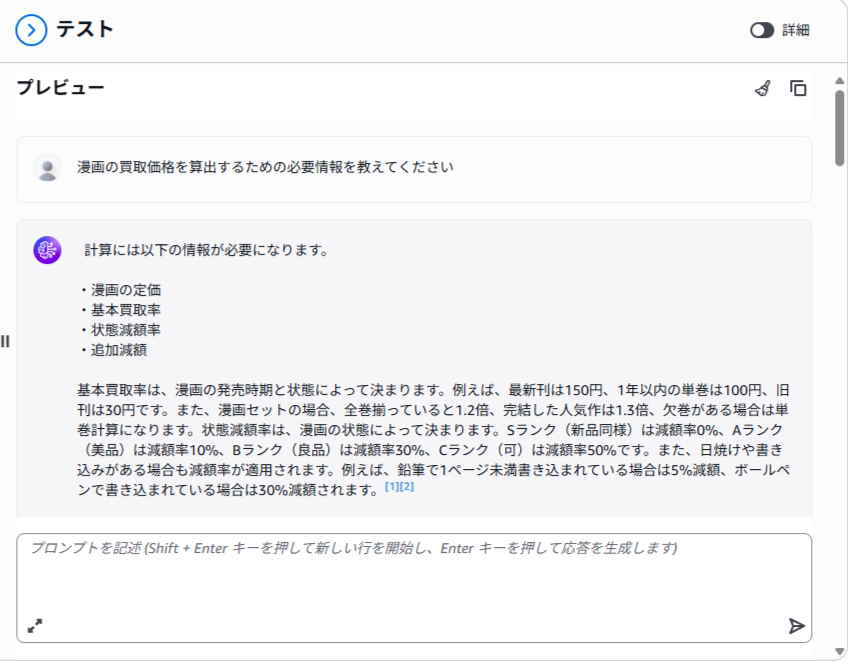
質問②
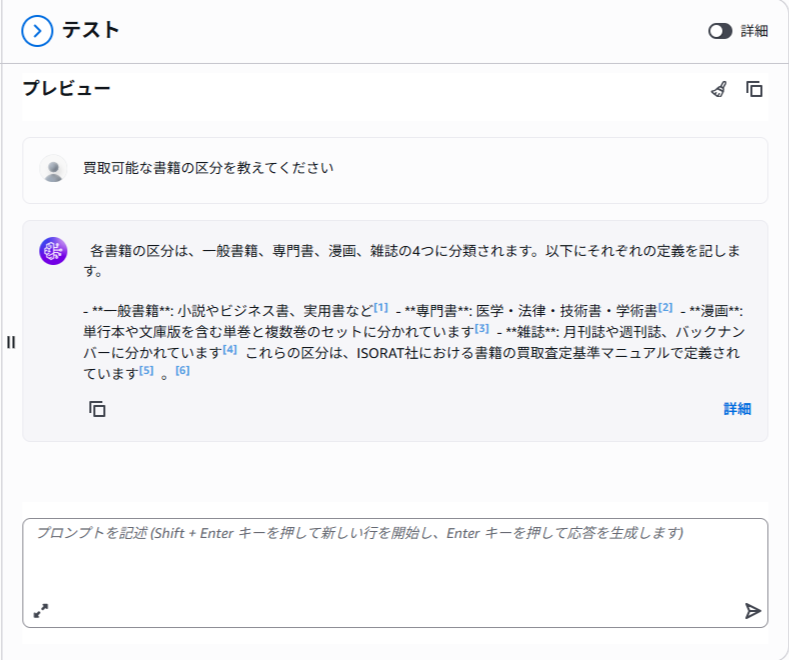
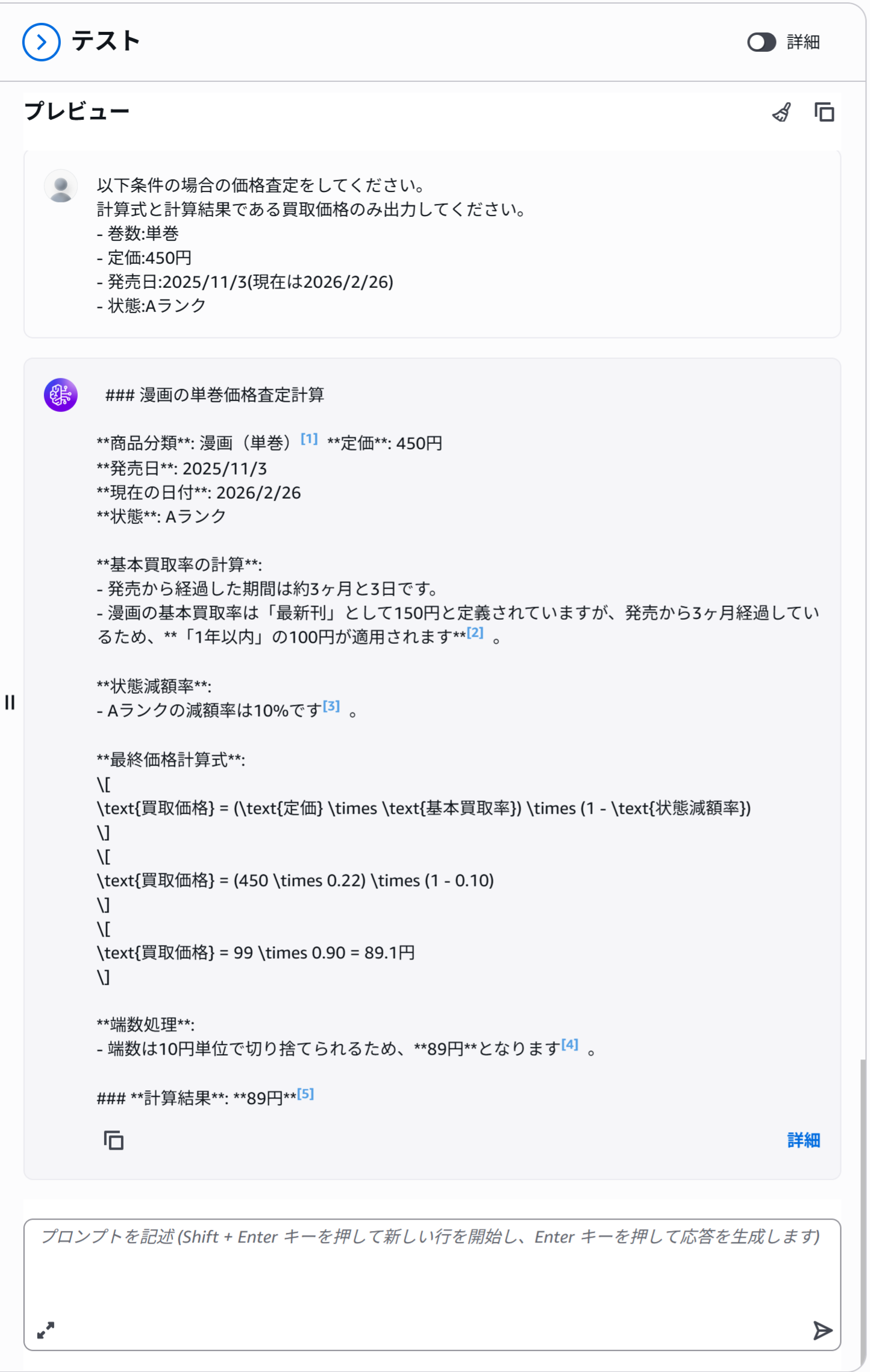
質問③
質問①や②のようにデータソースの中に直接的な答えがあるような質問に関しては比較的明瞭な回答をしてくれるようですが、質問文(プロンプト)や回答用モデルの問題なのか100点満点の回答とは言えないですね。
質問③のようなデータソースの情報を元に回答を求める応用的な質問の場合、回答にノイズが多いなというのが正直な感想でしたが、最終的にはしっかり買取価格を算出してくれていますね。
検証後のおかたづけ
検証完了後は以下の削除リストを参考にリソースの削除を行うようにしましょう。
-
Amazon S3 > 汎用バケット > 作成したバケット
-
Amazon Bedrock > ナレッジベース > 作成したナレッジベース
-
Amazon OpenSearch Service > Serverless: Collections > 作成したコレクション
特にOpenSearch Serverlessのリソースはナレッジベース作成のフローの中で同時に作成されるため、削除を見落としてしまいがちですが、放置してしまうとかなり利用料金がかさんでしまいますので、必ず削除するようにしましょう。
おわりに
今回の記事では、Bedrock Knowledge Basesを用いたRAGの実装を試してみました。
全体的な精度向上を考えるとまだまだ改善の余地はありますが、何よりもノーコードで手軽に実装が可能かつコンソール上ですぐに動作検証ができる点がよいですね。
回答に対する精度向上という課題はありますが、そこはまた追々深堀りしていけたらと思います。
