







【ハンズオン】LibreChat × Amazon Bedrock ナレッジベースで社内ドキュメント検索環境を構築する

はじめに
みなさま、こんにちは。
クラウドソリューション第2グループ入社3年目のkugishimakです。
本記事では、LibreChatとAmazon Bedrock ナレッジベースを組み合わせて、社内ドキュメントを検索できる環境を構築する方法 を紹介します。
目次
使用するライブラリ・ツール
環境はWindowsです。
使用するものは以下の通りです。
・AWS(S3、Amazon Bedrock ナレッジベース)
・Python 3.13.7
・uv 0.8.20
・Docker
・Git
・LibreChat 0.7.8
構築までの流れ
LibreChatでAmazon Bedrock ナレッジベースを利用するまでの大まかな流れは以下のとおりです。
構築手順
1. データソースの準備
まずはデータソースの準備をします。
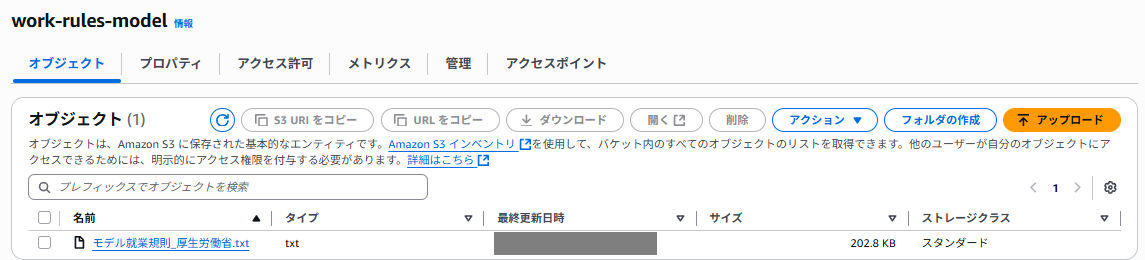
社内ドキュメントの例として、今回は厚生労働省のモデル就業規則を使用しました。
今回使用するモデルに合わせて、PDFはテキストに変更しています。
AWSコンソールからS3にアクセスし、バケットを作成して使用するデータをアップロードしておきます。
2. Amazon Bedrock ナレッジベースの作成
Amazon Bedrockでナレッジベースを作成します。
作成方法はこちらの記事の「使用までの流れ 2.ナレッジベースを作成する」を参考にしていただけると幸いです。
【AWS】Knowledge base for Amazon Bedrockをお手軽に使ってみよう
S3の設定は 1.データソースの準備で作成したものを指定してください。
また、MCPサーバーに認識させるためタグを必ず設定します。
キー:mcp-multirag-kb
値:true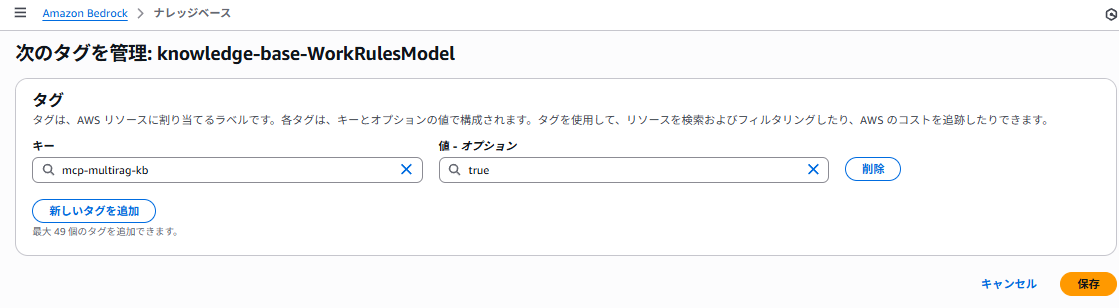
3. MCPサーバーの準備
MCPサーバーの準備をします。
今回使用するMCPサーバーは「bedrock-kb-retrieval-mcp-server」(AWS Labs提供)です。
こちらの起動のために依存ライブラリ(uv, python, AWS CLI)をインストールしておきましょう。
- uv
iwr https://astral.sh/install.ps1 -useb | iex - python
uv python install- AWS CLI
AWS CLI はこちらを参考にインストールします。
インストール後、認証情報を設定します。
認証情報はIAMユーザーで発行したアクセスキーを使用してください。
aws configure
# AWS Access Key ID
# AWS Secret Access Key
# Default region name → ap-northeast-1
# Default output format → json
4. LibreChatの準備
LibreChatの構築をしていきましょう。
今回使用するLibreChatのバージョンは0.7.8です。
構築にGitとDockerを使用するためこれらをインストールしておいてください。
1. リポジトリのクローン
Gitからクローンしてきます。
任意のフォルダで以下を実行します。
git clone https://github.com/danny-avila/LibreChat.git
クローンできたら「LibreChat」というフォルダができてます。
2. 設定ファイルの準備
LibreChatフォルダ直下に以下のファイルを用意します。
作成するファイルは以下です。
- .env
- docker-compose.override.yml
- librechat.yaml
1. .env
.env.example をコピーして .env として保存
2. docker-compose.override.yml
上記の名前でファイルを作成し、下記内容を記入して保存します。
librechat.yaml をマウントする設定です。
services:
api:
volumes:
- type: bind
source: ./librechat.yaml
target: /app/librechat.yaml
3. librechat.yaml
上記の名前でファイルを作成し、下記内容を記入して保存します。
ここでもAWS CLIのアクセスキーとシークレットキーが必要になりますのでメモしておきましょう。
version: "1"
mcpServers:
bedrock-kb:
command: uvx
args:
- "awslabs.bedrock-kb-retrieval-mcp-server@latest"
env:
AWS_REGION: "使用しているリージョン(例:ap-northeast-1)"
AWS_ACCESS_KEY_ID: "アクセスキー"
AWS_SECRET_ACCESS_KEY: "シークレットキー"
serverInstructions: true
5. 動作確認
各サービスを起動します。
1. MCPサーバーの起動
下記のコマンドを実行します。
ログに Default reranking enabled: False が表示されれば、正常に起動しています。
uv tool run --from awslabs.bedrock-kb-retrieval-mcp-server@latest awslabs.bedrock-kb-retrieval-mcp-server.exe2. LibreChatを起動
下記のコマンドを実行します。
docker compose up3. ブラウザでアクセス
http://localhost:3080 にアクセスします。
4. エージェント作成
左のアイコンから「エージェントビルダー」を選択します。
名前、使用するモデルは任意のもので構いません。
今回は以下としました。
– 名前:「就業規則検索」
- モデル:任意(例:OpenAI)
LibreChatでどのモデルを使うときも各社のAPIキーを登録する必要があります。
詳しくははこちらの記事を参考にしていただけると幸いです。
【Docker対応】オープンソース生成AIチャットツール「LibreChat」の構築手順
指示文には下記を入力しました。
# 回答ルール
- 必ず検索の結果に含まれる内容のみを用いて回答してください。
- 質問に対する回答が検索の結果に含まれない場合は、わからない旨を回答してください
- 検索の結果に回答するための情報が見つからない場合や不足している場合は必ず追加で情報を収集してください
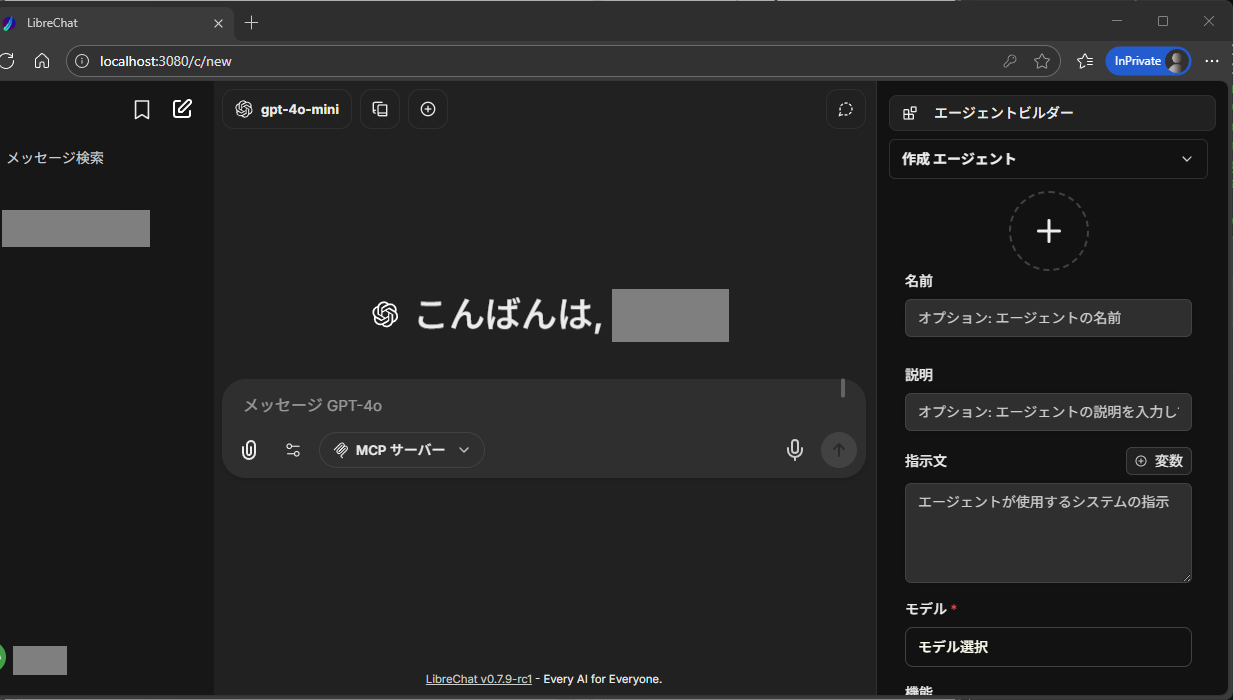
下部にある「ツールの追加」を選択し、「bedrock-kb」を追加します。
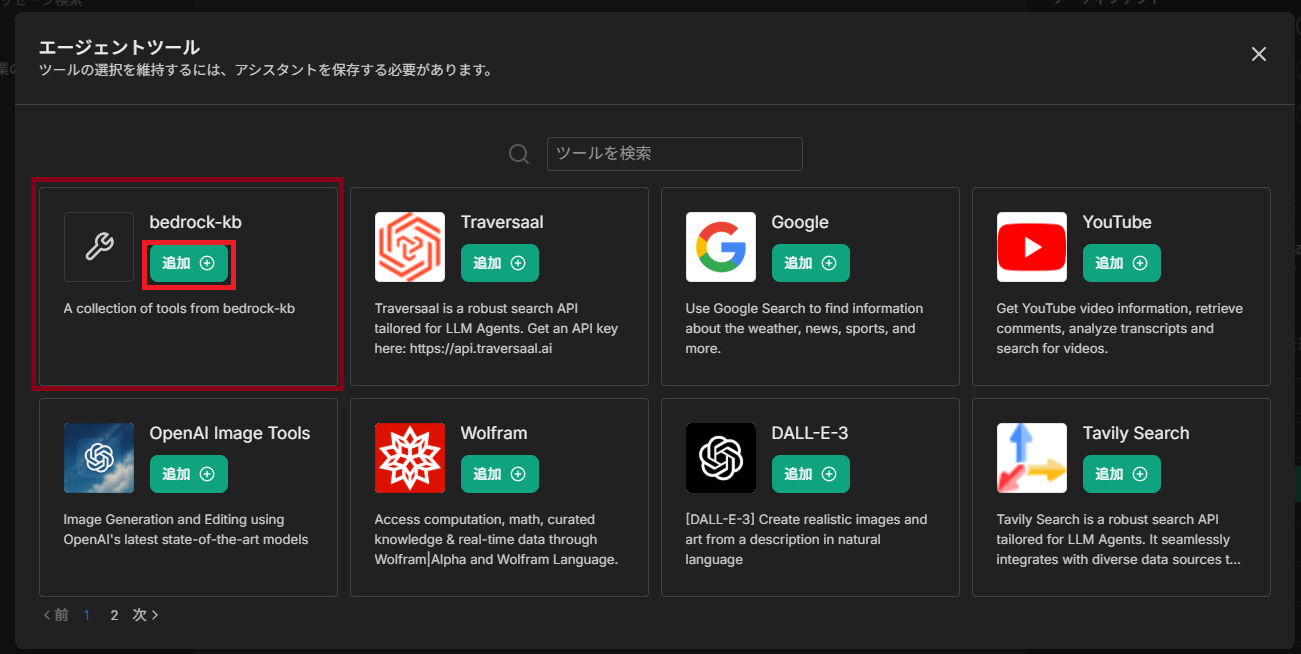
設定できたら「作成」を押下します。
モデルの選択から作成したAgents「就業規則検索」を選択しましょう。
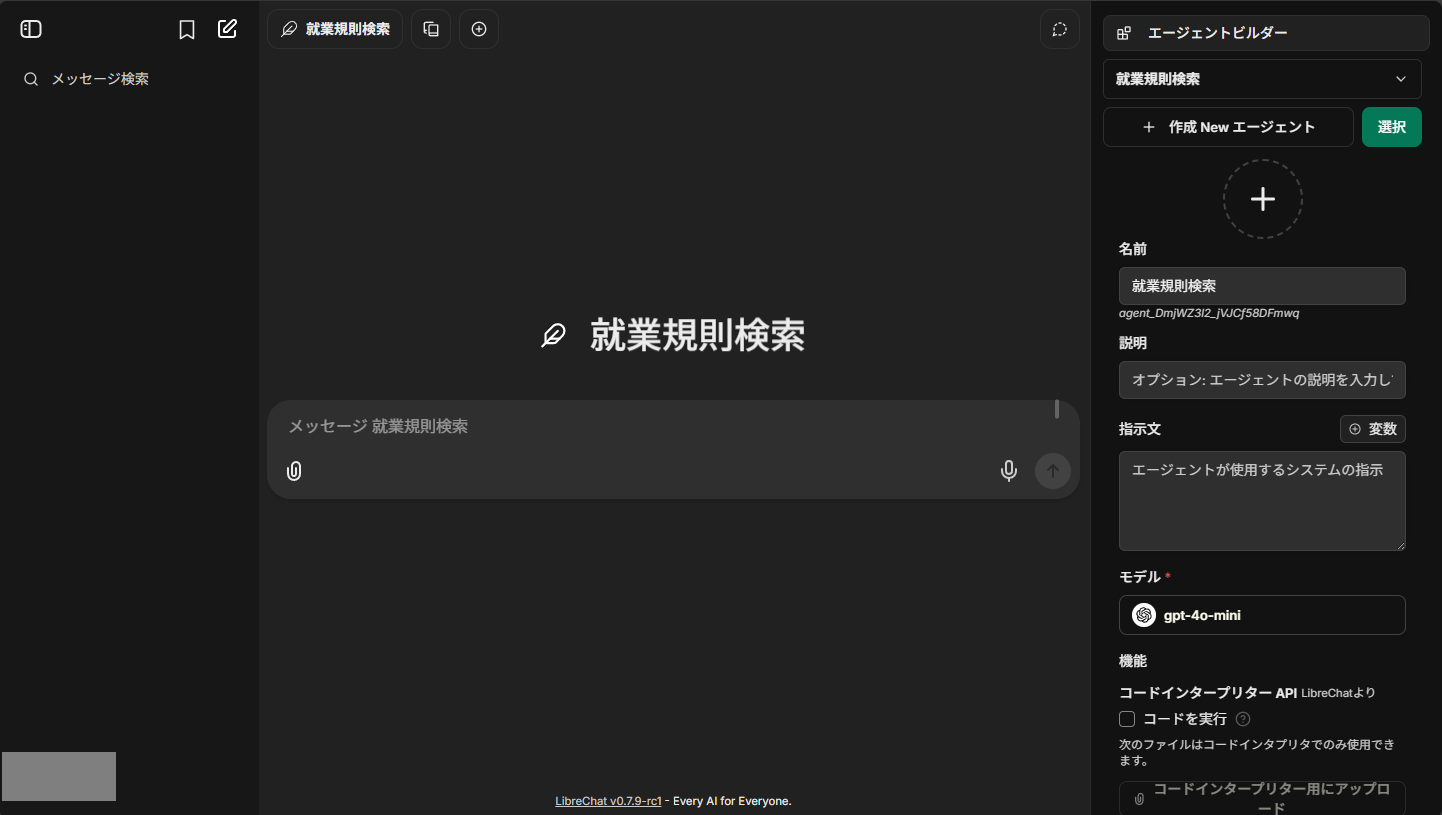
これで準備完了です!
テストしてみました。
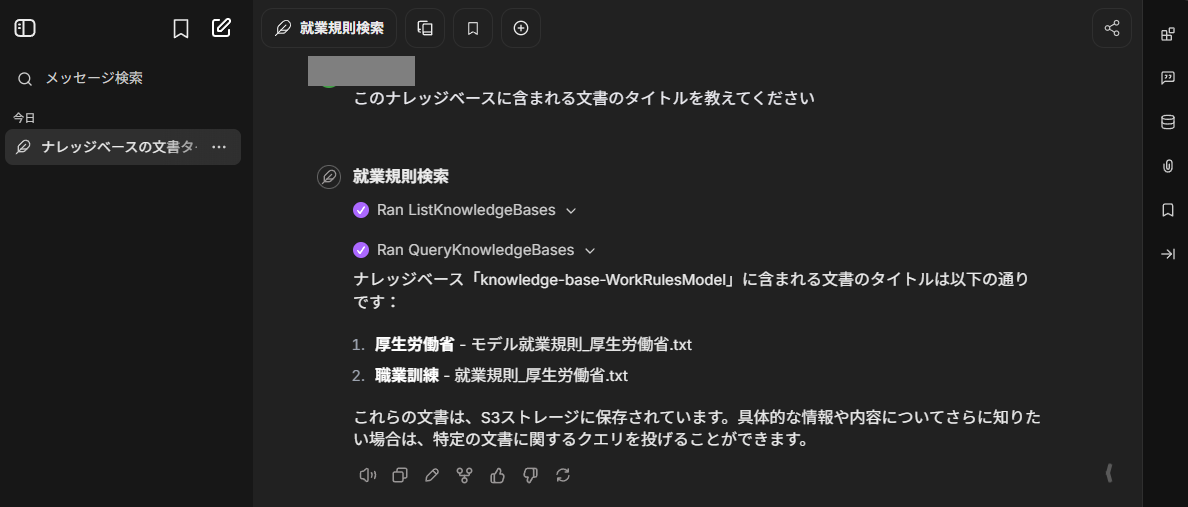
ナレッジベースのデータが読み込まれているかの確認も含め以下の質問をしました。
- このナレッジベースに含まれる文章のタイトルを教えてください
ちゃんと確認できてますね。
おわりに
本記事では、LibreChatとAmazon Bedrock ナレッジベースを連携させ、社内ドキュメントを検索できる環境を構築しました。
今回の例では就業規則を対象にしましたが、FAQや設計資料などを登録すれば、より実務的な検索エージェントとして活用できます。
社内ナレッジを効率的に引き出す手段のひとつとして、ぜひ試してみてください。
それではまた 👋
