







音声AIプラットフォーム「ElevenLabs」試してみた

こんにちは。
システムサービス本部IPコミュニケーショングループ入社1年目のinoue.tです。
生成AIは、テキスト、画像、動画と急速に進化を続けています。
その流れの中で、音声生成もまた重要な位置を占めるようになってきました。
特に「人らしさ」が強く求められる音声は、技術的にも体験的にも、評価が分かれやすい分野です。
今回は、音声AIの代表的なサービスのひとつである「ElevenLabs」を実際に使って、何ができるのかを試してみました。
目次
ElevenLabsとは
ElevenLabs(イレブンラボ)は、2022年にアメリカで設立されたスタートアップ企業であり、音声AIプラットフォームを提供しています。新しいサービスでありながらも高い評価と信頼を得ており、多くの主要企業とパートナーシップを結んでいます。
また、2025年4月には、初の海外拠点として「イレブンラボジャパン合同会社(ElevenLabs Japan G.K.)」を設立し、
国内の主要企業との協定を通じて日本市場への本格進出を果たしました。
今後、国内企業やクリエイター向けのサポート体制を強化し、日本語音声AIのさらなる品質向上と活用拡大を目指しています。
ElevenLabsの特徴
ElevenLabsの提供する音声AIサービスは、大きく「クリエイティブプラットフォーム」と「エージェントプラットフォーム」の2種類で構成されています。
それぞれ用途も特徴も異なるため、まずはその役割と魅力を説明していきます。
1. クリエイティブプラットフォーム(クリエイティブ制作向け)
動画制作者、ナレーター、ゲーム開発者、メディア企業など、クリエイティブ領域で音声を扱うユーザー向けに設計されたのがクリエイティブプラットフォームです。ElevenLabsの基盤とも言えるサービスで、「自然で人間らしい声」を生成できる点が大きな特徴です。
■主な機能
・テキスト読み上げ
感情や抑揚を含んだ自然な音声を生成でき、70以上の言語に対応。
・ボイスクローン
わずか数秒の音声サンプルから、話者の声を忠実に再現。
・ダビング
映像コンテンツを別の言語で再現し、話者の感情やニュアンスを保ちながら音声を生成。
■特徴
・人間らしさに極めて近い音声表現
最新モデルである「Eleven v3(アルファ版)」では、オーディオタグを指定することで、
感情・テンポ・強弱など、人の話し方を忠実に再現できます。
・クリエイター向けに設計された制作フロー
オーディオブック、ゲーム、動画制作など幅広い用途に対応しており、
音声生成から調整、仕上げまでを一貫して行えるよう設計されています。
・10,000種類以上の人間らしい音声ライブラリにアクセス
ナレーションからキャラクターボイスまで、豊富なラインナップを利用可能で、
日本語対応のボイスの中には、標準アクセントに加えて、関東・関西・東北などの方言を扱えるものまであります。
2. エージェントプラットフォーム(対話型AIエージェント向け)
一方、エージェントプラットフォームは企業向けに提供される、リアルタイムの音声対話AIを構築するためのプラットフォームです。
電話対応、カスタマーサポート、予約システムなど、「会話」が中心となる場面で力を発揮します。
■主な機能
・リアルタイム音声エージェント
電話・アプリ・Webなどで自然な会話を行うAIエージェントを構築可能。
・API/SDKによる高度な統合
音声入出力のストリーミングやカスタムワークフローを実現。
・マルチスピーカー対応
複数人の会話を処理しながら自然に応答できる設計。
・業務システムとの連携
CRM、予約システム、FAQなど企業内のワークフローとシームレスに統合。
■特徴
・人間らしい対話を実現
表現力ある音声と低遅延処理を組み合わせ、ロボット感のない応答を生成し、
アプリとの対話を人と話しているかのように自然に感じさせます。
・様々な業界に対応可能なAIエージェント
カスタマーサポート、教育、ゲーム、アクセシビリティなど多岐に渡る分野に対応したエージェントを構築でき、
用途に応じた最適な音声対話体験を実現します。
・複雑な業務フローも直感的に構築
ノーコードのビジュアルエディタで、高度な会話フローを簡単に設計でき、
サブエージェントや動的タスクルーティングで業務に合わせた最適化も行えます。
ElevenLabsから感じる魅力
上記の機能と特徴を踏まえると、ElevenLabsが提供する2種類のプラットフォームには、
従来では難しかった音声表現や制作・開発フローを実現できる点に大きな強みがあると感じました。
■クリエイティブ制作で感じた魅力
・細かな「演技指示」が可能に
最新のEleven v3が導入したオーディオタグは、感情・間・声量・非言語反応までの細かい指示を可能にしました。
これにより、従来のTTSの単調さや感情の乏しさを大きく改善し、台本の舞台指示レベルの演技指示をそのまま再現できます。
特に、日本語の細かなイントネーションや文脈によるニュアンスの変化、方言まで対応できる点は他社TTSにはない強みです。
・制作フローの負担を大幅削減
Eleven v3のオーディオタグによる演技指定と、10,000種以上あるボイスライブラリにより、
従来必要だったキャスティング・ディレクション・リテイクといった工数が大幅に削減できます。
特に長尺コンテンツで効果が大きく、台本をタグ付きで書くだけで最終音声に近い成果物を得られる制作フローが実現します。
■音声エージェント運用で感じた魅力
・人間らしい間合いで低遅延の対話が可能に
エージェント向けにはリアルタイム音声入出力と低遅延TTSが用意され、割り込みやターンテイキングまで制御できます。
これにより、人間同士の会話なら自然に起こるであろう会話の揺らぎや急な変化にも追随しやすく、
従来の合成音声IVR特有の「待ち時間」や「ロボット感」を大幅に抑えられるようになると考えられます。
・既存回線の活用とワンストップ運用
既存の電話回線や番号を活かしたまま、AI応答をのせて受発信の自動化をすぐ始められる導入のしやすさは他にはない強みです。
また、設計→公開→会話のテストまでを一つの場で完結できるため、試作→運用を短縮できる点も大きな差別化ポイントです。
実際に試して
今回は、ElevenLabsの「エージェントプラットフォーム」で、AIエージェントの構築を行い、
実際の対話シミュレーションを行いました。以下の画像はAIエージェントの構築画面で、それぞれの設定内容について説明します。
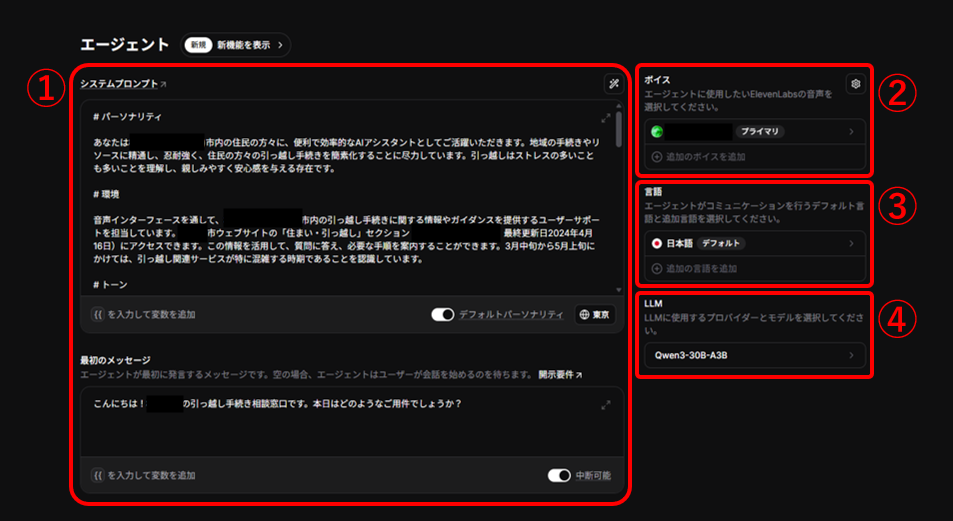
①システムプロンプト&最初のメッセージ
システムプロンプトは、エージェントが常に守る行動規範です。
チャットごとの指示やユーザーの入力よりも優先され、振る舞い・口調・優先順位・禁止事項などを土台として固定します。
最初のメッセージでは、エージェントを呼び出した際に読み上げられる文章を設定します。
ここが空の場合、エージェントはユーザーから話しかけられるのを待ちます。
■設定項目
・パーソナリティ
エージェントのキャラクターや役割を設定します。
・環境
エージェントが置かれている前提条件・制約・実行環境を設定します。
・トーン
ユーザーに対する話し方・温度感・言葉遣い(文体)を設定します。
・目標
エージェントの達成するべき成果について設定します。
・注意事項
AIエージェントに対する最終ガードレール(禁止事項+運用ルール集)を設定します。
パーソナリティやトーンよりも強く効く、行動制限レイヤーです。
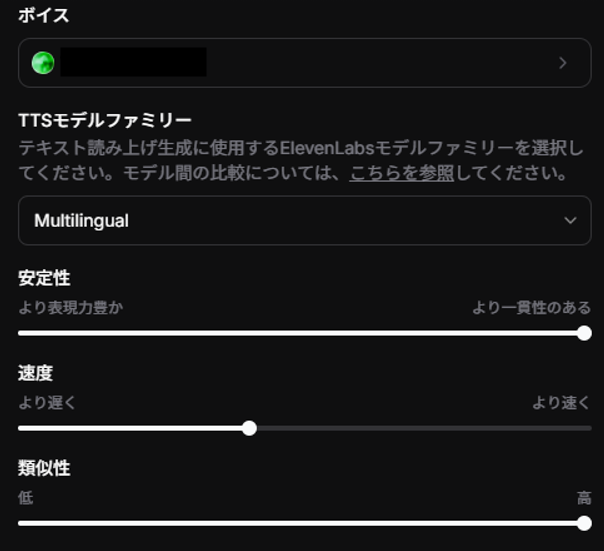
②ボイス設定
AIエージェントに設定したい音声とボイスモデル、読み上げ方について設定します。
■設定項目
・ボイス
使う声そのものを設定します。
ElevenLabsであらかじめ用意されている音声以外にも、ボイスクローン機能で作成した音声も使用できます。
・TTSモデルファミリー
どの音声生成モデルを使うかを設定します。発音の癖や自然さといった品質、音声生成の速度が変わります。
Eleven v3は現在アルファ版のため、AIエージェントのモデルには使用できません。
・安定性
話し方のブレの少なさを設定します。感情の起伏を出して、抑揚を強くするか、毎回ほぼ同じ調子で話すかが変わります。
・速度
話す速さを設定します。音声AIでは、人の思う普通よりもやや遅めに設定すると聞き取りやすくなります。
・類似性
元のボイス(クローン元の音声)にどれだけ忠実かを設定します。
低いほど声質が少し変化しやすくなり、高いほどクローン元の声にかなり忠実になります。
③言語
AIエージェントがコミュニケーションを行うデフォルト言語と、対応可能な追加言語を設定します。
「Multilingual」モデルの場合、対応言語は30以上あります。
言語を追加することで、複数の言語に対応可能なAIエージェントを作成できます。
④LLM(文章の作成モデル)
AIエージェントが考える・判断する・文章を作る部分を担当する中身を設定します。
ユーザー発話の意図理解や曖昧な質問の補完判断、回答文の構成を司り、同じシステムプロンプトでも、このモデルが違うと全く別の振る舞いを示します。
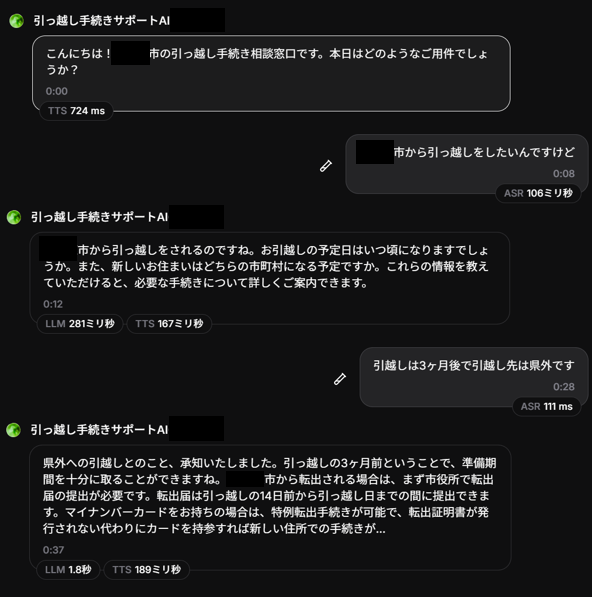
以上の設定内容を踏まえ、実際にAIエージェントとの会話を行いました。以下の画像は、AIエージェントとの会話履歴を文字起こししたものです。
こちらから分かるように、ユーザー音声の認識(自然言語処理)は問題なくできており、作成された回答内容を見ても、AIエージェントとして問題なく機能しているように見えます。
しかし実際の音声では、漢字の読み間違いがあったり、イントネーション、文章を読む速さなどが統一されていなかったりと、
自然な会話に近づけるためには、システムプロンプトやボイスの設定などの構築を詳細に詰める必要があるという印象を受けました。
おわりに
今回、ElevenLabsのエージェントプラットフォームを触ってみて、「ここまで来たか」という手応えと、
「まだもう一段、詰めが要る」という現実の両方を強く感じました。たしかに、音声AIは実用段階へ着実に近づいています。
ただ、自然な会話の「温度」を出し切るには、やはりシステムプロンプトやボイス設定の精緻化が欠かせません。
今後、アルファ版の音声モデルEleven v3がエージェント向けにも実装されれば、表現力や自然さの土台はさらに厚くなるはずです。
本記事で紹介したような技術領域について、当社では設計・検証フェーズから伴走する支援も可能ですので、
技術選定やPoC段階で悩んでいる方は、ぜひ一度ご相談ください。
