







【ローカル最小コストで作る】LangChain + Chroma + FastEmbed + OpenAI の RAG チャット

はじめに
みなさま、こんにちは。
クラウドソリューション第2グループ、入社3年目のkugishimakです。
社内ドキュメントをChatGPTのように検索して回答してくれたら便利ですよね。
その要望は、RAG(Retrieval-Augmented Generation)を使えば実現できます。
今回は以下の条件でRAGを構築していきます。
- ローカルで動く
- 重い環境構築なし
- 低コスト
「とりあえずRAGを動かして理解したい人」向けに
RAGチャットの構築方法を解説します。
目次
使用するライブラリ・ツール
今回使用する主なツールは以下です。
それぞれ簡単に説明します。
| ツール | 役割 |
|---|---|
| LangChain | LLMアプリ開発フレームワーク LLMを使ったアプリケーションを作るためのフレームワークです。 RAGのような処理では、検索・プロンプト作成・LLM呼び出し・出力整形など、 複数の処理を組み合わせる必要があります。 LangChainを使うことで、これらをパイプラインとして簡単に構築できます。 |
| Chroma | ベクトルデータベース RAGでは、文章検索のためにベクトルデータベース(ベクトルDB)を使用します。 通常の検索はキーワード一致が一般的ですが、 ベクトル検索では「意味的に近い文章」を見つけることができます。 学習する文章をベクトル化し、その情報を保存するためにChromaを使用します。 |
| FastEmbed | 高速な埋め込みモデル RAGでは、文章を「数値ベクトル」に変換する必要があります。 この処理をEmbedding(埋め込み)と呼びます。 FastEmbedは軽量かつ高速で、小規模なRAG構築に向いています。 |
| OpenAI API | 回答生成用LLM 回答生成にはOpenAIのLLMを使用します。 本記事では gpt-4o-mini を使用します。 APIの利用には料金がかかるため、事前にクレジットを追加しておきましょう。 |
| FastAPI | Web API構築フレームワーク PythonでWeb APIを構築できるフレームワークです。 RAGの処理をAPIとして公開し、ブラウザから呼び出せるようにします。 |
構築までの流れ
RAGチャットは大きく分けて、2段階で構築します。
- データをベクトル化する(インデックス作成)
- 質問 → 検索 → LLMによる回答生成
全体の流れは以下の通りです。
ドキュメント(今回はtxtファイル)
↓
文章を分割(チャンク化)
↓
Embedding(ベクトル化)
↓
ChromaDBに保存
↓
質問
↓
類似文章を検索
↓
LLMが回答生成
構築手順
それでは実際に構築していきます。
コードの全文はこの記事の一番最後に記載していますので参考にしてください。
ファイル構成は以下の通りです。
project/
├── app.py # Web API(ブラウザから呼び出し)
├── ingest.py # データを学習(ベクトル化して保存)
├── rag_chat.py # CLIで動作するRAGチャット
├── documents/ # 学習させるテキスト
│ ├── sample1.txt
│ └── sample2.txt
├── chroma_db/ # ベクトルDB(自動生成)
├── static/ # フロント(任意)
│ └── index.html
└── .env # APIキー
documentsフォルダの中に、読み込みたい.txtファイルを配置してください。
今回は sample1.txt と sample2.txt を用意しています。
中身は以下の通りです。
【sample1.txt】
この文書はRAGのテスト用です。
LangChainとFastEmbedで検索されます。
OpenAI APIで回答を生成します。
【sample2.txt】
もうひとつのテキストです。RAGの挙動確認に使います。
CLOUD FLAGについて
経験豊富なクラウドコンサルタントが、御社のクラウド導入をサポートいたします。
CLOUD FLAG(クラウドフラッグ)は、株式会社アイソルートが提供する
クラウド活用トータル支援ソリューションです。
多くのお客様のDX推進、AI活用、クラウド活用、システム移行を支援しています。
御社の現状の課題や将来像、「こうなったらいいな」という理想をぜひお聞かせください。
導入のご相談から、実際の移行・導入作業、保守・運用まで、
一貫してサポートいたします。
.env にはOpenAI APIキーを記載しておきます。
OPENAI_API_KEY=sk-proj-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
また、chroma_db/ は ingest.py を実行すると自動生成されます。
フォルダおよび中のファイルは手動で作成する必要はありません。
(ingest.py)
1. ドキュメントの読み込み
from langchain_community.document_loaders import DirectoryLoader, TextLoader
loader = DirectoryLoader(
"documents",
glob="*.txt",
loader_cls=TextLoader,
)
docs = loader.load()
documentsフォルダに配置した .txt ファイルをすべて読み込みます。
2. テキストをチャンク分割する
LLMは長い文章をそのまま扱うのが苦手です。
そのため、文章を小さな単位(チャンク)に分割します。
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
)
chunk_size:1チャンクあたりの最大文字数chunk_overlap:前後のチャンクで重複させる文字数
つまり「500文字ごとに分割しつつ、100文字は重ねる」という意味です。
重なりを持たせることで、文脈の分断を防ぐ効果があります。
3. ベクトル化(Embedding)
次に、文章をベクトル化します。
from langchain_community.embeddings import FastEmbedEmbeddings
embedding = FastEmbedEmbeddings()
これにより文章は数値ベクトルに変換され、意味的な距離で検索できるようになります。
4. ChromaDBへ保存
ベクトルデータをChromaに保存します。
from langchain_community.vectorstores import Chroma
db = Chroma.from_documents(
chunks,
embedding,
persist_directory="chroma_db",
)
これにより chroma_db フォルダが自動生成され、
検索用のデータベースが作成されます。
(rag_chat.py)
1. ベクトルDBの読み込み
ingest.py で作成したベクトルDBを読み込みます。
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import FastEmbedEmbeddings
embedding = FastEmbedEmbeddings()
db = Chroma(
persist_directory="chroma_db",
embedding_function=embedding
)
ここでは、保存しておいた chroma_db を読み込んでいます。
注意:
ingest.py と同じEmbeddingを使用する必要があります。
異なるEmbeddingを使うと、検索結果が正しく取得できなくなります。
2. Retrieverの作成(検索機能)
次に、検索機能(Retriever)を作成します。
retriever = db.as_retriever(search_kwargs={"k": 4})
質問に対して関連性の高い文章を取得します。
k=4 は「上位4件取得する」という意味です。
一般的には 3〜5 件程度に設定することが多いです。
3. LLM(OpenAI)の準備
回答を生成するAIを準備します。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0.2,
)
今回は temperature=0.2 に設定しています。
- 低い:安定した回答(正確性が高い)
- 高い:創造的な回答(雑談向き)
4. プロンプトの作成
AIにどのように回答させるかを定義します。
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
(
"system",
"あなたは有能なアシスタントです。以下のコンテキストに基づいて回答してください。\n\n{context}"
),
("human", "{question}")
])
{context} には検索結果の文章、
{question} にはユーザーの質問が入ります。
5. LCELでRAGの流れを構築
ここがRAGの本体です。
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
rag_chain = (
RunnableParallel(
context=retriever,
question=RunnablePassthrough()
)
| prompt
| llm
| StrOutputParser()
)
この処理では以下の流れをまとめて実行しています。
- ユーザーの質問を受け取る
- 関連する文章を検索(Retriever)
- プロンプトに埋め込む
- OpenAIで回答生成
- 文字列として返す
6. 回答の生成
answer = rag_chain.invoke("質問内容")
print(answer)
「質問 → 検索 → 回答生成 → 出力」の一連の処理が実行されます。
(app.py)
1. ライブラリの読み込み
まずは必要なライブラリを読み込みます。
from fastapi import FastAPI, HTTPException
from fastapi.staticfiles import StaticFiles
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
Web APIを作成するための準備を行います。
- FastAPI:Webサーバ
- BaseModel:リクエストの型定義
- CORS:ブラウザからのアクセス制御
2. FastAPIアプリの作成
app = FastAPI(title="LangChain RAG Chat")
3. CORS設定(ブラウザからのアクセス許可)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
本来はアクセス制限を設定できますが、今回は検証用のためすべて許可しています。
4. 静的ファイルの配信(フロント用)
app.mount("/static", StaticFiles(directory="static"), name="static")
HTMLやJavaScriptファイルを配信し、/static/index.html にアクセスできるようにします。
5. リクエストの型定義
class ChatRequest(BaseModel):
question: str
APIで受け取るJSONの形式を定義しています。
6. RAGチェーンの準備
RAG_CHAIN, RETRIEVER = build_rag_chain()
サーバ起動時にRAGの処理を生成します。
毎回生成すると処理が重いため、初回のみ実行する構成にしています。
7. APIエンドポイントの作成
@app.post("/api/chat")
def chat(req: ChatRequest):
/api/chat にPOSTリクエストを送ることで、この処理が実行されます。
8. RAGの実行
answer = RAG_CHAIN.invoke(q)
return {
"answer": answer,
"sources": sources
}
回答と参照元をJSON形式で返します。
9. エラーハンドリング(補足)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
エラーが発生した場合は、HTTPステータス500として返却します。
OpenAI APIの制限などもここでハンドリングされます。
動作確認
実際に動作させると、以下のように回答を得ることができます。
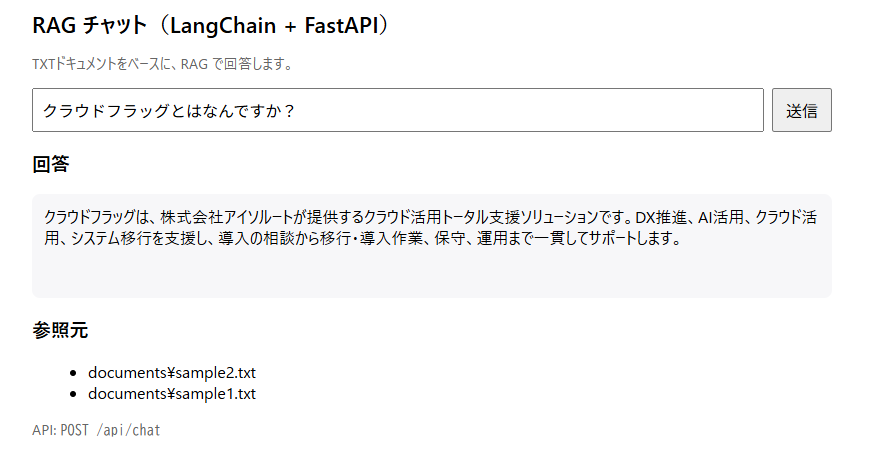
コード全文
ここまで紹介した内容をまとめたコード全文を以下に掲載します。
実際に動かす際は、ファイル構成に沿ってそれぞれ配置してください。
ingest.py
# =========================================
# ingest.py
# =========================================
# やっていること:
# 1. documents/ フォルダから .txt をすべて読み込む
# 2. 長い文章を 500文字ごとに分割(100文字重複)
# 3. 文章をベクトル化(意味で比較できる形式へ変換)
# 4. ChromaDB に保存(後から高速検索できるようにする)
from dotenv import load_dotenv
import os
# LangChain関連
from langchain_community.document_loaders import DirectoryLoader, TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import FastEmbedEmbeddings
from langchain_community.vectorstores import Chroma
# 環境変数読み込み
load_dotenv()
# ディレクトリ設定
DOCS_DIR = "documents" # 学習データ(.txt置き場)
PERSIST_DIR = "chroma_db" # ベクトルDBの保存先
def main():
# 1. documents/*.txt をまとめて読み込む
loader = DirectoryLoader(
DOCS_DIR,
glob="*.txt",
loader_cls=TextLoader,
loader_kwargs={
"encoding": "utf-8",
"autodetect_encoding": True,
},
show_progress=True,
use_multithreading=True,
)
docs = loader.load()
if not docs:
print("documents/*.txt が見つかりません。TXTを追加してください。")
return
# 2. チャンク分割(検索しやすい粒度にする)
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
separators=["\n\n", "\n", "。", "、", " ", ""],
)
chunks = splitter.split_documents(docs)
# 3. ベクトル化(Embedding)
embedding = FastEmbedEmbeddings()
# 4. ChromaDBへ保存
os.makedirs(PERSIST_DIR, exist_ok=True)
db = Chroma.from_documents(
chunks,
embedding,
persist_directory=PERSIST_DIR,
)
db.persist()
print(f"ベクトルDB作成完了: {PERSIST_DIR}")
if __name__ == "__main__":
main()
rag_chat.py
# =========================================
# rag_chat.py
# =========================================
# やっていること:
# 1. ingest.py で作成した ChromaDB を読み込む
# 2. 質問を受け取る
# 3. 関連する文章を検索(上位k件)
# 4. OpenAIにコンテキストとして渡して回答生成
# 5. 参照元も表示
import os
from dotenv import load_dotenv
# ベクトルDB関連
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import FastEmbedEmbeddings
# LLM
from langchain_openai import ChatOpenAI
# LCEL関連
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
PERSIST_DIR = "chroma_db"
# ------------------------------
# 検索結果を文字列に整形
# ------------------------------
def format_docs(docs):
parts = []
for i, d in enumerate(docs, 1):
meta = d.metadata or {}
src = meta.get("source", "unknown")
parts.append(f"[{i}] source={src}\n{d.page_content}")
return "\n\n".join(parts)
def main():
# 環境変数読み込み
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise RuntimeError("OPENAI_API_KEY が設定されていません")
# 1. ChromaDBの読み込み(ingest.pyと同じEmbeddingを使うこと)
embedding = FastEmbedEmbeddings()
db = Chroma(
persist_directory=PERSIST_DIR,
embedding_function=embedding,
)
retriever = db.as_retriever(search_kwargs={"k": 4})
# 2. LLMの準備
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0.2,
timeout=60,
)
# 3. プロンプト定義
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは有能なアシスタントです。以下のコンテキストに基づいて、"
"事実ベースで簡潔に回答してください。わからない場合はそう伝えてください。\n\n"
"{context}",
),
("human", "{question}"),
]
)
# 4. RAGチェーン構築(検索→整形→生成)
rag_chain = (
RunnableParallel(
context=retriever | format_docs,
question=RunnablePassthrough(),
)
| prompt
| llm
| StrOutputParser()
)
if __name__ == "__main__":
main()
app.py
# """
# FastAPI を使って RAG を Web API 化する
# """
import os
from typing import Dict, Any
from dotenv import load_dotenv
from fastapi import FastAPI, HTTPException
from fastapi.staticfiles import StaticFiles
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import FastEmbedEmbeddings
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
PERSIST_DIR = "chroma_db"
# =========================
# ドキュメント整形
# =========================
def format_docs(docs):
parts = []
for i, d in enumerate(docs, 1):
src = d.metadata.get("source", "unknown")
parts.append(f"[{i}] source={src}\n{d.page_content}")
return "\n\n".join(parts)
# =========================
# RAGチェーン構築
# =========================
def build_rag_chain():
load_dotenv()
if not os.getenv("OPENAI_API_KEY"):
raise RuntimeError("OPENAI_API_KEY が未設定です")
embedding = FastEmbedEmbeddings()
db = Chroma(persist_directory=PERSIST_DIR, embedding_function=embedding)
retriever = db.as_retriever(search_kwargs={"k": 4})
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0.2,
timeout=60,
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"以下のコンテキストに基づいて回答してください。\n\n{context}",
),
("human", "{question}"),
]
)
rag_chain = (
RunnableParallel(
context=retriever | format_docs,
question=RunnablePassthrough(),
)
| prompt
| llm
| StrOutputParser()
)
return rag_chain, retriever
# =========================
# FastAPI
# =========================
app = FastAPI(title="RAG Chat API")
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
app.mount("/static", StaticFiles(directory="static"), name="static")
RAG_CHAIN, RETRIEVER = build_rag_chain()
# =========================
# リクエスト定義
# =========================
class ChatRequest(BaseModel):
question: str
# =========================
# API
# =========================
@app.post("/api/chat")
def chat(req: ChatRequest) -> Dict[str, Any]:
q = (req.question or "").strip()
if not q:
raise HTTPException(status_code=400, detail="question が空です")
try:
answer = RAG_CHAIN.invoke(q)
docs = RETRIEVER.invoke(q)
sources = [d.metadata.get("source", "unknown") for d in docs]
return {
"answer": answer,
"sources": sources,
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e)) from e
@app.get("/")
def root():
return {"message": "Open /static/index.html"}
おわりに
本記事では、LangChain・Chroma・FastEmbed・OpenAIを組み合わせた
ローカルRAGチャットの構築方法を紹介しました。
今後さらに発展させる場合は、PDF対応や社内ナレッジ連携、UI改善などを行うことで、
より実用的なシステムに拡張できます。
RAGは生成AI活用の中でも非常に重要な技術です。
ぜひ実際に構築して動かしてみてください。
それではまた 👋
