







Azure AI Search で実装する Agentic RAG (エージェント検索) の仕組みと実践

生成AIの活用が急速に進む中、単なるチャットボットを超えた「AIエージェント」への注目が集まっています。
AIエージェントが自律的にタスクをこなすためには、正確な知識へのアクセスが不可欠です。そこで鍵となるのが、Azure AI Search を活用した「エージェント検索」です。
本記事では、Azure AI Search がどのようにしてAIエージェントの「頭脳」や「記憶」となり得るのか、その概要から具体的な実装イメージまでを解説します。
RAG(Retrieval-Augmented Generation)をさらに進化させたいエンジニアの方々の一助になれば幸いです。
目次
はじめに
こんにちは。クラウドソリューショングループのwatanabe.tです。
この記事は アイソルート Advent Calendar 2025 の2日目の記事です。
最近、LLM(大規模言語モデル)界隈では「エージェント(Agent)」という言葉をよく耳にするようになりました。
ユーザーの指示待ちではなく、AI自らが考え、ツールを使い、目的を達成する自律型AIのことです。
しかし、どれほど優秀なエージェントでも、社内規定や製品マニュアルといった「独自の知識」を持っていなければ、ビジネスの現場では役に立ちません。
そこで今回は、Microsoft Azure が提供する検索サービス「Azure AI Search」を使って、エージェントに知識を与える方法についてご紹介します。
Azure AI Search とは
Azure AI Search(旧称:Azure Cognitive Search)は、AIを活用したクラウド検索サービスです。
従来のキーワード検索に加え、以下のような高度な機能を提供しています。
- ベクトル検索 (Vector Search): 文章の意味(セマンティクス)を数値化して検索するため、「表記ゆれ」や「類義語」に強い。
- ハイブリッド検索 (Hybrid Search): キーワード検索とベクトル検索を組み合わせ、より良い精度を実現する。
- セマンティックランカー (Semantic Ranker): Microsoft Bing の技術を応用し、検索結果を文脈に合わせて並べ替える。
これらの機能により、Azure AI Search は単なる検索エンジンとしてだけでなく、LLMにコンテキストを提供する「RAGのバックエンド」としてデファクトスタンダードの地位を確立しています。
エージェント検索(Agentic RAG)の仕組み
従来のRAGは、「ユーザーの質問に関連するドキュメントを検索し、それをLLMに渡して回答させる」という直線的なフローでした。
しかし、「エージェント検索」では、AIエージェントがより能動的に検索を利用します。
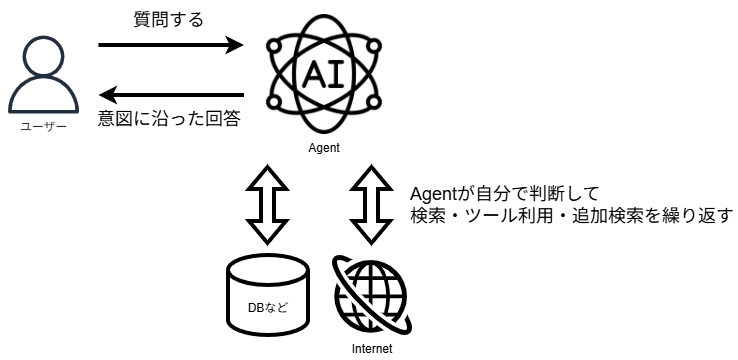
例えば、「A社の製品XとB社の製品Yの仕様を比較して」という指示があった場合、エージェントは以下のように動きます。
- まず「A社 製品X 仕様」で検索を実行する。
- 情報が足りなければ、検索クエリを変えて「製品X バッテリー容量」などで再検索する。
- 次に「B社 製品Y 仕様」で検索を実行する。
- 集めた情報を統合して、比較表を作成して回答する。
このように、Azure AI Search を「ツール」としてエージェントに持たせることで、複雑な質問に対しても自律的に情報を収集・解決できるようになります。
簡単な使い方の説明
では、実際に Azure AI Search の新機能「ナレッジエージェント」を使って、コーディングなしでエージェント検索を試してみましょう。
今回は、Azure AI Search に標準で用意されているサンプルデータ hotels-sample-index を利用します。
1. インデックスの準備
まず、 クイック スタート: Azure portal で検索インデックスを作成する – Azure AI Search を参考に、Azure AI Searchにデータをインポートします。
このあと設定するナレッジソースの作成には、セマンティック構成が必要になるので、忘れずに設定しておきましょう。
なお、以前はサンプルデータの取り込みはワンボタンだったのですが、いまは非推奨となってしまい、自分でGitHubにアップロードされているJSONファイルをインポートする方式になってしまっていました。
このとき、GitHub上のJSONデータはそのままだとJSON配列とみなされないため、角括弧([])でデータを囲うように修正してあげる必要がありました。
また、インデックスのフィールドそれぞれの「フィールドの構成」も手動で定義する必要があり、ちょっと面倒になってしまいました。
2. ナレッジソースの作成
インデックスができたら、左メニューの「エージェント取得」を選択し、「ナレッジソース」を開き、「ナレッジソースの追加」をクリックします。
「検索インデックス」を選択し、先ほど作成したインデックスを選択します。
ここで任意設定項目になっている「ソースデータフィールド」は実際にAIが回答するときに、回答の根拠として表示されるフィールド(ドキュメント名やファイル名など)を設定します。
3. ナレッジベースの作成
最後に、実際に回答をするエージェントを作成します。
設定画面では、エージェントの振る舞いを定義するシステムプロンプトや、検索時のパラメータ(ハイブリッド検索やセマンティックランカーの有効化など)をGUIで設定可能です。
LangChain などのライブラリを使ってコードを書く必要はなく、Azure の画面操作だけで完結するのが大きなメリットです。
4. エージェントのテスト
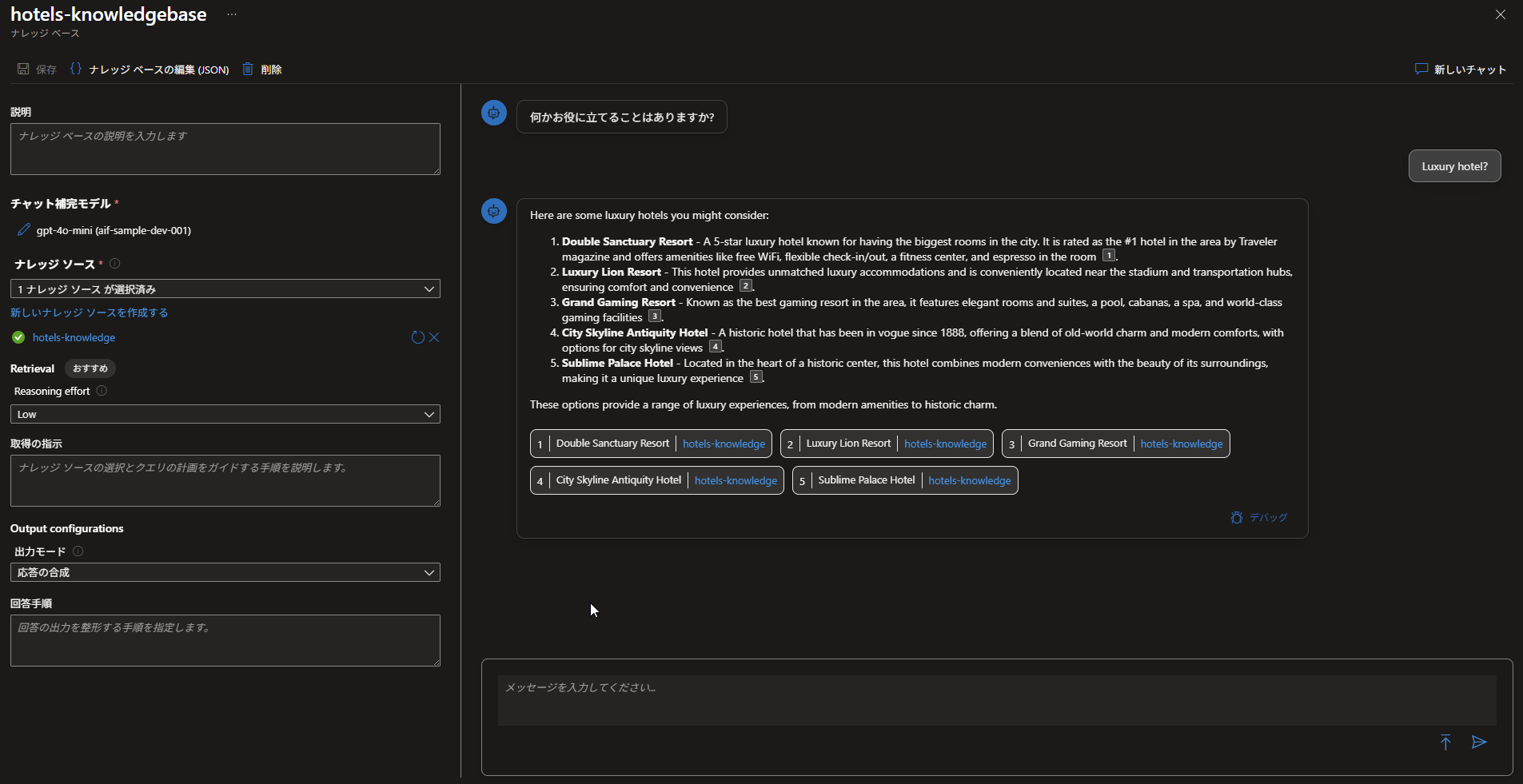
作成が完了すると、テスト用のチャットウィンドウが表示されます。
英語でホテルの情報が格納されているため、「Luxury hotel?」と入力してみましょう。
エージェントが裏側で検索クエリを生成し、インデックスから条件に合うホテルを探し出し、自然な文章で回答してくれるはずです。
おわりに
Azure AI Search は、ベクトル検索やセマンティックランカーといった強力な機能を備えており、AIエージェントの知識源として最適です。
エージェント検索を実装することで、AIはより自律的に、より正確に業務をサポートしてくれるようになります。
株式会社アイソルートでは、Azure AI Search を活用したRAG構築や、AIエージェントの開発支援を行っています。
「社内データをAIに活用させたい」「高度な検索システムを構築したい」といったご要望がありましたら、ぜひお気軽にご相談ください。
オンプレ生成AI 導入支援サービス | CLOUD FLAG
