







【初心者向け】GCPのデータ処理で必須かも!?Dataflowで初めてのパイプライン処理
データ分析基盤の構築方法には色々なものがありますが、
GCP(Google cloud Platform)のサービスを利用しているシステムならば、Cloud Dataflowの利用も検討してはいかがでしょうか。
各種GCPのサービス(Cloud Pub/Sub, BigQuery, Cloud Storageなど)とも連携がしやすく、データ量に応じてスケール可能、と強力なデータ処理パイプラインをクラウド環境上に構築することができます。
本記事では、Dataflowの導入となる説明と、GUIでDataflowを使用してパイプライン処理を実装してみるところまでを書きます。
この記事は アイソルート Advent Calendar 16日目の記事です。
こんにちは。
Google認定、GCPクラウドアーキテクト1)の tomono.t です。
みなさんCloud Dataflow使ってますかーー!!
この記事は使っていない人が対象なので、使っていなくて大丈夫です。
かくいう私もDataflowを業務で触るようになったのはけっこう最近のことで、
とある案件で、「この分析基盤はDataflowを使いましょう!」という話をしてから、少しづつ色々なことを試しています。
Dataflowは他のGCPサービスと親和性が高く、今後GCPを利用したデータ分析基盤構築において、重要度が増してくるのではないかと考えています。
他のGCPサービスと比べると少しとっつきにくそうなイメージを持たれることが多いDataflowですが、Googleが提供するテンプレートを有効活用することで簡単に動作を確認することができます。
この記事ではDataflowを始めるにあたり、その導入となる部分の説明を行います。また、テンプレートを用いてお手軽にDataflowを試してみるということを通し、利便性を感じてもらえればと思っています。
目次
Dataflowって?
Dataflowは何者か。一言でいいますと、
「ApacheBeamで記述されたパイプライン処理を動作させられるプラットフォーム」です。
もっと簡単に、「ApacheBeamを実行できる環境」と言い換えてもいいかと思います。
ApacheBeamとは
![]()
ApacheBeamはパイプライン処理を実現するためのフレームワークです。
パイプライン処理というのは、データの読込、前処理、集計、保存といった一連の処理を行うものです。
これらは大規模なデータを効率よく処理できる、並列処理によって実現されるのが一般的です。
ApacheBeamを利用することで、開発者はパイプラインの環境構築や管理に力を割く必要が少なく、ロジック作成に意識を集中することができます。
また、ApacheBeamはバッチ処理2)とストリーミング処理3)におけるプログラミング的な記述の違いが少ないといった特徴を持ちます。
ApacheBeamは移植性も高く、Dataflowの他にApache Spark, Apache Flinkなど他のプラットフォームで動作させることが可能です。
Dataflowのメリット
ここまで読んでいただいた方はおそらく、こう言うでしょう。
じゃあなんでDataflowがいいんだよ!! 、と
前述の通り、Dataflow自体はApacheBeamを実行できる環境の一つに過ぎないのですが、私の理解では次のようなメリットがあると思っています。
- 動作環境の構築が不要
- オートスケーリング
- 各種GCPのサービスと連携した処理が容易
動作環境の構築が不要
ApacheBeamによって記述された処理をDataflow上で実行すると、記述されたパイプラインの構成に従って環境を自動構築した上で処理を始めてくれます。
基本的には何も考えずとも、動作環境の構築に関してはDataflowがよしなにやってくれるので、その間、私達はコーヒーでも飲んでりゃいいんですね。
オートスケーリング
嬉しいことに、Dataflowはオートスケーリング機能を持っています。
入ってくるストリーミングデータの量が多かったり、負荷がかかってしまうバッチ処理を実行した場合など自動でスケーリングしてくれます4)。
こういった環境周りのことをほとんど考えなくてすむのは非常にありがたいですねー
各種GCPのサービスと連携した処理が容易
ApacheBeamでは、GCPの各種サービスと連携できるSDKがそろっており、各種サービス間の連携が容易にできるようになっています。
ひとまずJavaに限定してしまいますが5)、ApacheBeam SDK for Javaでは以下のようなSDKが用意されているようです。
- Google BigQuery
- Google Cloud Storage
- Google Cloud Pub/Sub
- Google Cloud Bigtable
- Google Cloud Spanner
当然かもしれませんが、JDBCのSDKも用意されており、MySqlなど通常のRDBとも接続できます。
例えば、
- Cloud Strage上にファイルが配置されるのを常に待ち受けておく
- Pub/Subで処理結果のメッセージを送る
- Cloud StorageやBigQueryにデータを配置する前に処理を挟む
などなどできそうですので、アイデアしだいで色々なユースケースに対応できそうです。わくわくしますね!!
また、GCPではなくAWSのサービス(S3, SQS, SNS)とのapiも用意されており、他の様々なデータソースに対応しています。
これはサポートしてるの? Pythonは?という疑問がありましたら、こちらを見ていただくのが良いと思います。
API とリファレンス | Cloud Dataflow | Google Cloud
料金
忘れてはいけない料金についても触れておきましょう。
Dataflowは実行するとGoogle Compute Engineを使用したワーカーが作成されます。
Dataflowの料金は、このワーカーの起動時間に対してかかります。
料金計算の方法は
「確保したCPU数/メモリ量/ディスク使用量」×「時間」
の延べ時間となっています。6)
{ (1CPU料金 × 使用CPU数) + (1GBメモリ料金 × 使用メモリGB) + (1GBストレージ料金 × 使用ストレージGB) } × 時間(h)
Dataflowの料金はバッチ処理2)と、ストリーミング処理3)で異なります。
個人的に計算してみましたが、下の条件
- us-central1のゾーン
- デフォルトのVM設定
- スケールしない処理の実行
- suffle, streaming engineという機能は使わない
- Dataflow以外のサービスはコストに含めない
でざっくりと計算すると記事執筆時点(2018/12)では以下が目安になるかと思います。データ処理用の環境を自前で用意することを考えればかなり安いと思うのですが、いかがでしょうか?
バッチ処理料金
1時間あたり約0.08$
(0.056 * 1) + (0.003557 * 3.75) + (0.000054 * 250)
| バッチワーカー料金 | デフォルト時使用量 | |
| CPU | 0.056$ / 1CPU | 1CPU |
| メモリ | 0.003557$ / 1GB | 3.75GB |
| ストレージ | 0.000054$ / 1GB | 250GB |
ストリーミング処理料金
1時間あたり約0.35$
(0.069 * 4) + (0.003557 * 15) + (0.000054 * 430)
| ストリーミングワーカー料金 | デフォルト時使用量 | |
| CPU | 0.069$ / 1CPU | 4CPU |
| メモリ | 0.003557$ / 1GB | 15GB |
| ストレージ | 0.000054$ / 1GB | 430GB |
注意事項
料金に関しての詳しい情報は必ず本家GCPのサイトで確認してください。
Cloud Dataflow の料金 | Cloud Dataflow ドキュメント | Google Cloud
なお、ストリーミング処理のワーカーを使用する場合、実際には利用しない待ちの時間でもワーカー料金が発生します。
個人で試す場合は使い終わったら忘れずに処理を止めましょう。
GUIでさくっと体験
Dataflowがなんか良さそうなのはわかったけど、ApacheBeamを覚えないといけないの?面倒だなあ…
という面倒くさがり屋さんも多いでしょう。
が、ApacheBeamを覚えなくてもGoogleが提供しているテンプレートを利用することで楽に試すことができます。
Dataflowにはコードをテンプレートとして予めビルドしておき、後からビルド済みのテンプレートに任意のパラメータを渡して実行する機能があります。
また、ビルド済みテンプレートをWebコンソールからGUIで実行できる仕組みがDataflowによって提供されています。
今回はDataflowが標準で提供しているテンプレートの一つを利用してCloud Pub/Subから受け取ったデータをBigQueryに流すということを体験してみましょう。
使用するテンプレート
今回はCloud Pub/Sub to BigQueryテンプレートを利用します。これはBigQueryに投入したいデータをJSON形式でCloud Pub/SubにPublishすると、随時BigQueryに投入されるというものです。Cloud Storageは処理途中の一時ファイルの配置先として使用されるようです。
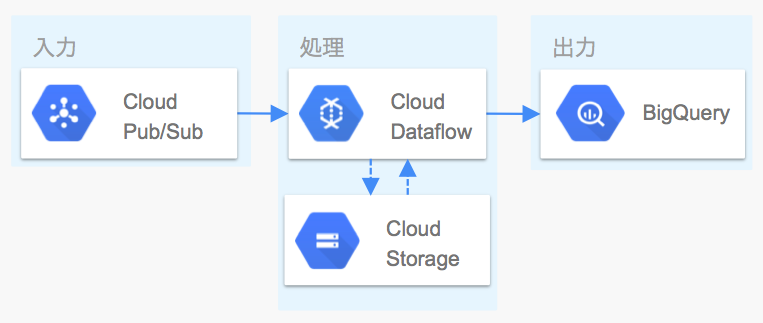
Pub/SubはREST APIで簡単にメッセージが送れますし、Pub/SubとDataflowを介してBigQueryに投入することで、失敗時のリトライ処理や、UDF(ユーザ定義関数)で独自のフィルタリング処理を挟むといったことができます。
なお、今回紹介するPub/Sub to BigQuery以外のテンプレートに関する情報はこちらのリンクを参照してください。
Google-Provided Templates | Cloud Dataflow | Google Cloud
また、Googleが提供するテンプレートに関して解説されている良記事がありますので、こちらを見ていただくのも良いかと思います。
Cloud Dataflow がテンプレートにより気軽に使えるサーバーレスのサービスに進化した話 – google-cloud-jp – Medium
それではDataflowのテンプレートを使ってみましょう!以下の形で進めていきます。
- 事前準備
- Dataflow ジョブ実行
- Pub/Sub へメッセージ送信
- Dataflow ジョブ終了
1. 事前準備
GCPのアカウントは取得している前提で話を進めますので、持っていない方はアカウントの取得をお願いします。
Dataflow
初回使用時はAPIを有効化してください。
GCPのコンソールにアクセスし、メニューからDataflowを選択します。
Dataflowを試すを選択するとチュートリアルが開始しますので、APIを許可するのボタンがでるまで指示通りに進め、APIを許可してください。
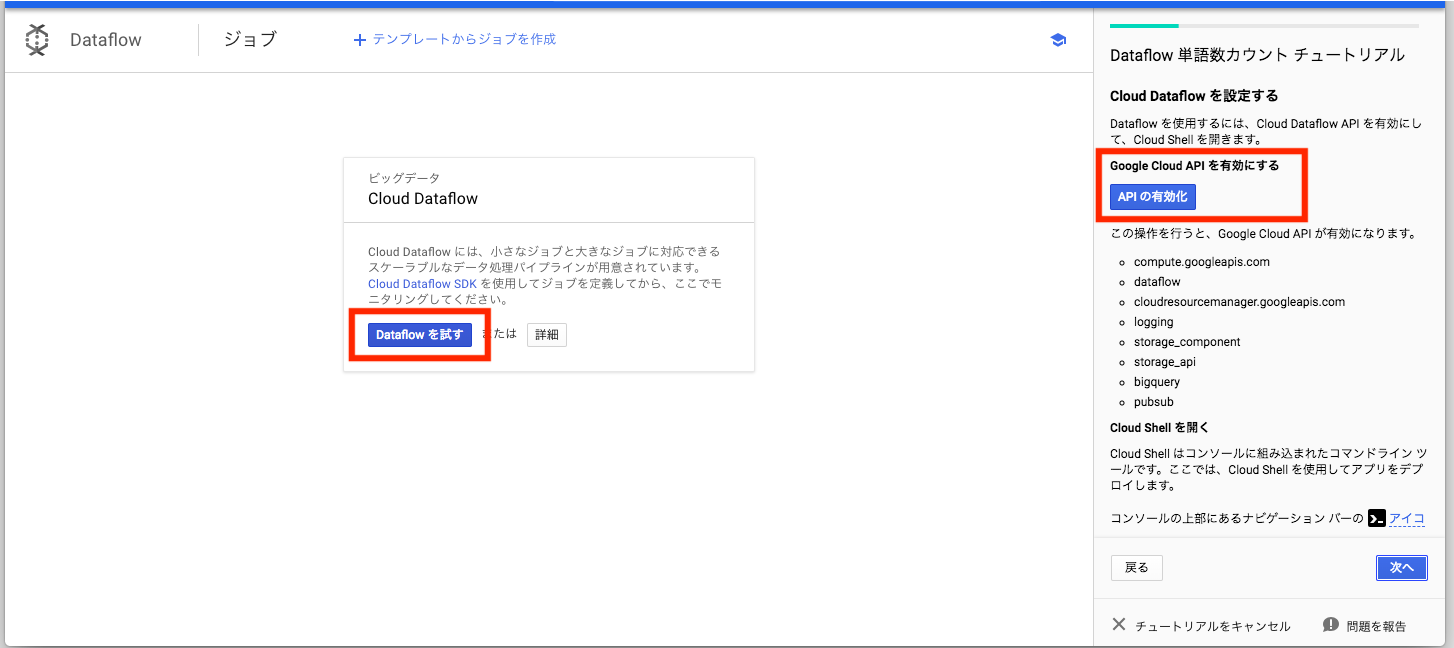
以降のチュートリアルは不要であればキャンセルしていただいて問題ないかと思います。
Cloud Pub/Sub
Pub/Subでトリガとするトピックを作成します。
GCPのWebコンソールで、左上のナビゲーションメニューからPub/Subを選択します。
トピックを作成をクリックし、任意の名前でtopicを作成します。
BigQuery
BigQueryに出力先のテーブルを作成します。インサートしたいテーブルがある方はスキップして良いです。
GCPのWebコンソールで、左上のナビゲーションメニューからBigQueryを選択します。
データセットを作成をクリックし、任意の設定でデータセットを作成してください。
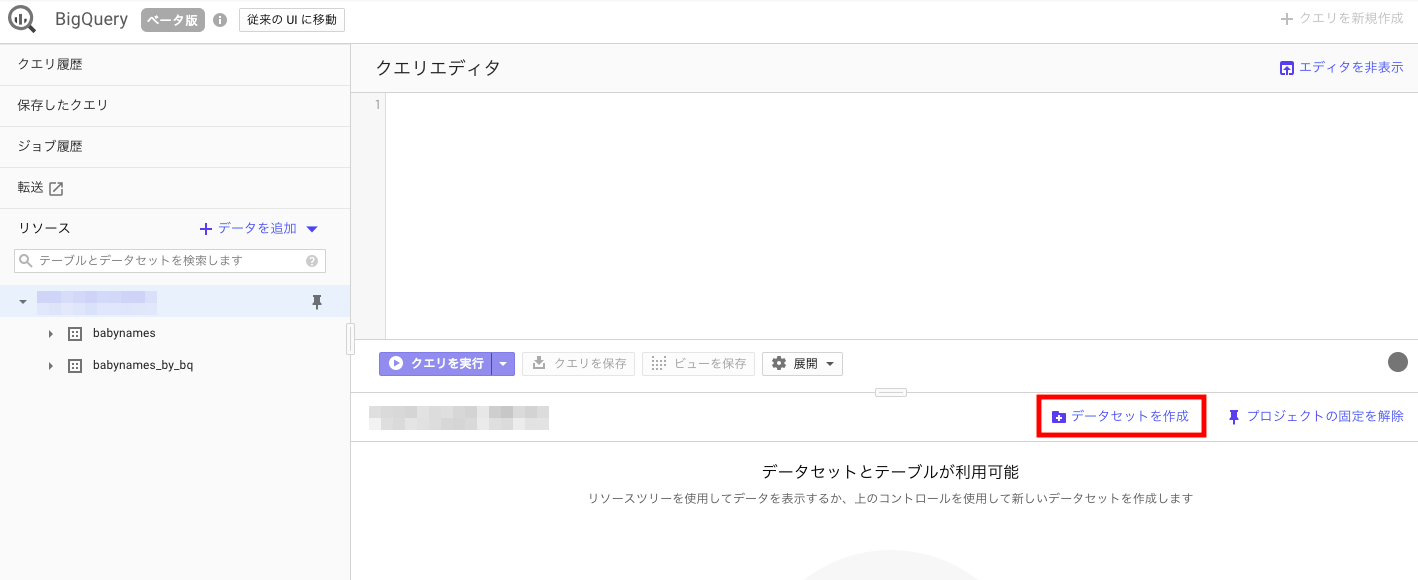
左のリソースに作成したデータセットが表示されるのでクリックしてください。続いて「テーブルを作成」をクリックします。
テーブル名を入力し、スキーマは「テキストとして編集」をクリックして以下をコピペします。
id:INTEGER,datetime:DATETIME,message:STRING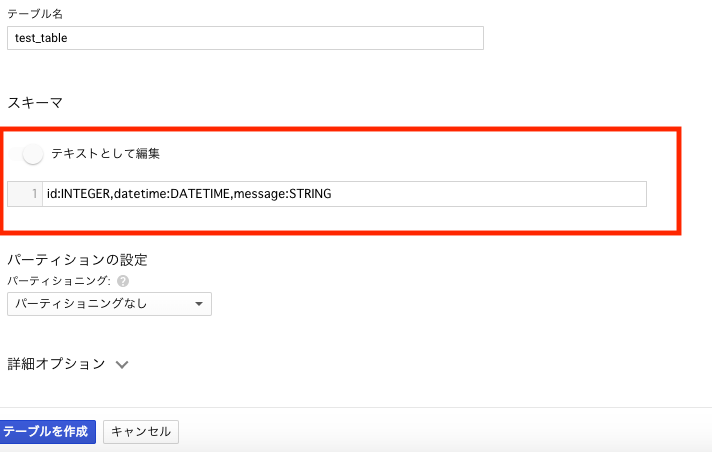
「テーブルを作成」をクリックすると3カラム(id, datetime, message)のテーブルが作られます。
Cloud Storage
一時ファイルを保存するためのバケットを作成します。既存のバケットを使うので不要!!という方はスキップしてください。
GCPのWebコンソールで、左上のナビゲーションメニューからStorageを選択します。
バケットを作成をクリックし、任意のバケット名を指定したうえで作成してください。
ストレージクラスはRegionalをおすすめします。
2. Dataflow ジョブ実行
画面上部の「テンプレートからジョブを作成」をクリックします。
任意のジョブ名を入力し、テンプレートは「Cloud Pub/Sub to BigQuery」を選択してください。
「Cloud Pub/Sub input topic」は作成したtopic名を、
「BigQuery output table」は出力先のBigQueryテーブル名(表id)を
それぞれ指定のフォーマットで入力してください。
「一時的なロケーション」は作成したバケット名と保存したいフォルダの名前を入力してください。予めフォルダを作成していなくても構いません。
バケット名がtomono_test_bucketで、フォルダ名をtestにしたければ、
gs://tomono_test_bucket/testとなります。
オプションパラメータもつけられますが、今回はなしで進めます。
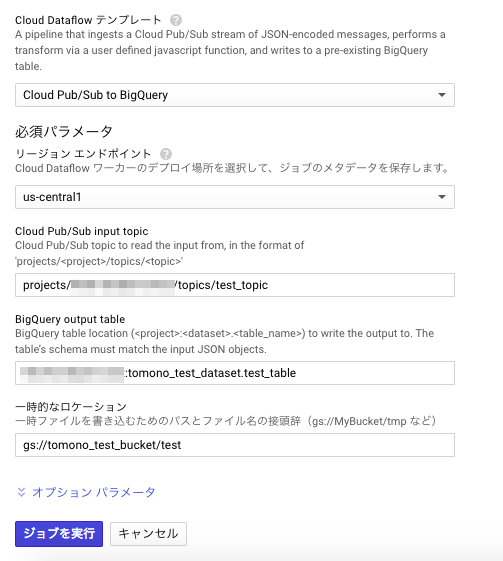
「ジョブを実行」をクリックすると、ストリーミングのジョブが開始し、ジョブの詳細画面が表示されます。
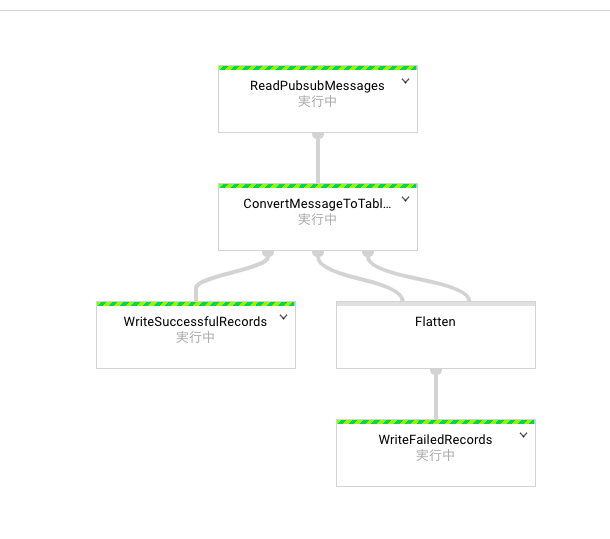
ジョブの詳細画面では内部のフローが、
Pub/Subからデータ入力
↓
メッセージをテーブルの行に変換する
↓
変換に成功したレコードを出力
という形で順次処理されていくようになっているのがわかります。
パイプライン上で実行され始めると、上記写真の「実行中」と書かれている部分に、処理中のデータ量が表示されます。
実は入力されたメッセージを行データに変換できなかった場合の処理も用意されているのですが、今回はそちらの設定は無視して進めています。
3. Pub/Sub へメッセージ送信
テーブルに挿入したいデータをPub/Subのメッセージに入力し、パブリッシュします。
今回はGUIからテスト実行のみします。
Pub/Subの管理画面を開き、「メッセージをパブリッシュ」をクリックします。
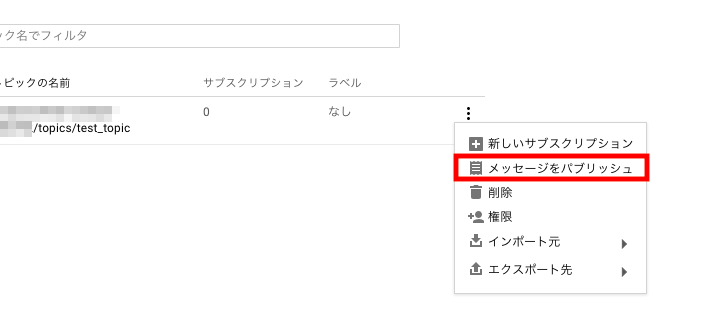
メッセージの欄にJSON形式でインサートしたいデータを入力してメッセージを公開します。
例で作成したテーブルのスキーマであれば、以下のような形式です。
{"id": "100", "datetime": "2018-12-25 00:00:00", "message": "Merry Christmas!!"}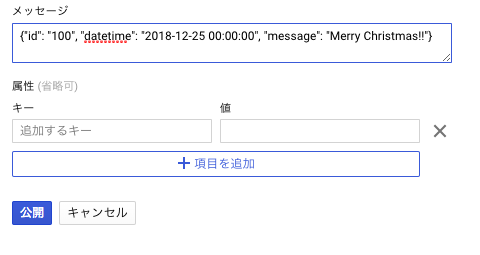
BigQueryの画面で、「テーブルをクエリ」ボタンなどから、select文を実行するとデータが投入されていることが確認できます。
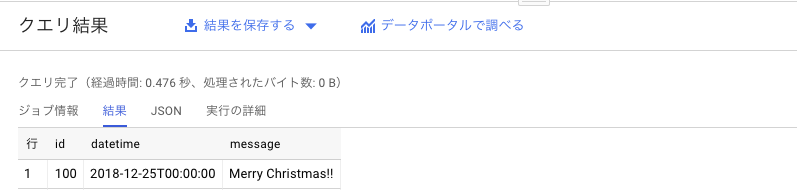
もし、テーブルにデータが入っていない場合、入力形式ミスなどでエラーとなっている恐れがあります。
Dataflowジョブの詳細画面に戻り、ログを確認してください。
4. Dataflow ジョブ停止
放置すると何も処理せずとも料金がかかってしまうので、ストリーミング処理が不要になったら必ず停止しましょう。
Dataflowジョブの詳細画面に戻り、右にある「ジョブを中止」ボタンから停止します。
オプションはキャンセルを選択すれば問題ありません。
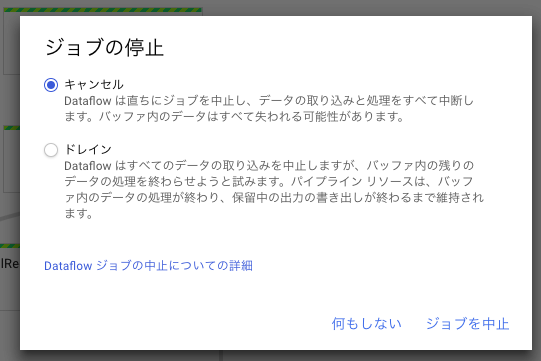
ドレインはパイプライン内に処理中のデータが残っている場合に、全て処理しきってから終了しようとします。
最後に
いかがでしょうか、テンプレートを利用するだけなら拍子抜けするくらい簡単に始めることができたのではないでしょうか。
今回は1レコード登録しただけですが、データ量を増やして実行しても問題なく動作します。
Dataflowのテンプレートを用いることで、データ処理基盤が簡単に作成できることを実感してもらえれば幸いです。
Dataflowを用いることで、実環境をわざわざ自分で構築することなく、オートスケール可能なデータ処理基盤を作ることが可能です。また、今回紹介したBigQueryとCloud Pub/Sub以外にもパイプラインに連携させたり、処理を挟むことが可能です。
今回はさくっと使ってもらうため、Googleから提供されたテンプレートをそのまま実行するという形で進めていきました。
とはいえ、決められたことだけじゃなくてもっと色々なことをやってみたいですよね?
なので、今後ApacheBeamで独自のパイプライン処理を作るという点についてもフォーカスして記事を書こうと思っていますので、そちらもよろしくお願いします!!
さーて、明日のアイソルート Advent Calendarは?
yamasaki.sさんの「【iOS】ML Kit for Firebaseの顔検出を使って笑顔を検出してみた」です!!
AIの民主化を掲げるGoogleは、誰でも利用できる高精度な機械学習プラットフォームを提供してくれますが、ML Kit for Firebaseを使うことで、どんなことができるのでしょうか。
すごく楽しみですね!!
それでは!

脚注
-
-
- ちなみにクラウドアーキテクトの資格は2年で切れるので、私は再取得しない限り2019/11まで正式に名乗ることができます。2年での更新は正直厳しいですが、だからこそ変化する業界の中で価値を持てるのかな、とも考えています
- 指定したデータに対して一括処理
- 随時データの流入を待ち受けておき、送られてきたデータに対して逐次処理
- 2018/12現在、オートスケーリングはバッチ処理がデフォルトで有効、ストリーミング処理は実行時に有効化が必要となっています。詳しくはこちら
- 2018/12現在、ApacheBeamはJava, Python, Goの3言語がサポートされているようです
- 課金は1秒単位で行われます
-