







【BigQuery】CREATE文を使えるの知ってた?SQLでテーブル作成
BigQueryのDDLサポートが2018年7月にGAとなりましたね。Standard SQLで”CREATE TABLE“することができるようになり、SQLユーザーにとってはBigQueryを利用する際の敷居が少し下がりました。
本記事ではBigQueryの CREATE TABLE 文でどのようなことができるかと、その構文に関して記載します。

目次
- はじめに
- 事前準備(データセット作成)
- CREATE TABLE構文
- 基本的な使い方
- オプションパラメータの指定
- 分割テーブルの作成
- SELECT文の結果を使ってテーブルを作成
- CREATE TABLE IF NOT EXISTS 構文と、CREATE OR REPLACE TABLE 構文
- おわりに
はじめに
この記事は アイソルート Advent Calendar 20日目の記事です。
こんにちは。
最近GCPでデータ分析基盤構築系の仕事をもっとやりたい、GCPクラウドアーキテクトの tomono.t です。
みなさんはBigQueryでテーブルを作る方法をご存知でしょうか。
Webコンソールにアクセスして手作業で作る?
bqコマンドを使う?
いえいえ、それ以外にも方法はあります。
なんと、BigQueryは標準クエリでDDLがサポートされているので、SQLで “CREATE TABLE” できます!!(`・ω´・)+
え?それがどうした?
ええと…ですね…(´・ω・`)
まず、BigQueryではWebコンソールからGUIベースでテーブルを作成できます。
なので、ノンコーディングで画面をポチポチするだけでテーブルが作成でき、アナリストや普段BigQueryで開発しない人など、誰でも簡単にテーブルを作成できます。
ただし、作ってもらうとわかりますが、この作業は正直すごーーーく面倒くさいです。誰でも簡単にできるのですが。
テーブルを一つ作るのにどうしても作業時間がかかりますし、PoCやプロトタイプの開発なんかでテーブルを作って消してまた作って、みたいにしたいことありますよね?
ではコマンドでテーブル作成できる方法は?というと、もちろんBigQueryのCLIツールであるbqコマンドに用意されています。
例えば、 bq load を使えばcsvやjsonのデータファイルからテーブル作成とデータ追加を同時にできますし、 bq mk でテーブルの追加は可能です。
ただし、使用するデータがない場合や追加したくない場合もありますし、bqコマンドでテーブルを追加したり、テーブルに細かい設定を入れる方法は、少し覚えるためのハードルが高い印象があります。
がっつりコマンドを覚えたくない人にとってはけっこう大きな問題ですよね。
それでは、導入コストが低くて使い勝手のいい方法はないのか?
もう言いたいことはわかってしまうでしょうが、みんなが大好きなSQLを使うのがおすすめです。
SQLならば
- コードベースで管理でできる
- SQLを使ったことがある人ならば、書きやすく、読みやすい
- テスト的に作成・改変しやすい
と、Web画面から作成する方法とbqコマンドを利用する方法で互いにカバーしづらかった部分を埋めてくれそうです。
実はこのDDL機能は2018年7月にGAリリースされたものでまだ情報が少なく、本家のドキュメントも読みづらいし、周囲に聞いた感じでは CREATE 文が使えることを知らない人がまだ多いようなので、自分が書いてやろうと思った次第です。
というわけで、本記事ではBigQueryのStandard SQLにおける CREATE 文の構文に関する解説を書いていきます。
元ソースは本家ドキュメントのデータ定義言語ステートメントの使用です。
GCPアカウントは各自で取得をお願いいたします。
また、本記事に記載されているクエリは、Webコンソールから実行してもらえば機能します1)。
GCP Webコンソールから、BigQueryの画面を開き、下記エディタに入力して実行してください。
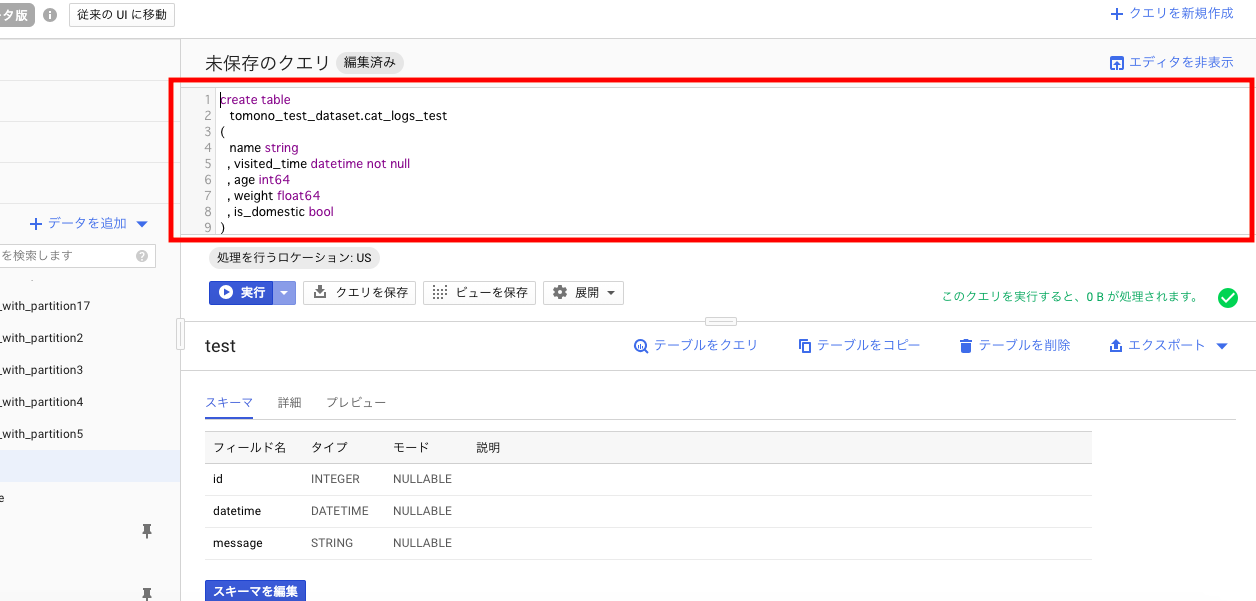
不要なテーブルは「テーブルを削除」ボタンから削除するなり、 DROP TABLE hoge.hoge するなりしてやってください。
事前準備(データセット作成)
CREATE 文を利用するその前に、予めテーブルの登録先となるデータセットを作成しておく必要があります。
なんとも残念なことに、調べた限り2018/12現在はデータセットをSQLで作ることはできないようです。
まあデータセットを大量に作る必要はあまりない気がするので、いいですかね。
テスト用のデータセットは以下の手順で作成するか、 bq mk コマンドなどで作成してください。
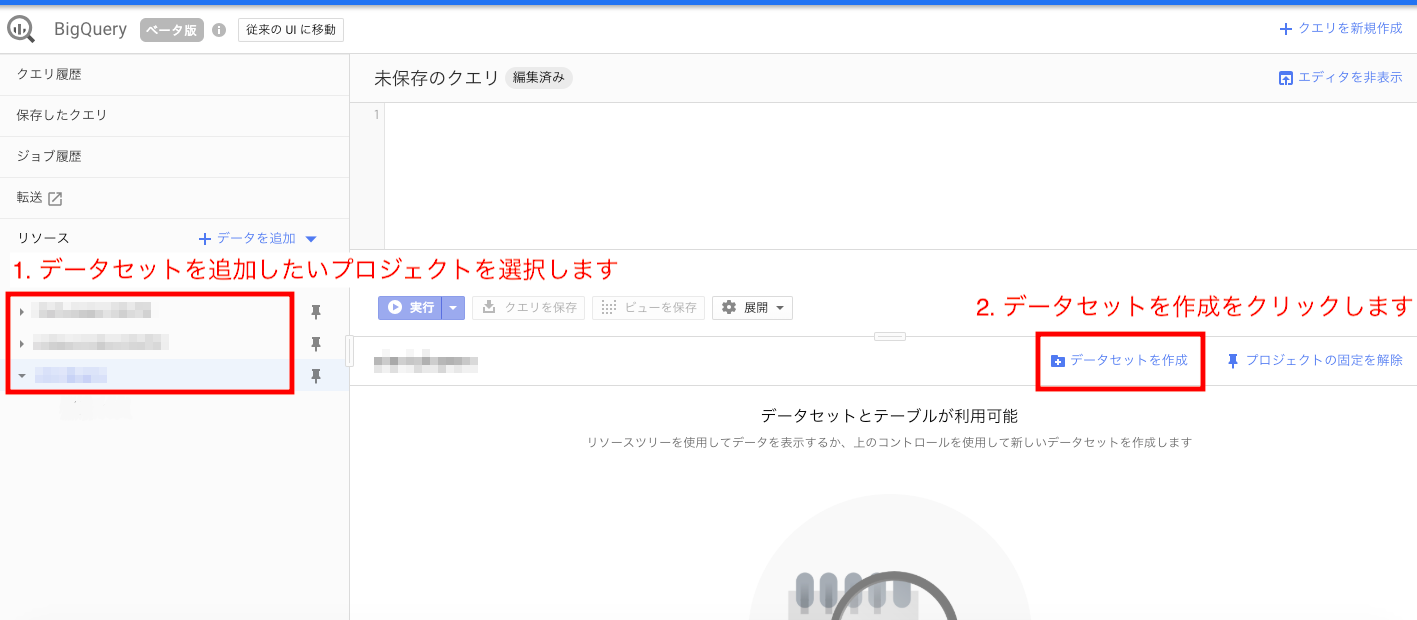
CREATE TABLE 構文
内容の説明はそれぞれ行っていきますが、最初に CREATE TABLE の構文を書いておきます。
なお、{}は必要に応じて記述する箇所です。
CREATE TABLE
{[project_id].}[dataset_name].[table_name]
(
[column_name1] [data_type] {NOT NULL} {OPTIONS(description="[description_text]")}
, [column_name2] ...
, ...
)
{ PARTITION BY [partition_expression] }
{
OPTIONS
(
[option_name1] = [value]
, [option_name2] = ...
, ...
)
}
{
AS SELECT ...
}
後に説明しますが、注意事項挙げておきます
- GCPの別プロジェクトにアクセスしない場合、project_idを省略可
- project_idを指定する場合、バッククオート(`)で囲む
- ex. `project-id.dataset_name.table_name`
基本的な使い方
下はシンプルな構文の例です。
テーブル名とカラムのスキーマのみ定義しています。
NOT NULL制約をかけたい場合は、データ型の後に NOT NULL を追加してください。
CREATE TABLE tomono_test_dataset.cat_logs ( name STRING , visited_time DATETIME NOT NULL , age INT64 , weight FLOAT64 , is_domestic BOOL )
上の例では省略していますが、別プロジェクトのデータセットにアクセスする場合は以下のように指定してください。project idでハイフンが入るとエラーとなりますので。
`project-id.test_dataset.cat_logs`
構文的には一般的なRDBのSQLと同様の形式ですね。
現状、型の指定の仕方として、通常の整数型は INT64 、浮動小数点型は FLOAT64 と書かないと駄目( INT や INTEGER , FLOAT などはNG)なようです。
その他、BigQueryで使用できる型の種別に関する情報は標準 SQL データ型 | BigQuery | Google Cloudをご参照ください。
配列( ARRAY )型や構造体( STRUCT )型といった非正規的な形でデータを扱うための型もあったりして面白いです。
オプションパラメータの指定
テーブルやカラムに対し、オプションを設定することが可能です。
オプションを指定する場合、 OPTIONS() の中に種別と設定値を記述します。
テーブルのオプション
例えば、テーブルには以下のようなオプションが指定できます。
これらはテーブル作成後に変更することも可能です。
- expiration_timestamp : テーブルの有効期限
- friendry_name : わかりやすい名前
- description : 説明
- labels : ラベル
CREATE TABLE
tomono_test_dataset.cat_logs
(
name STRING
, visited_time DATETIME
)
OPTIONS
(
expiration_timestamp = TIMESTAMP("2018-12-24 01:00:00 UTC")
, friendly_name = "My cat diary"
, description = "The record of encountered cats"
, labels = [("user", "tomono.t"), ("importance", "high"), ("confidentiality","private")]
)
expiration_timestamp を設定すると、自動で指定した日時にテーブルが削除されます。
分析用途で一時的に作るテーブルなど、長期間残しておく必要の無いテーブルなどで利用できます。
labels はキーバリュー形式で複数登録でき、テーブルを検索する際に登録したラベルを利用可能です。
カラムのオプション
現在カラムに対して登録できるオプションは description のみです。
CREATE TABLE
tomono_test_dataset.cat_logs
(
name STRING OPTIONS(description = "Their nickname")
, visited_time DATETIME
)
分割テーブルの作成
BigQueryでサポートされる分割テーブルもSQLで作成可能です。
分割テーブルでは、日付を指定して検索することで、検索のスキャン対象となるレコード数を絞ることができ、BigQuery利用コストの軽減や、実行時間の短縮に効果があります。
本記事では趣旨から外れるので分割テーブルについての詳細は書きませんが、大容量のテーブルや、日時で絞り込みを行うようなテーブルでは可能な限り活用したい機能です。
分割テーブルを作成する場合、 PARTITION BY 句をクエリに追加します。
指定したカラムの日付で分割
特定のカラムに入力された日付を利用して分割します。
検索時は指定したカラムを WHERE 句に記述するだけでスキャン対象を絞り込み可能です2)。
DATE型のカラムでテーブル分割する場合
CREATE TABLE tomono_test_dataset.cat_logs ( name STRING , visited_time TIME , visited_date DATE ) PARTITION BY visited_date
TIMESTAMP型のカラムでテーブル分割する場合
CREATE TABLE tomono_test_dataset.cat_logs ( name STRING , visited_time TIMESTAMP ) PARTITION BY DATE(visited_date) -- TIMESTAMP型の場合はDATE型へのパースが必要
なお、現状では DATETIME 型のカラムは分割の条件に利用できないらしく、この点には注意が必要です。
DATETIME 型をパースすることで、なんとかできないかと試してみたのですが、下記のエラーでばっちり怒られました。
PARTITION BY expression must be DATE(_PARTITIONTIME), DATE(<timestamp_column>) or else a DATE column
BigQueryに登録された日付で分割
BigQueryに登録された日時を利用して分割します。
この場合、日付を判別する必要があるカラムが存在しなくても、BigQuery側で登録日時から自動判別して分割してくれるようになります。
ただし、この方法を利用する場合はUTC時刻で投入されるため、日本時刻とズレが生じる3)ことには注意が必要です。
CREATE TABLE tomono_test_dataset.cat_logs ( name STRING ) PARTITION BY DATE(_PARTITIONTIME) -- _PARTITIONTIMEはUTC時刻となって
分割テーブルに関連したオプション
以下オプションは分割テーブルでのみ設定可能です。
- partition_expiration_days : パーティションの有効期限(日)
- require_partition_filter : パーティションフィルタの強制
CREATE TABLE
tomono_test_dataset.cat_logs
(
name STRING
, visited_time TIMESTAMP
)
PARTITION BY DATE(visited_time)
OPTIONS
(
partition_expiration_days = 365
, require_partition_filter = true
)
partition_expiration_days は古いデータを随時削除していく設定です。
PARTITION BY 句で指定したカラムのデータが、現時刻から指定した日数より以前のデータは削除されます。
ちなみに、時々おっちょこちょいな私は、開発時に partition_expiration_days を1に設定し、翌日にそのことを忘れて「なんかBigQueryのデータが消えた!、誰か消した!?」と騒ぎ立てるという珍事件を引き起こしたことがあります。(反省してま〜す)
require_partition_filter は検索時に分割の条件としたカラムでの検索を強制する設定です。
これは不用意なクエリ実行によって高額な料金が請求される事故を防止できる機能といえます。
どういうことかといいますと、通常は検索条件でpartitionした条件のカラムを指定しない場合、分割テーブルであってもBigQueryは全レコードに対してスキャンを行ってしまいます。
しかしながら、 require_partition_filter をtrueに設定しておくと、クエリでpartitionカラムを正常に指定しない場合、以下のようなエラーが生じるようになります。
Cannot query over table ‘tomono_test_dataset.cat_logs’ without a filter over column(s) ‘visited_time’ that can be used for partition elimination
大規模なテーブルをフルスキャンして無駄なコストをかけるというありがちな事故は、この設定を利用することで避けることができるかと思います。
ちなみに、Webコンソールからテーブル設定を参照すると、 require_partition_filter をtrueにしていても「パーティションフィルタ 省略可」と表示されるようなのですが、実際には省略したクエリは実行不可能です。
試しに SELECT で検索しようとするとエラーが表示されます(2018/12現在)。
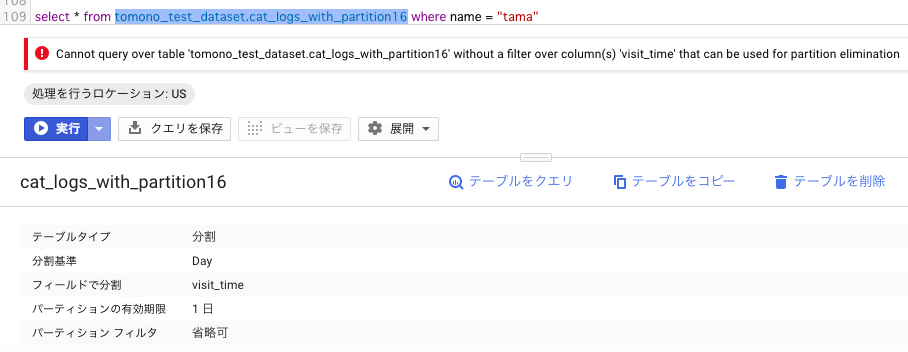
この項目は「省略不可」となるのが正しい気がするのですが、バグなんですかね?
間違っていたらすみません。
SELECT文の結果を使ってテーブルを作成
シンプルな機能だけ利用したい方には不必要かもしれませんが、
SELECT 文の結果からテーブルを作成する、いわゆる CREATE TABLE AS SELECT 的な機能もサポートされています。
例えば、分析用途で使用する集計データを一時的にテーブルとして登録する、といったことが可能です。
下の例では、name別に月毎のレコード数をカウントした結果をテーブルとして作成します。作成したデータは”2019/01/01″に削除されます。
CREATE TABLE
tomono_test_dataset.aggregated_cat_logs
OPTIONS(expiration_timestamp = TIMESTAMP("2019-01-01 00:00:00 UTC"))
AS
SELECT
name
, PARSE_DATE("%Y-%m", FORMAT_DATE("%Y-%m", DATE(visited_time))) AS visited_month
, COUNT(*) AS count
FROM
tomono_test_dataset.cat_logs
WHERE
visited_time > "2018-01-01"
GROUP BY
name
, visited_month
上記の例を見てもらうとわかりますが、 SELECT 文を利用する場合はカラムのスキーマ情報を記載する必要がありません。
しかしながら、カラムのスキーマ情報を記載することで NOT NULL 制約を付けたり、明示的にデータ型を指定することも可能です。
CREATE TABLE
tomono_test_dataset.aggregated_cat_logs
(
name STRING
, visited_month DATE NOT NULL
, count FLOAT64 -- countをfloatの列として定義
)
AS
SELECT
name
, PARSE_DATE("%Y-%m", FORMAT_DATE("%Y-%m", DATE(visited_time))) AS visited_month
, COUNT(*) AS count
FROM
tomono_test_dataset.cat_logs
WHERE
visited_time > "2018-01-01"
GROUP BY
name
, visited_month
WITH 句を利用して書くこともできました。(下は微妙な使用例ですが…)
ただ、どうやら CREATE TABLE AS の後ろに書かないとエラーとなってしまうようです。
CREATE TABLE
tomono_test_dataset.aggregated_cat_logs
AS
WITH tmp AS (
SELECT
name
, PARSE_DATE("%Y-%m", FORMAT_DATE("%Y-%m", DATE(visited_time))) AS visited_month
, COUNT(*) AS count
FROM
tomono_test_dataset.cat_logs
WHERE
visited_time > "2018-01-01"
GROUP BY
name
, visited_month
)
SELECT * FROM tmp WHERE count > 10
現在、ドキュメントに記載されているように、以下制限事項があるようです。
クエリ結果から取り込み時間分割テーブルを作成することはできません。代わりに、CREATE TABLE DDL ステートメントを使用して取り込み時間分割テーブルを作成した後に、INSERT DML ステートメントを使用してそのテーブルにデータを挿入します。
BigQueryに登録された日付で分割に記載した方法で分割テーブルを作成できません。
なお、指定したカラムの日付で分割の方法は問題なく実行できます。
CREATE TABLE tomono_test_dataset.cat_logs2 PARTITION BY DATE(visited_time) -- この形式では問題なく分割テーブルを作成可能 AS SELECT visited_time FROM tomono_test_dataset.cat_logs
OR REPLACE 修飾子を使用してテーブルを別の種類のパーティショニングで置き換えることはできません。代わりに、テーブルに対して DROP を行った後に、CREATE TABLE … AS SELECT … ステートメントを使用してテーブルを再作成します。
後述の CREATE OR REPLACE TABLEを利用できません。
CREATE OR REPLACE TABLE で一番使いそうな用途なんですけどね…まあ DROP すればいいだけですが。
CREATE TABLE IF NOT EXISTS 構文と、CREATE OR REPLACE TABLE 構文
どちらも基本の CREATE TABLE 文と同様の構文を使用します。
CREATE 文の修飾子という扱いのようです。
CREATE TABLE IF NOT EXISTS
同名のテーブルが存在しなければ、テーブルを作成します。
CREATE TABLE IF NOT EXISTS tomono_test_dataset.cat_logs ( name STRING , visited_time DATETIME )
基本の CREATE 文では、同名のテーブルが存在するとエラーとなりますが、
この構文を使用した場合はエラーとならず、正常終了します。
CREATE OR REPLACE TABLE
同名のテーブルが存在した場合、テーブルが置換されます。
すなわち、テーブルを削除後に再作成されます。
CREATE OR REPLACE TABLE tomono_test_dataset.cat_logs ( name STRING , visited_time DATETIME )
開発時にいろいろ試したりする際には便利なのですが、当然実行時に置換するテーブルのデータが削除されるのでお気をつけて!!
おわりに
本記事はBigQueryの CREATE TABLE 文でできることを自分に書ける範囲で列挙していきました。
BigQueryのDDLに関しても、一般のRDBでできそうなことの大半はサポートされているような気がしています。
加えてBigQueryならではの機能が用意されているのですが、すでにSQLをよく利用している人にとってはさほど苦にならないかと思います。
以前のBigQueryは取っ付きにくい印象がかなり強かったですが、だいぶ緩和されてきたなという感じです。
面倒くさいと思っていた方も改めてBigQueryを試してみてほしいです!
さーて、明日のアイソルート Advent Calendarは?
hasuda.rさんの「【新人・若手・未経験のあなたへ】エンジニアとしての土台を、砂場でつくりましょう」です!!
「ん?どういうことかな?」とタイトルを見た時に思いましたが、内容はエンジニアとして誰しもが振り返ってみるべき事柄をhasuda.rさんが語る記事です。新人・若手・未経験でない方も見て損はないかと思いますので、お読みになってはいかがでしょうか。
それではまた!

脚注
-
-
- 一応ですが、bq queryでも打てます。標準SQLでの実行(–use_legacy_sql=false)をお忘れなく
- BigQueryはスキャンしたデータ量に応じて料金が変動するのですが、通常はWHERE句で対象を絞り込んでもスキャンするデータ量は変わりません。検索対象が絞り込まれるのは分割テーブルの機能によるものです
- そもそもBigQueryでは時刻は全てUTC時刻として扱われます。要注意です
-