







BigQuery 入門 – 半構造化データを分析するには?
半構造化データを保存、クエリ実行できるのが BigQuery の大きな魅力の一つです。
今回は、BigQuery で半構造化データを分析する際に必須の操作を紹介したいと思います。

この記事は アイソルート Advent Calendar 2020 の4日目の記事です。
こんにちは。モバイルソリューショングループの arai.ya です。
BigQuery の勉強をしていて最初に躓いたのが、本記事のテーマの半構造化データの扱いでした。その復習も兼ねて、半構造化データを分析する際の基本をまとめてみました。
はじめに:BigQuery とは
BigQuery とは、Google が提供するクラウドデータウェアハウスです。
インフラの運用・保守等は Google がやってくれるサーバレスなデータウェアハウスであるため、ユーザはデータの収集や分析といった、本来やりたいことのみにフォーカスできます。
BigQuery 超入門編の記事 もありますので、良ければこちらも合わせて読んでみてください。
半構造化データとは
まず構造化データは、あらかじめデータの構造が決まっていて、その構造に合わせてデータを保存していきます。
MySQL, PostgreSQL などの RDB は構造化データを保存するためのデータベースと言えます。
それに対して半構造化データとは、構造化データのように決まった形式はなく、データとタグの組み合わせでデータを管理します。
またデータ構造がネストされるのも大きな特徴です。XML 形式や JSON 形式は半構造化データの形式の一例です。
Google Cloud Platform には、半構造化データを扱うための NoSQL データベースとして、Cloud Firestore, Cloud Bigtable などがあります。
半構造化データの操作をやってみよう
それではさっそく、BigQuery に保存された半構造化データに対してクエリを実行してみましょう。
まず、BigQuery のウェブ UI を開きます。
以下のような見慣れた画面が出てきます。
今回は、BigQuery の一般公開データセットの一つ、Google Analytics Sample データセットの中身を見ていきます。
このデータセットには Google ブランドの商品を販売している Google Merchandise Store という EC サイトの Google Analytics のデータがサンプルとして保存されていて、実践的なデータ分析の練習やクエリを試すのに適しています。
またこのデータセットは実際に Google Analytics を BigQuery にエクスポートする際と同様のスキーマでデータが保存されていて、スキーマの詳細は
https://support.google.com/analytics/answer/3437719?hl=ja
から確認できます。
さて、まずは以下のようなクエリを実行してみましょう。
SELECT
fullVisitorId,
visitStartTime,
hits
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
WHERE
fullVisitorId = '1270377738816552069'
ここで、SELECT 句で指定しているフィールドはそれぞれ
- fullVisitorId: ユニークユーザ ID
- visitStartTime: セッション開始時刻のタイムスタンプ
- hits: ページビューなど、記録されるユーザの行動
です。
このクエリを実行すると以下のような結果が得られました。
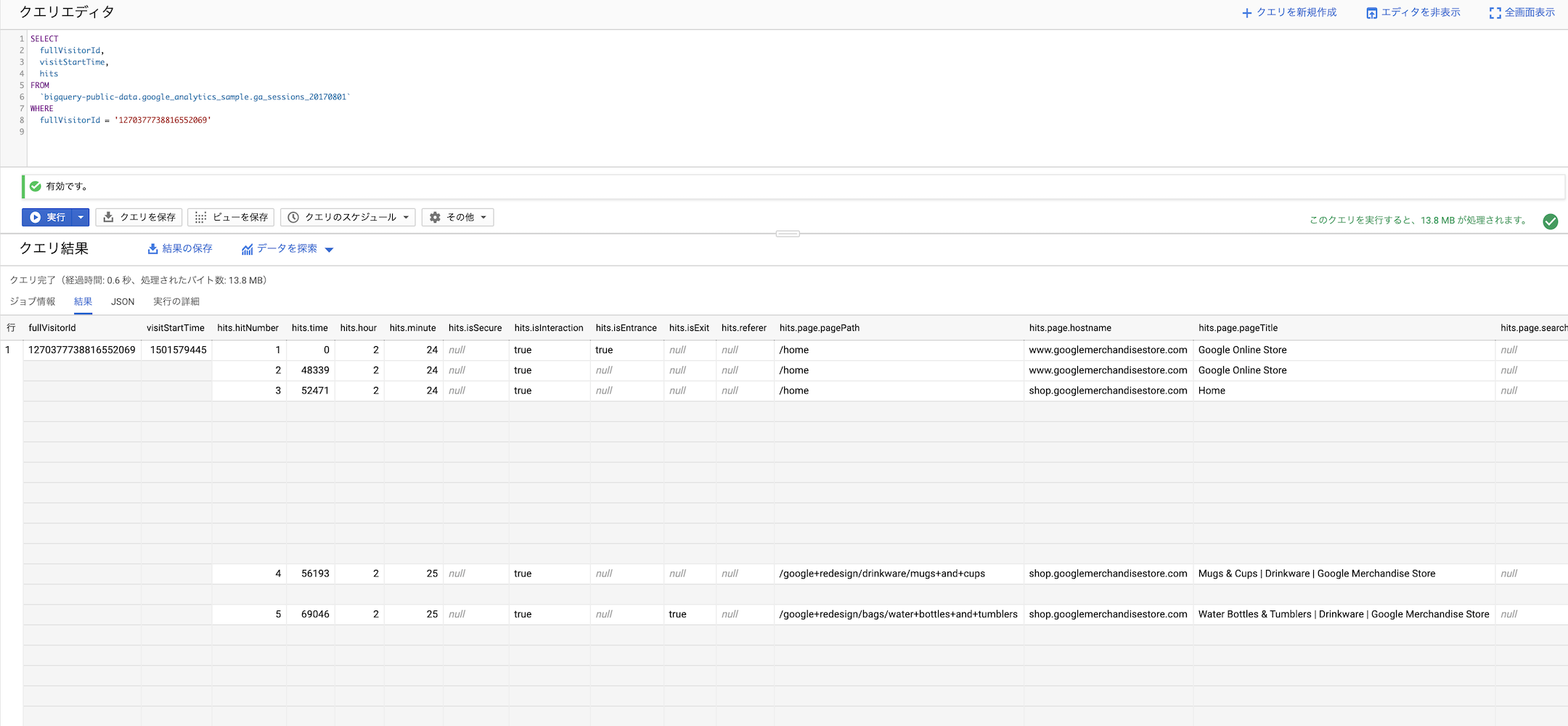
このセッションではあるユーザが5つの hit を発火したことが記録されているのがわかります。
Google Analytics のデータはフィールドがとても多いので、とりあえずこのセッションでユーザが閲覧したページのタイトルだけを表示してみましょう。
以下のようなクエリを書いてみました。
SELECT
fullVisitorId,
visitStartTime,
hits.page.pageTitle
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
WHERE
fullVisitorId = '1270377738816552069'
すると、
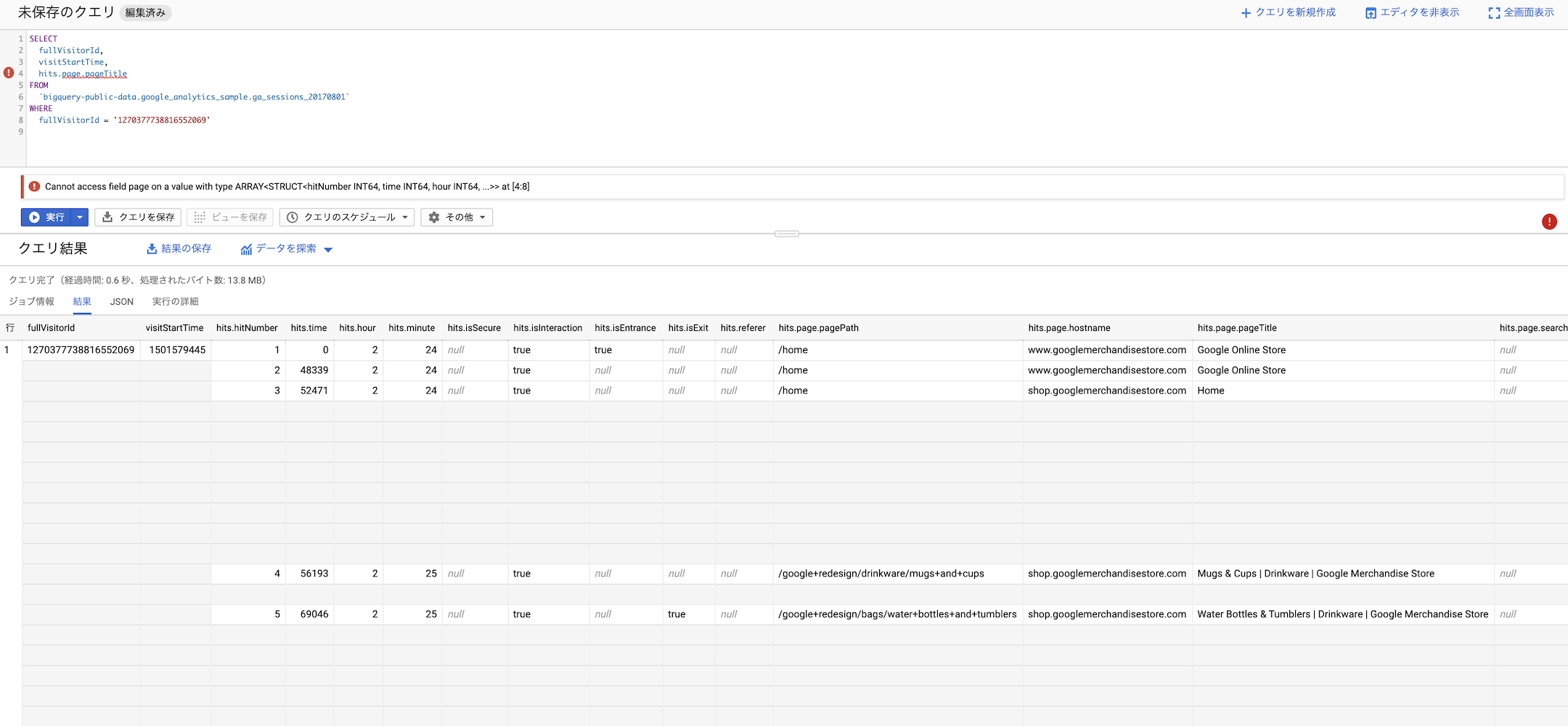
このようにエラーが出てしまい、クエリが実行できません。
Cannot access field page on a value with type ARRAY<STRUCT<hitNumber INT64, time INT64, hour INT64, ...>> at [4:8]hits は構造体の配列として保存されているため、このままでは取り出すことはできません。
このエラーを解決するためには、UNNEST 関数を使います。UNNEST 関数は、配列を受け取り、その配列をそれぞれの要素に分解して返します。
イメージとしては、このように配列で保持されているデータを
| 1 | [“a”, “b”, “c”] |
| 2 | [“d”, “e”] |
次のように、各要素が行になるよう展開します。
| 1 | “a” |
| 1 | “b” |
| 1 | “c” |
| 2 | “d” |
| 2 | “e” |
UNNEST 関数を使ってページタイトル一覧を取得できるようにしたクエリが以下になります。
SELECT
fullVisitorId,
visitStartTime,
h.time,
h.page.pageTitle
FROM
`bigquery-public-data.google_analytics_sample.ga_sessions_20170801`,
UNNEST(hits) AS h
WHERE
fullVisitorId = '1270377738816552069'
これを実行すると、
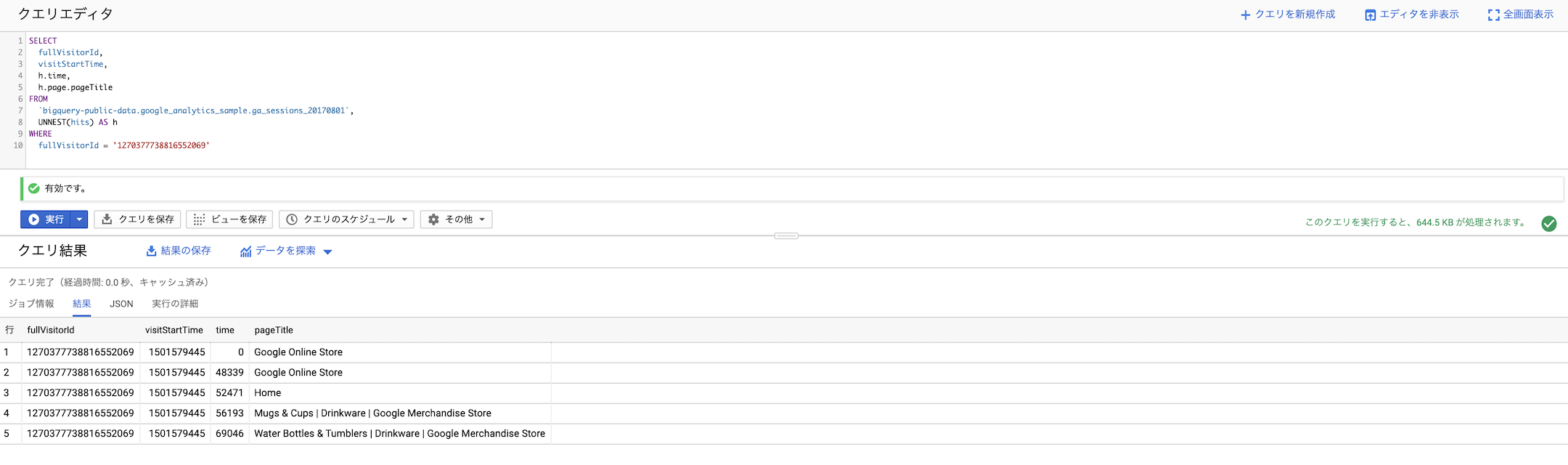
このような結果が得られました。
ここでは、各 hit のページタイトルの他にも、visitStartTime からの経過時間(hits.time)もそれぞれ表示するようにしてみました。
ユーザがウェブサイト上でどのようにページ遷移しているのかがわかりやすくなりました!
以上が、基本的な半構造化データを UNNEST で分解して表示する方法になります。
これで半構造化データも怖くありません!
おわりに
今回は、BigQuery の UNNEST 関数を使った半構造化データに対する基本的な操作をやってみました。半構造化データをそのまま保存できる BigQuery のメリットを活かせるように、しっかり習得しておきたいですね。
これで半構造化データを分析できるようになったので、次は実際に JSON などを BigQuery に半構造化データとして保存する処理についても詳しく調べてみたいと思います!
明日は suzuki.ko さんの ESXi内のルーティングに必須!VyOSで仮想ルーター構築 です!
