







Vertex AI Workbenchを使ってちょこっとデータ分析

Cloud上で機械学習やデータ可視化を行う為のコーディングを行う際、
無料で利用出来るGoogle Colaboratoryが候補として挙がると思います。
一方で、実行環境単位での共有、長時間の実行が出来ない等の側面もあります。
そこで、GCPのCompute Engineのリソースを活用し、JupyterLab上で実行環境を他の開発者とも共有しながら使える、
Vertex AI Workbenchについて、テキストデータ内のトレンドワード可視化をテーマに紹介します。
目次
はじめに
マネージドノートブック環境の構築
テキストデータ内のトレンドワード可視化
おわりに
はじめに
こんにちは。IPコミュニケーショングループのshimazaki.hです。
この記事は アイソルート Advent Calendar 2022 の15日目の記事です。
昨日はfujishima.yさんの VXLANを用いた拠点間通信とRancherによる監視システムの構築 でした。
本題に入る前に、Vertex AI Workbenchについて紹介します。
Vertex AI WorkbenchはGoogleが提供する、データサイエンス向けの開発環境です。
Compute Engine、JupyterLabの環境を使用して、
データのクエリと探索、モデルの開発とトレーニング、パイプラインの一部としてのコードの実行などを行うことができます。
Vertex AI Workbenchの環境は主に2種類あります。
- マネージド ノートブック
インスタンスは Google Cloud が管理する環境で、メンバー間で環境を共有しながら構築する際はこちらがおすすめです。 - ユーザー管理のノートブック
環境をきめ細かく制御したいユーザー向け。
2022/12/15現在、sudo等を用いてアプリケーションやライブラリをインストールする際はこちらの環境がおすすめです。
本記事においては、マネージドノートブック環境について触れて行きます。
マネージドノートブック環境の構築
マネージドノートブック環境の構築手順としては、以下の3つです。
1.テキストのダウンロード
2.テキストデータの単語分解
3.ワードクラウド画像の作成
1.公式ページを参考にNotebook APIを有効化する
『始める前に』の項目までを完了すると、NotebookAPIを有効化出来ます。
https://cloud.google.com/vertex-ai/docs/workbench/managed/create-instance?hl=ja#before_you_begin
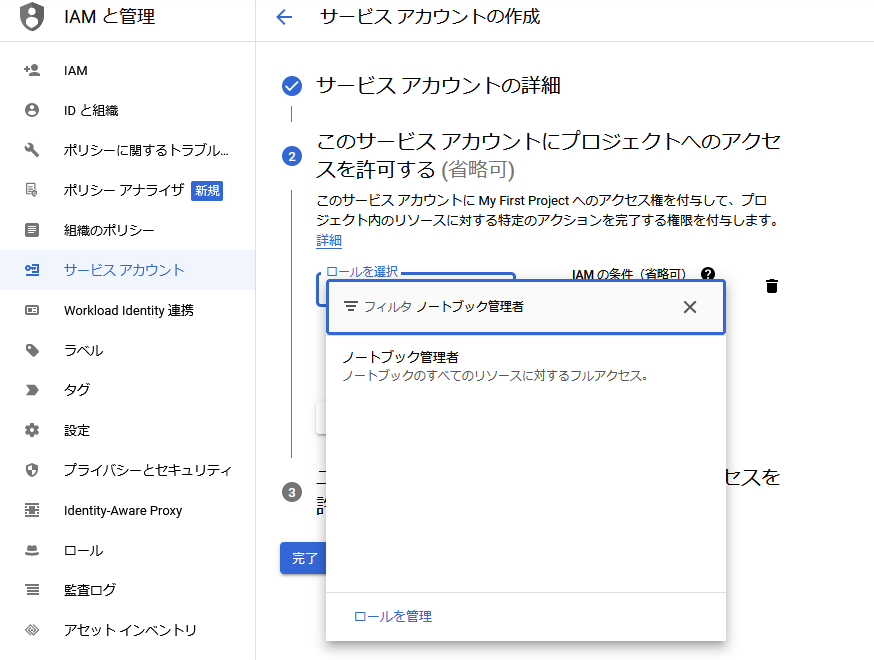
2.サービスアカウントを設定する
サービスアカウントを発行し、権限の設定をします。
このとき、『ノートブック管理者』の権限を付与するようにしましょう。
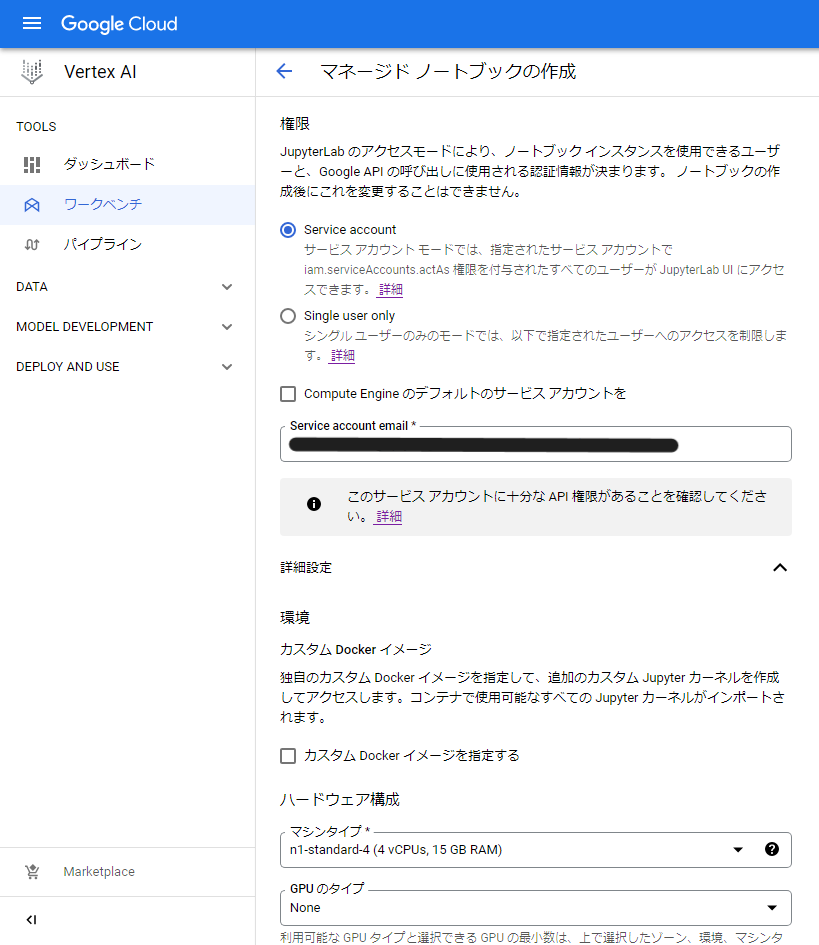
3.マネージドノートブックを作成する
マネージドノートブック環境を構築します。
リージョンやノートブック名については条件に合う任意の値を設定してください。
注意点としては、権限の項目はservice accountを選択し、
『Compute Engine のデフォルトのサービス アカウントを』という項目のチェックを外して、
service accont emailの欄に、先ほど設定したサービスアカウントのemailアドレスを指定します。
詳細設定の中にある、環境については、n1-standard-1やn1-standard-2程度で十分かと思います。
なお、利用中に変更することも可能です。
以上の手順で、マネージドノートブック環境が構築されます。
テキストデータ内のトレンドワード可視化
マネージドノートブックの動作確認も兼ねて、『ワードクラウド』を用いた、
『テキストデータ内のトレンドワード可視化』をテーマにデータ可視化を紹介します。
可視化の手順としては、以下の3つです。
1.テキストのダウンロード
2.テキストデータの単語分解
3.ワードクラウド画像の作成
1.テキストのダウンロード
まず、今回使うテキストデータを取得します。
扱うテキストデータですが、日本語映画推薦対話データセット (JMRD) を扱います。
(引用元: https://github.com/ku-nlp/JMRD)
マネージドノートブックのJupytrLabを起動後、
左上の「+」ボタンをクリックし、Launcher画面から『Notebook → Python(Local)』を選択します。
ノートブックが起動したら、下記のコードを入力して、
取得結果が表示されているか確認してみましょう。
from bs4 import BeautifulSoup
from urllib import request
import json
import pprint
# Japanese Movie Recommendation Dialogue
url = 'https://raw.githubusercontent.com/ku-nlp/JMRD/main/data/train.json'
response = request.urlopen(url)
movie_json = json.loads(response.read())
response.close()
# 1要素だけ確認
pprint.pprint(movie_json[1])
このような形で出力されれば完了です。
2.テキストデータの単語分解
次に、テキストデータを可視化して行きます。
先にコードブロックを追加して、以下の2コマンドを実行しましょう。
!pip install mecab-python3 unidic tqdm wordcloud
!python -m unidic downloadその後、コードブロックを追加し、以下のコードを転記のうえ実行してみてください。
import MeCab
import unidic
from tqdm import tqdm
import re
# MeCabオブジェクトを作成
tagger = MeCab.Tagger('-d ' + unidic.DICDIR)
result = []
# 4000作品以上あり、実行に時間が掛かるため150作品に絞っています。
movie_count = 150
# movie_count = len(movie_json) #全作品を掛ける場合はこれをコメントアウトして下さい。
pbar = tqdm(range(movie_count))
# WordCloudへ渡す文字列
word_str = ""
for i in pbar:
text = ""
# 各作品の会話データの単語分解を実施
for dialogs in movie_json[i]['dialog']:
text = text + dialogs['text']
parse = tagger.parse(text)
lines = parse.split('\n')
# 1単語毎にリスト型へ格納
for line in lines:
if line != 'EOS' and line != '':
items = re.split('\t', line)
if len(items) >= 2:
items[1:] = re.split(',', items[1])
result.append(items)
# トレンドワードとして”固有名詞を可視化”
if items[2] == "固有名詞":
word_str += " " + items[0]3.ワードクラウド画像の作成
ワードクラウドを作成する為に日本語フォントをダウンロードします。
!wget https://github.com/coz-m/MPLUS_FONTS/raw/master/fonts/ttf/Mplus2-Light.ttfフォントをダウンロード後、以下のコードを実行するとワードクラウドが出力されます。
このとき、単語の出現率が多いほど、文字サイズが大きく表示されます。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
font="Mplus2-Light.ttf"
# 画像作成
wordcloud = WordCloud(font_path = font,
max_font_size=40,
background_color="white",
width=500, height=500).generate(word_str)
plt.figure(figsize=(15,12))
plt.imshow(wordcloud)
plt.axis("off")
wordcloud.to_file("result.png")このような形で、画像が表示されれば完了です。
形態素解析した作品数の範囲に応じて結果は変化しますが、
今回の範囲ですと、出演者の名前や監督名がトレンドワードとして検出される傾向が見受けられました。

おわりに
Vertex AI Workbenchのうち、マネージドノートブックについては検索してもあまり記事がでないため取り上げさせて頂きました。
ある程度構築済みデータ分析・可視化環境を、チーム内で共有しつつ活用する際など皆様の参考となればと思います。
あすはfujinami.mさんのStackViewを使った画面実装です。
