







PythonでWebデータを収集する方法(スクレイピング)

この記事は アイソルート Advent Calendar 2022 23日目の記事です。
前日はtakahashinさんの
「半年Tableauを使ったら分析LvがMAXになってました」でした。
こんにちは。クラウドソリューショングループのhasekです。
データ分析が最近注目され始め、需要が高まっており、将来性が高いので勉強し始めました。
データ分析に興味をもっている人のために、記事として書こうと思います。
【目次】
本記事の狙い
Pythonを用いる理由
ここで私がPythonを用いてデータ収集、分析を行う理由として以下の理由があります。
① 複雑な計算が容易にできる
しかし、定形的な処理でないと分析が難しい点や、インターネットの膨大なデータ、ビッグデータを解析するには、処理が重くなってしまいます。
② 統計分析と他の処理の連携が容易
しかし、解析した結果をほかの処理に入れたり、他言語との連携をしたりすることは容易ではないです。
PythonはExcelに比べ、ハードルは高いですし、R言語より統計に特化していませんが、
それに対してPythonは他方でのプログラミング環境でも優れており、②の観点からとても優れた言語であるといえます。
データとは?データの種類
大きく分類すると「定性的なデータ(質的データ)」、「定量的なデータ(量的データ)」にわけることができ、
さらに定性的なデータには、「名義尺度」、「順序尺度」にわけられ、定量的なデータには「感覚尺度」、「比例尺度」にわけることができます。
データの違いと例
| 定性的なデータ | 定量的なデータ | |||
|---|---|---|---|---|
| 名義尺度 | 順序尺度 | 間隔尺度 | 比例尺度 | |
| 説明 | 区別する言葉 | 数の順序、大小 | 間隔に意味がある | 物事の数値で表す |
| 性質 | 計算不可 | 大小比較可 | 差や和の計算可 比率の意味無し |
和、差、比率どれもできる |
| 例 | 名前、血液型 | スポーツの順位,アンケート(1.好き、2.やや好き・・) | 1日=24時間など、定義が決まっているもの | 身長、体重、各地の天気等々 |
スクレイピングとは
スクレイピングとは
「Scrape」は広範囲をゴシゴシこすりながら物をきれいにしたり、散らばった物を集めたりするニュアンスが近いです。
そこからコンピュータ用語に転じて、特定の目的を持ってWebやデータベースを広く探って「データを抽出する手法」のことを指すようになりました。
スクレイピングとクローリングの違い
スクレイピングが「特定の情報を抽出する」のに対し、クローリングは「巡回してWebの構造や要素を探る」点で大きな違いがあります。
Pythonの事前準備
Pythonのインストール
Windows
https://www.python.org/ftp/python/3.11.1/python-3.11.1-amd64.exe
2.手順に従ってインストール
Mac
Pythonの事前準備「requests」,「beautifulsoup4」ライブラリの取得
pip install requests
pip install beautifulsoup4を入力し実行
※正常にダウンロードされない場合
py -m pip install ***ネットワークが接続できない
set HTTPS_PROXY=http://proxy.example.com:8080
pip install **** ※認証が必要な場合
ユーザーとパスワードの入力が必要です。
ユーザー名:user パスワード:pass のとき
set HTTPS_PROXY=http://user:pass@proxy.example.com:8080
pip install ****詳しくは下記URL
https://gammasoft.jp/support/pip-install-error/
スクレイピング手順
今回実践としてQiitaのタグのランキングを取得してみましょう。
(使用するWebサイト:Qiitaタグ一覧:https://qiita.com/tags)
1.ページから取得したい情報を決める
取得したい情報を
- タグ名
- タグごとの記事数
- 記事数でのランキング
3つ取得すると仮定します。
2.欲しいデータの要素を調べる
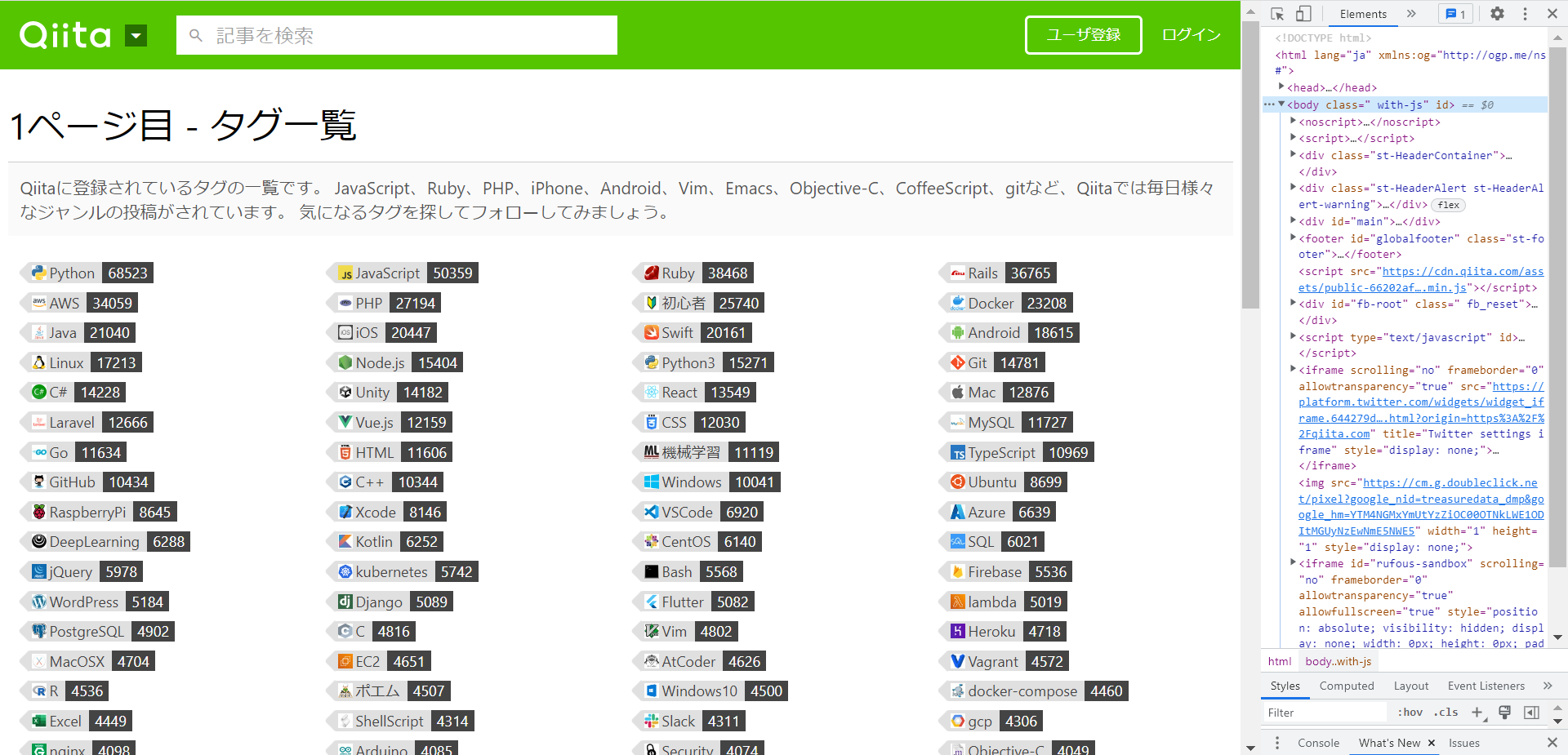
2.下記をクリックします。
青く光っているとOKです。
3.知りたい要素のパラメータをクリックします
クリックすると該当要素が左で青くハイライトされます。
これで知りたいパラメータの要素が
 Python
・・・・
Python
・・・・
必要なデータが、クラスが「TagList__item」の中の
・テキストのデータ(Python)
・タグ内の「data-count」のパラメータ(68440)
であることがわかりました。
ここからPythonのコードに入っていきます。
Pythonコーディング手順
サンプルコード
import requests
from bs4 import BeautifulSoup
url = "https://qiita.com/tags?page="
pageLength = 10
rank = 0
for page in range(pageLength):
req = requests.get(url+str(page)) #・・・①
soup = BeautifulSoup(req.content, "html.parser") #・・・②
tagsData = soup.findAll('div',class_='TagList__item')#・・・③
for tagData in tagsData:
rank +=1
count = tagData.get('data-count') #・・・④
tagText = tagData.text #・・・⑤
print(rank,'位:',tagText,' ',count,'件')①Webページにアクセスする
以下のWebのデータをレスポンスとしてもらっています。
Responseオブジェクト
├url: url属性
├ステータスコード: status_code属性
├エンコーディング: encoding属性
├レスポンスヘッダ: headers属性
├テキスト: text属性
└バイナリデータ: content属性
requestsの使い方の詳細は以下URL
②BS4で取得したWebデータを指定した形式で(今回はhtml)取得する
BeautifulSoup(解析対象のHTML/XML, 利用するパーサー)を使うことによって、Webページの要素を取得することができます。
使用できるパーサー
| パーサー | 引数での指定方法 | 特徴 |
|---|---|---|
| Python’s html.parser | “html.parser” | 追加ライブラリが不要 |
| lxml’s HTML parser | “lxml” | 高速に処理可 |
| lxml’s XML parser | “xml” | XMLに対応し、高速に処理可 |
| html5lib | “html5lib” | 正しくHTML5を処理可 |
今回は「Python’s html.parser」を使用します
③指定したタグでページ内のデータを抽出する
要素を指定して、欲しい要素のみに抽出していきます。
全体の要素という「スープ」から、必要なデータ「具材」を掬い取るイメージです。
取り出した要素.findAll(絞り込みたいタグ名[,追加条件])ここではタグが「div」であり、クラスが「TagList__item」である要素を抽出しています。
今回はタグに一致する要素を全て抽出するため「findAll」を使っていますが、
他にも以下が使用できます。
.find(タグ名[,追加条件])タグ、条件に合致した要素をすべてリストで取得
.find_all(タグ名[,追加条件])CSSセレクタに合致した要素をすべてリストで取得
.select(“CSSセレクタ”)また、抽出した要素から再度抽出することが可能です。
originalSoup = BeautifulSoup(req.content, "html.parser")
soup1 = originalSoup.find("a")
soup2 = soup1.findAll("div")④抽出したデータのタグの値を取得する
tagData.get(タグ名)このようなタグ内のパラメータ、ハイパーリンクのURLを取得するために用いられることが多いです。
tagData.get("href")⑤抽出したデータのタグ以外、textデータを取得する
テキストを抽出したい要素.text実行結果
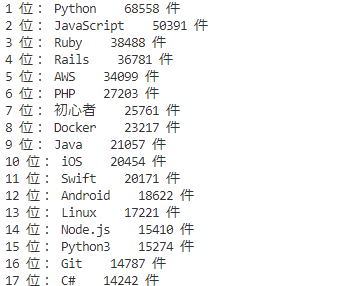
最後に
今回使用したBeautifulSoupには、まだまだほかの抽出方法などがあり、自由に収集できますので、
興味を持っていただけたら是非挑戦してみてください!
beautifulSoup公式ドキュメント:http://kondou.com/BS4/
明日はmiyajimayさんの
「Auth0ダッシュボードからメトリクスを見れるようになったらしい 」です!
お楽しみに!
