







はじめて理解するdbt
近年DXへの関心の高まりに伴い、データ活用の重要度は高まってきています。
しかし、データベースに存在するデータを可視化したりBIツールなどで利用できる状態に整えるためには、
膨大な量のSQLを管理したり、SQLを実行するワークフローを構築する必要があり、データの管理が課題となりやすい傾向にあります。
dbtはこのデータを管理するプロセスにおいて、業務効率を大きく向上させるツールとして注目を浴びています。

目次
はじめに
こんにちは。モバイルソリューショングループの nakada.r です。
本記事ではdbtとは何なのか全く知らない状態から、実際の例を見でざっくり概要を理解した状態になることをゴールとしています。
dbtが気になっている方の入門記事として参考にしていただければ幸いです。
dbtとは?
dbtとはdata build toolの略で、データ統合を行う際のプロセスであるELT(抽出, 変換, 格納)のうちTransform(変換)の役割を担うツールです。Transformのプロセスでは一般的にデータウェアハウスなどに抽出したデータを下流の分析ツールやデータベースで利用できる形式に変換・加工する処理を行います。
dbtはこの工程で役に立つ様々な機能を提供してくれます。
dbtでできること
ではdbtが提供している代表的な機能を確認してみましょう。
モデルの構築
SELECT文を使用したSQLファイルを作成することによりモデルを構築できます。
また、ウェアハウス上に存在するテーブルやビューだけでなく他のdbtモデルを参照してSQLを記述することができます。
SQLファイルにはテンプレート言語であるJinjaを含めることができ、forループやif文といった制御構造を使用することでより柔軟にクエリを作成することができます。
実行順序の制御
dbtで用意されているref関数を使用することで、モデルを処理する順番を制御することができます。
これにより明示的にモデルを処理する順序を指定しなくても、dbtがモデルの依存関係を考慮した順序で処理を実行してくれます。
モデルのテスト機能
モデルによって生成される結果に対してテストを実行することができます。
YAMLでテストを定義することで、指定したカラムがユニークな値になっているか、nullの値が含まれていないかなどを確認し、
モデルで記述したSQLの整合性が取れているかを継続的に確認できます。
dbtプロジェクトのドキュメンテーション
プロジェクトのドキュメントを生成することで、プロジェクトのバージョンニングを行い、チーム内で共有することができます。
プレーンテキストやマークダウン形式でモデルやフィールドの説明を記載したり、モデルの依存関係を図で可視化することもできます。
この他にもdbtコードのパッケージ管理、データのスナップショットの作成機能などデータの管理・運用に役立つ様々な機能が提供されています。
dbtの利用環境
dbtを利用する場合は、以下2つの製品から用途に適したものを選択できます。
dbt Core
dbt CoreはApache License 2.0で利用可能なOSSです。
実行環境を用意した上でCLIでインストールすることによって使用できます。
dbt Cloud
dbt Cloudはdbt CoreをベースとしたSaaS製品で、あらかじめ用意されたWebベースのUIから実行できます。
IDE(統合開発環境)の利用、gitでのプロジェクト管理、スケジューリングしたジョブの自動実行などはdbt Cloudのみで提供されている機能です。
料金プランはDeveloper, Team, Enterpriseで分かれており、個人利用であれば無料で使用できます。(料金プランの詳細はコチラ)
dbtを触ってみる
では実際にdbtの公式チュートリアルに沿ってdbtの動きを見てみましょう。
今回はdbt Cloudを利用してBigQueryに保管されているサンプルデータを対象に
- モデルの作成
- テストの実行
- プロジェクトのドキュメンテーション
を行なっていきます。
なお、dbtの全体の機能や流れをざっくり理解していただく目的のため、
BigQueryの設定やdbt Cloudアカウントの作成など細かい説明は省略します。
(詳細な手順や設定が気になる方は公式チュートリアルを参照してくださいmm)
モデルの作成
最初にdbtを通じてテーブルやビューを作成する際の基本となるモデルを作成する手順を見てみましょう。
dbt CloudのIDEは以下のような画面となっており、プロジェクト内のフォルダ・ファイルを編集したり、コマンドプロンプトでdbtコマンドを実行できるようになっています。
プロジェクトを作成した段階でどんなフォルダがあるか一度目を通しておきましょう。
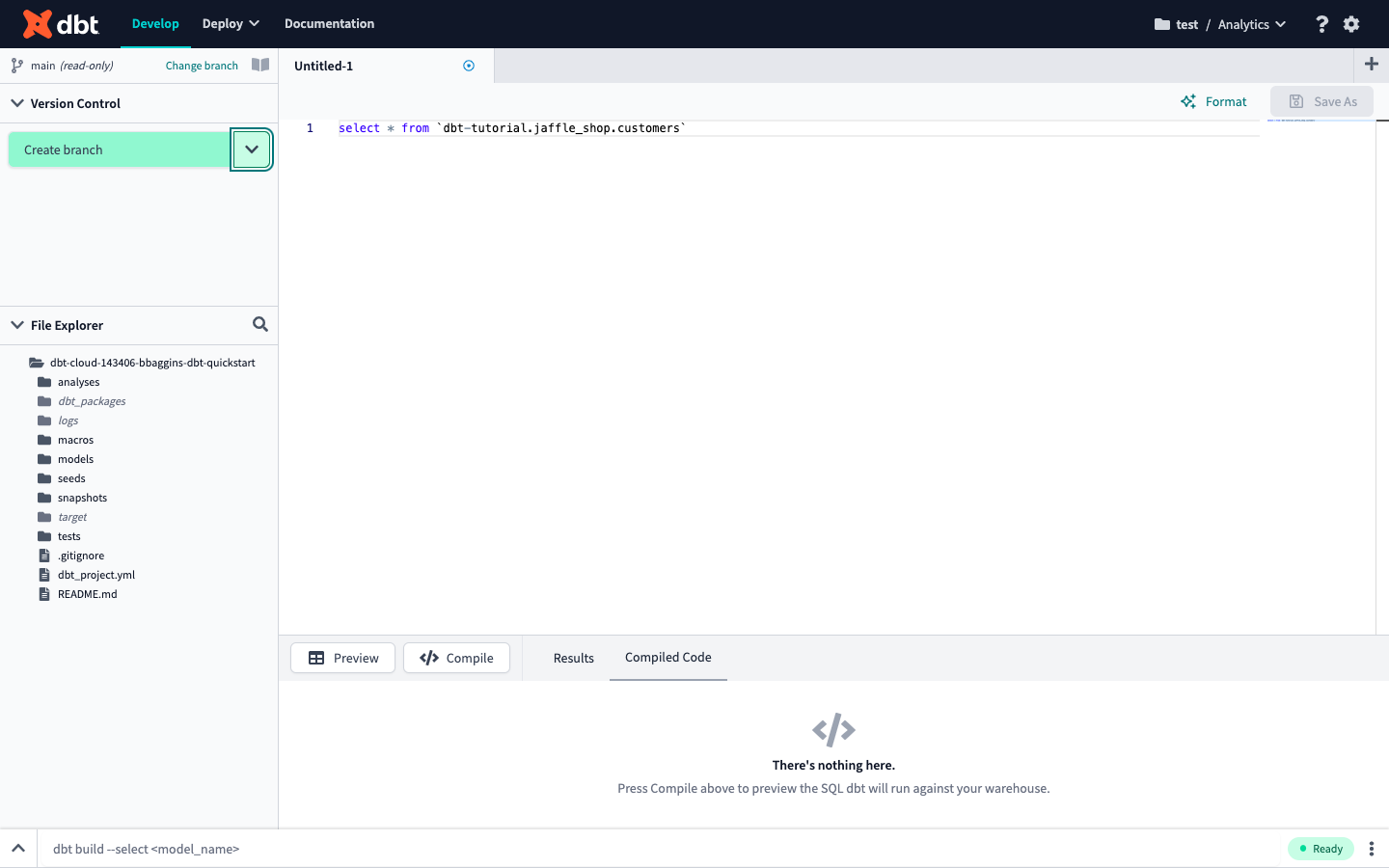
最初に以下のようなSQLファイルでモデルを作成して実行してみます。
with customers as (
select
id as customer_id,
first_name,
last_name
from `dbt-tutorial`.jaffle_shop.customers
),
orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from `dbt-tutorial`.jaffle_shop.orders
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
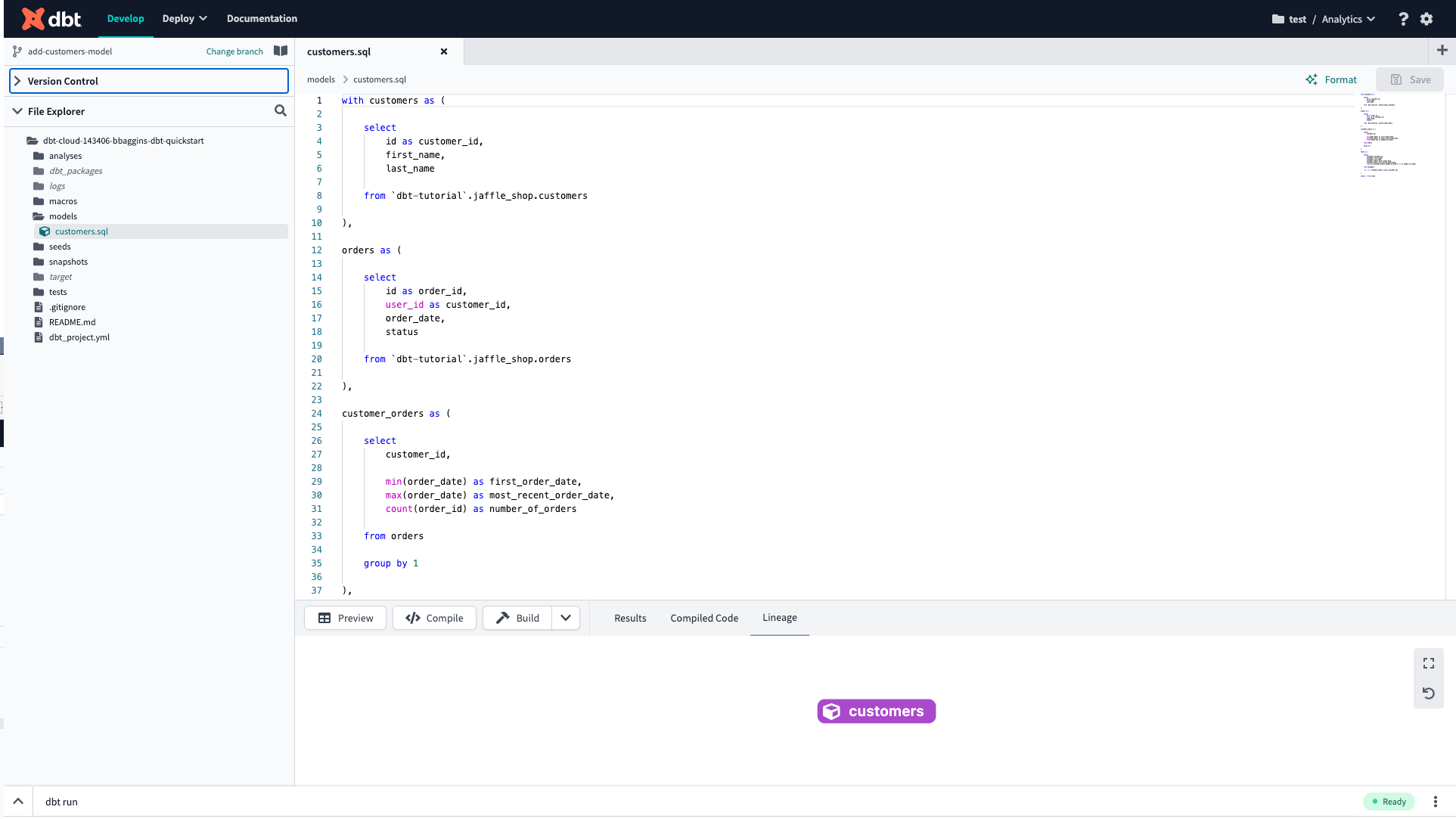
customers テーブルと orders テーブルから値を取得して集計したデータを集計して表示する 、一般的なSELECT文とCTEを利用したクエリですね。
画面下部のコマンドプロンプトから dbt runコマンドを実行することで接続先のBigQuery上にViewが作成されます。
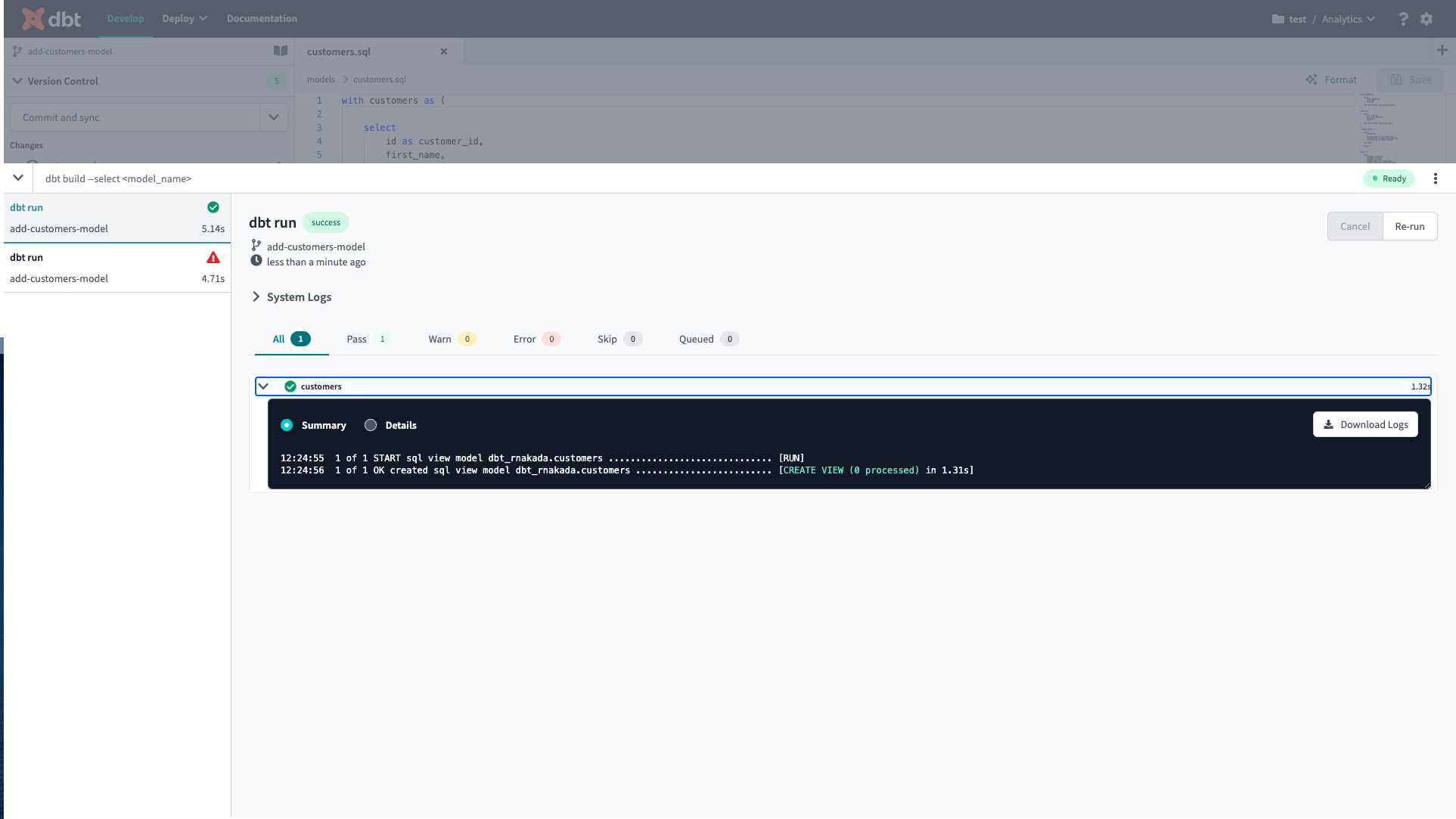
Viewではなくテーブルを作成したい場合は dbt_project.ymlのモデルの設定を変更することでマテリアライズの方法を変更できます。
~~ 省略 ~~
models:
jaffle_shop:
+materialized: table
このようにDDLに変更を加えなくても設定ファイルから出力先をTable/Viewで切り替えられるのもdbtの強みの一つです。
モデルの作成 ~ロジックの分離編~
dbtでは実行するロジック毎にモデルを分割することでSQLをより簡潔に記述することができます。
先に models/customers.sql として作成していたクエリは以下のように3つのモデルのSQLファイルに分割できます。
select
id as customer_id,
first_name,
last_name
from `dbt-tutorial`.jaffle_shop.customers
select
id as order_id,
user_id as customer_id,
order_date,
status
from `dbt-tutorial`.jaffle_shop.orders
with customers as (
select * from {{ ref('stg_customers') }}
),
orders as (
select * from {{ ref('stg_orders') }}
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
テーブルからデータをSELECTするロジックを models/stg_customers.sql と models/stg_orders.sql に切り出して、
それらの値を models/customers.sql で集計するような構成となっています。
ここで注目していただきたいのは models/customers.sql のFROM句で {{ ref('stg_customers') }}, {{ ref('stg_orders') }} といったようにref関数を使用してモデルを参照している点です。
ref関数を使用すると、dbtがSQLをコンパイルする際に参照するモデルの依存関係を確認しクエリの実行順序を自動的に判定してくれます。
こちらも同様に dbt run で実行してみると以下のような実行結果になります。
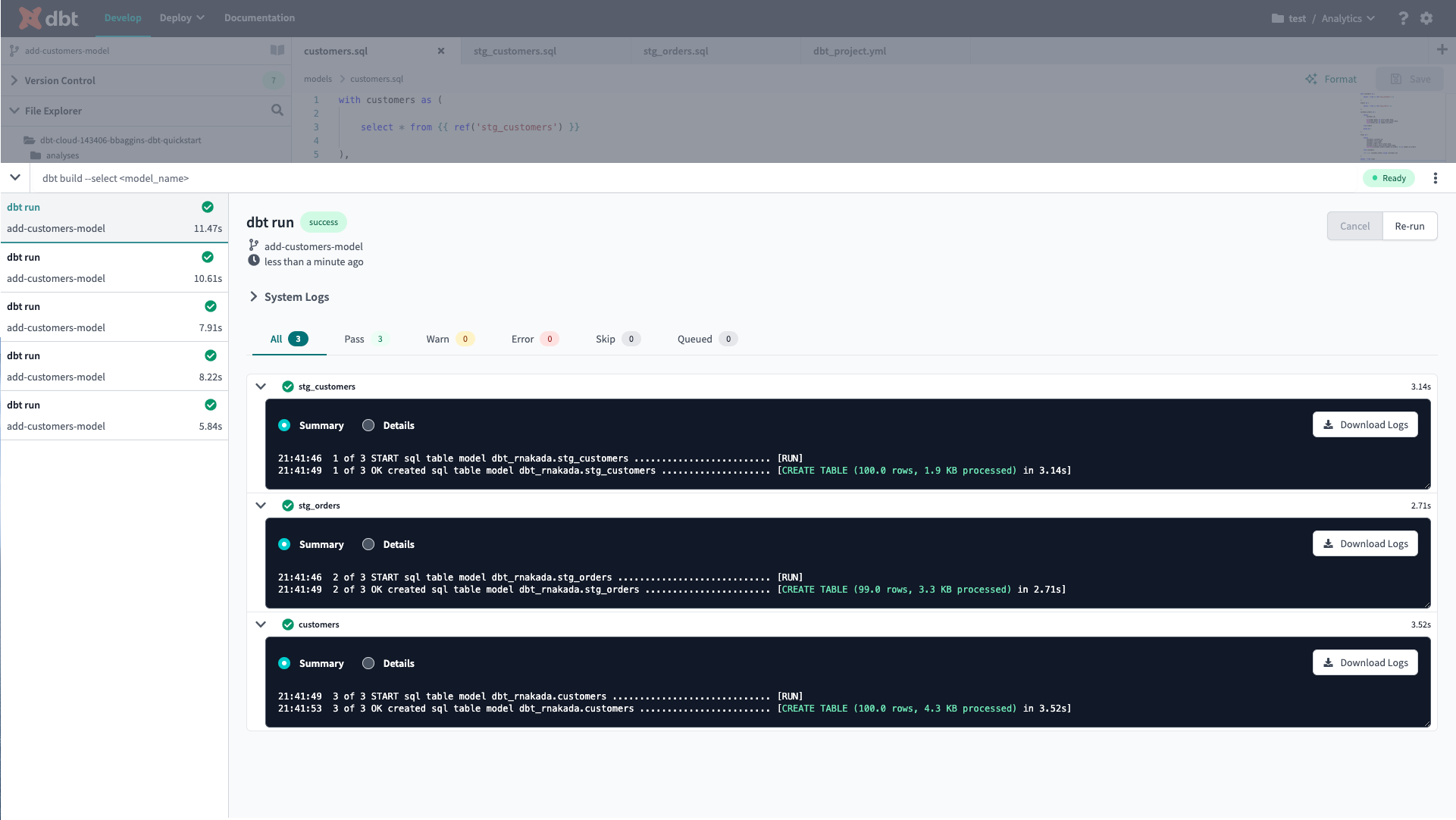
実行するSQLファイルの順番は指定していませんが、ref関数の働きによりテーブルの値を取得するクエリを実行した上で集計するクエリが実行できていることを確認できました!
このようにクエリファイルを分割することによって役割毎にロジックを分離することができます。
また、複雑な依存関係を持ったロジックでも実行順序を気にすることなくクエリを記述することができます。
テストの実行
クエリを変更した際には、変更の結果期待する結果(テーブルやビュー)が得られるか確認する必要があります。
models/schema.ymlファイルを作成することでモデル毎の出力結果のテストを作成することができます。
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_null
- name: stg_customers
columns:
- name: customer_id
tests:
- unique
- not_null
- name: stg_orders
columns:
- name: order_id
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
- name: customer_id
tests:
- not_null
- relationships:
to: ref('stg_customers')
field: customer_id
ここでは全レコードのそれぞれのカラムに対して値がユニークか、nullが含まれていないか、想定した値が格納されているか、カラムの値が指定したテーブルのフィールドと対応しているかといったテスト実行する記載をしています。
上記ファイルを作成した上で dbt test コマンドを実行することで、使用するモデルそれぞれの結果に対してテストを行えます。
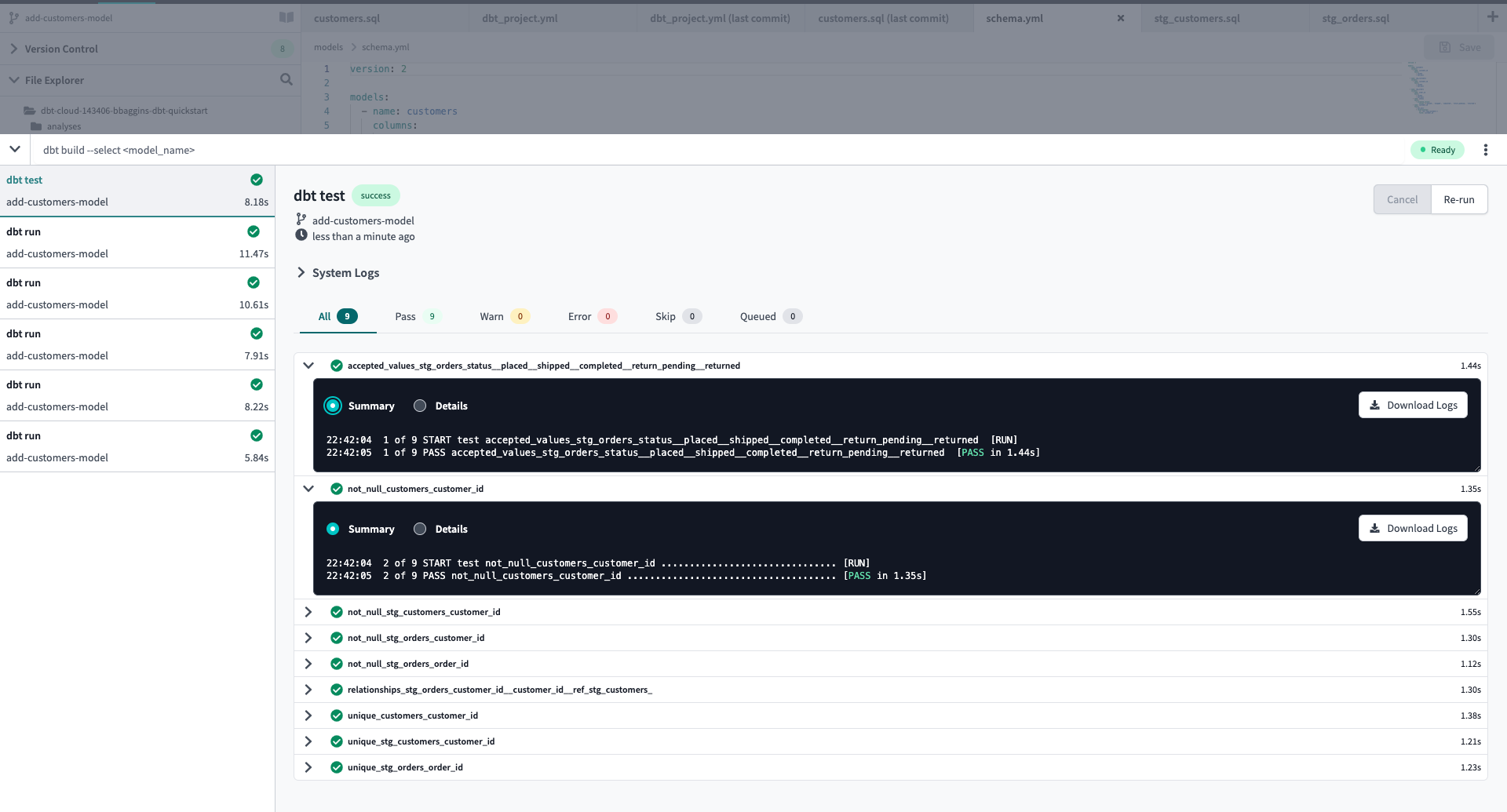
クエリの変更に伴う結果の整合性をシステム的に担保できる点がdbtのテスト機能の大きな魅力です。
ドキュメントの作成
プロジェクトのドキュメント機能によって各モデルの説明の記載したり、モデル同士の関係性を可視化することができます。
また、作成したドキュメントをチーム内で共有することもできます。
テストで作成した models/schema.yml を以下のように変更します。
version: 2
models:
- name: customers
description: One record per customer
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: first_order_date
description: NULL when a customer has not yet placed an order.
- name: stg_customers
description: This model cleans up customer data
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: stg_orders
description: This model cleans up order data
columns:
- name: order_id
description: Primary key
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
各モデルやそれらに含まれるカラムの説明を追記したものになっています。
dbt docs generate コマンドを実行しドキュメントの生成が完了した後、
UI上からドキュメントが確認できるようになります。
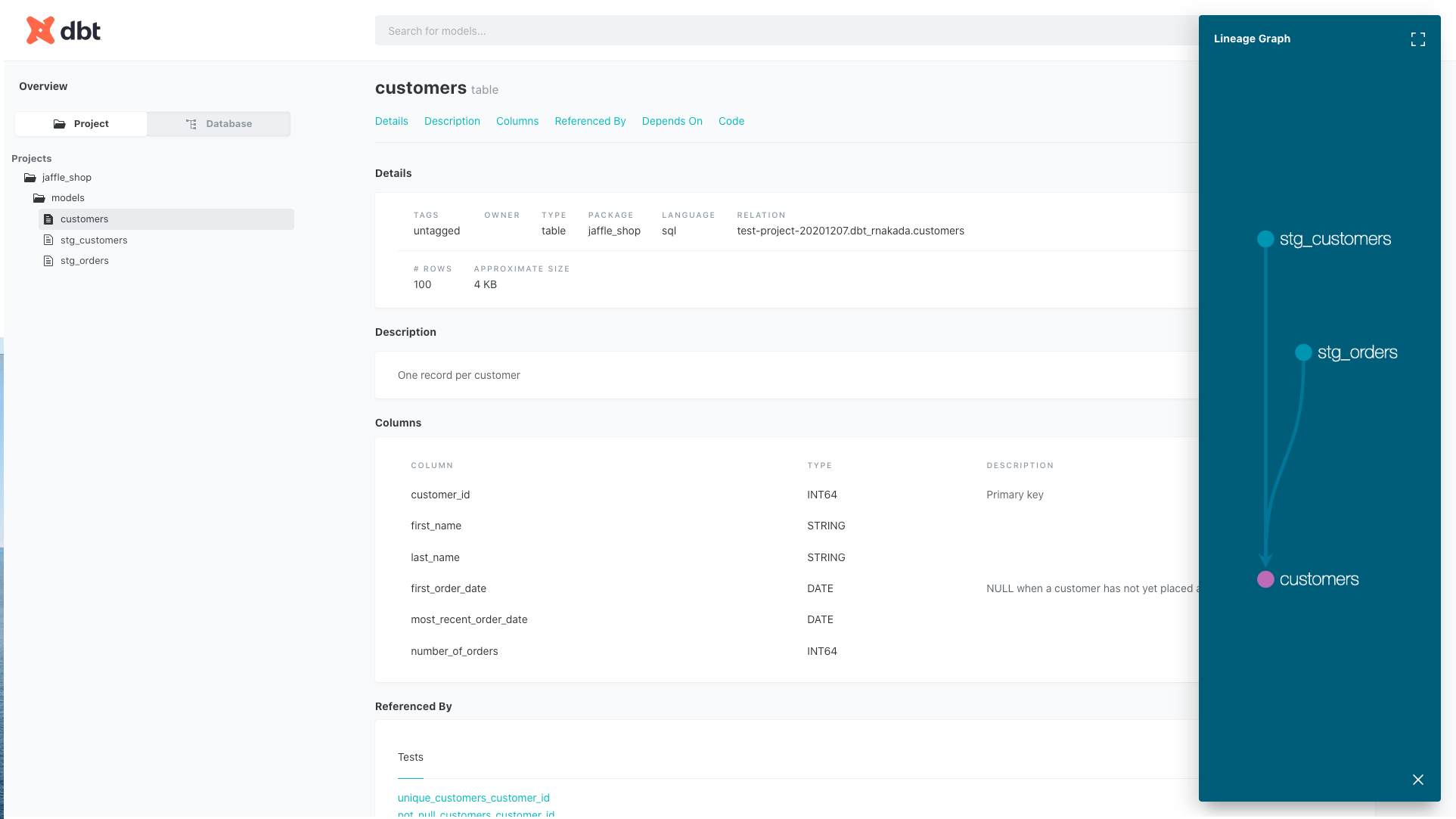
テーブル・ビューの定義や関係性が資料として確認できるようになるためチームでの情報共有に役立つ機能となっています。
おわりに
今回はdbtの簡単な機能のみの紹介となりましたが、テスト機能やドキュメント作成機能などデータ運用における課題を解決する手助けをしてくれる機能が盛り沢山だなと感じました。
今回紹介した機能以外にもdbtプロジェクトのGit管理やジョブ管理など、開発・運用に役立つ様々な機能が存在しますので、
興味を持っていただけた方は是非調べてみてください!
