







PaLM2が日本語対応したので試してみた

8/23のGenerative AI Summit Tokyoにて、
Googleの生成AIである、PaLM2の日本語対応が発表されました。
文章生成AIについては当日中に利用可能に、
テキストエンベディング(詳細は後述)もプレビュー公開が8/29に行われましたので、
これらを活用した、アイソルート技術者ブログの類似度検索エンジン&検索結果要約システムについてお伝えさせていただきます。
目次
はじめに
テキストエンベディング(文章のベクトル化機能)とは?
類似度検索とは?
ブログの類似度検索エンジン
要約機能の実現
はじめに
こんにちは。IPコミュニケーショングループのshimazaki.hです。
普段はデータ活用や分析に関しての業務に従事させていただいております。
まずは、PaLM2について紹介します。
PaLM2は、OpenAI社のGPTやMetaのLLaMAなどと同様な大規模言語モデル(LLM)です。
詳細はGoogleのブログ等でも紹介されておりますので、
こちらをご確認ください。
https://japan.googleblog.com/2023/05/palm-2.html
本記事では、
- PaLM2のテキストエンベディング
(文章のベクトル化機能。なお、2023/9/8時点では多言語対応はまだプレビューです。) - 文章生成機能
この2つの機能を活用して、本ブログの検索機能と要約機能を実装します。
なお、今回の内容では数学的な話しにも触れるのですが、
なるべく概要だけお伝え出来る様にしたいと思います。
テキストエンベディング(文章のベクトル化機能)とは?
本題に入る前に、テキストエンベディングについて説明します。
昨今の自然言語処理では、単語や文章を、その意味など何らかのルールに基づいた形で、
数値としての表現に置き換えてから処理するという傾向があります。
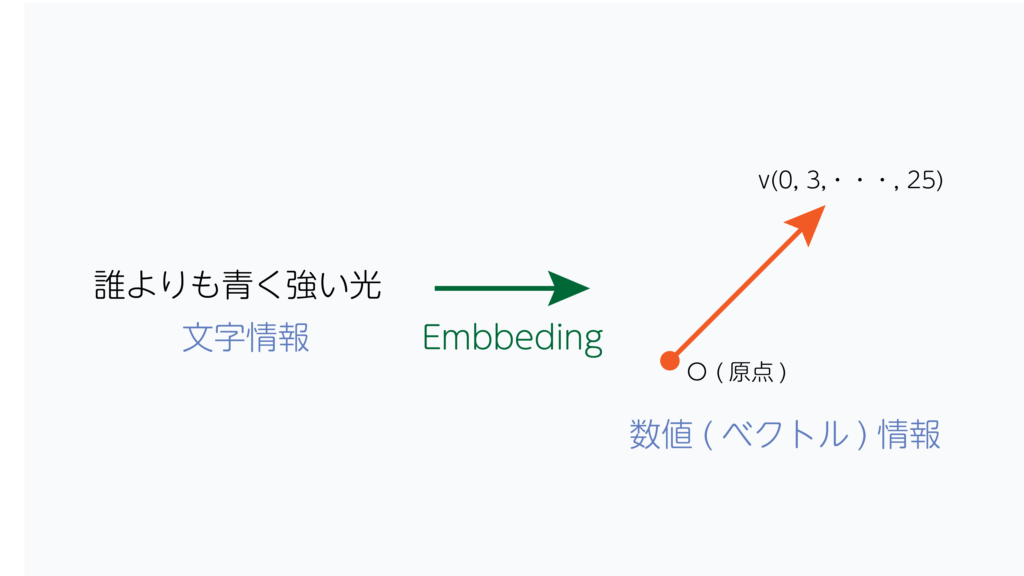
これは、自然言語処理に用いられるような、
機械学習は最適化数学が基礎にあるためです。
最適化数学はあるルールに基づいて表現される数列(ベクトル)の集合に対して、
最も適したルールを見つけ出すための数学分野です。
以上より、文章を入力とする場合、文字をそのまま扱うのではなく、
ベクトルへ変換してから扱うほうが都合がよいです。
この変換のことをテキストエンベディングと言います。
PaLM2のテキストエンベディングの場合、
意味の近いものは近似のベクトルの向きとなるように変換され、
768次元(1つの文章あたり、768個の数字の塊)のベクトルとなります。
類似度検索とは?
本題のブログの検索に用いるアルゴリズムについてですが、
今回はベクトル類似度(コサイン類似度)検索というアルゴリズムを利用します。
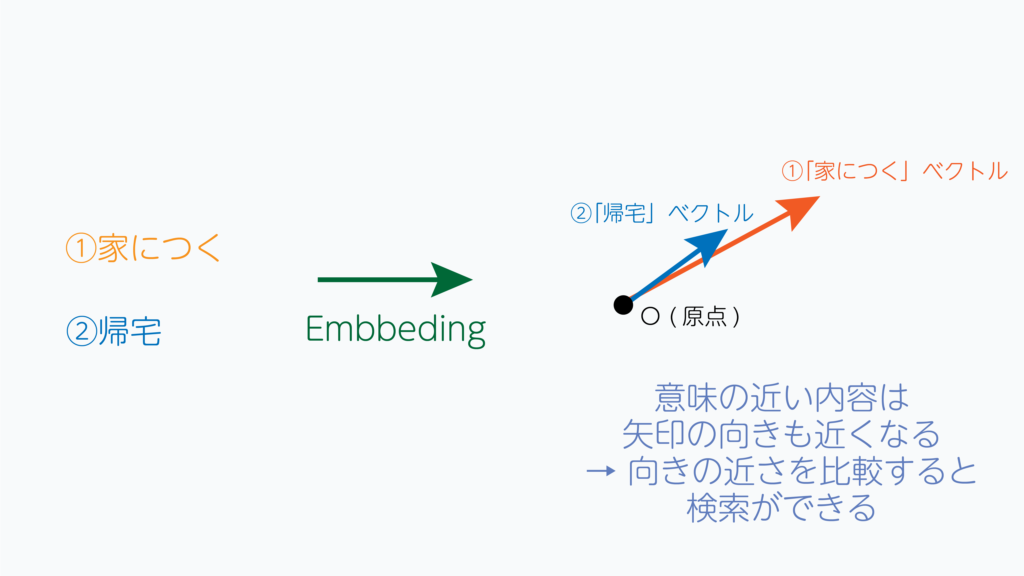
コサイン類似度は、2つのベクトルがどの程度似ているかを測る尺度を示します。
ベクトルの向きが同じであれば、コサイン類似度は1になります。ベクトルの向きが正反対であれば、コサイン類似度は-1になります。
前節の説明より、文章や単語の内容が近い=ベクトルが近い方向に向いていると言えるため、
検索したい単語・文章をエンベディングし、コサイン類似度の高い文章を計算することで、
知りたい内容を得られる可能性が高くなります。
ブログの類似度検索エンジン
前節で説明したコサイン類似度を用いてブログの検索エンジンを実装します。
戦略としては以下の3段階となる想定です。
- ブログ記事そのものを予めベクトルに変換しテーブル化しておきます。
- 検索したい文言を変換したベクトルと、予め用意したテーブルのコサイン類似度をテーブルの1文章づつ計算します。
- 類似度の高い順で文章を参照することで検索結果を確認出来ます。
(余談ですが、検索の意味合い的にはAND検索に近い動作とはなります。)
1.ブログ記事のベクトル化
まず、ブログ記事をエンベディングする必要があるのですが、
8月末までのブログ記事のうち、h系タグとpタグをメインに抽出をおこないます。
pタグの本文については、細かく区切られている記事もあるため、
ヘッダー区切りで文章をひとまとめにします。
これらひとまとめにした本文を、それぞれエンベディングすることで検索される側の準備は完了です。
PaLM2を用いてベクトル化の際、Vertex AIのドキュメントのGet text embeddingsを参考に下記のようにメソッドを構築すると便利です。
from vertexai.language_models import TextEmbeddingModel
def text_embedding(embedding_text: str) -> list:
"""Text embedding with a Large Language Model."""
model = TextEmbeddingModel.from_pretrained("textembedding-gecko-multilingual@latest")
embeddings = model.get_embeddings([embedding_text])
for embedding in embeddings:
vector = embedding.values
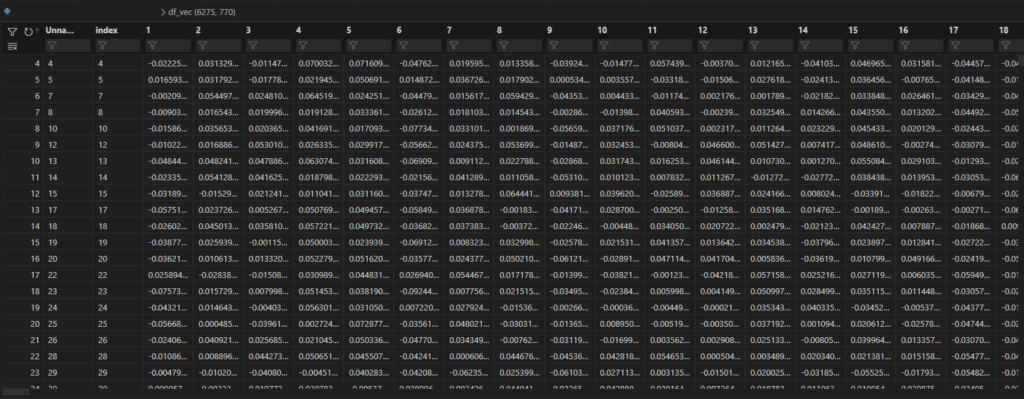
return vector ベクトル化すると下図のようなベクトルを得ることができます。
(ひとまとめにした文章の分だけ行を追加しているため、行数が多量になっています。)
2.検索したい文字列もベクトル化
こちらはシンプルに、入力された文言をそのままベクトル化します。
前節で触れたメソッドにそのままテキストを入力することでベクトル化できます。
# 検索ワードをベクトル化
serch_vector = text_embedding(serch_word)3.類似度の高い順で文章を参照する
コサイン類似度を計算します。
先述の計算式をコードに落とし込むのですが、
numpyを活用して実装する際の工夫として、下記のような実装を施す事で、
高速で演算をすることが可能です。
# 検索ワードをベクトル化
serch_array = []
# ブログ記事テーブルと同じ行数分のベクトルにコピー
for i in range(len(base_array)):
serch_array.append(serch_vector)
# numpyのndarrayへ変換
serch_array = np.array(serch_array)
# 結果の受け皿を用意
result = np.array([])
# 結合関数内で、つど類似度計算させる
result = np.concatenate([result, np.sum(serch_array*base_array, axis=1)/(np.linalg.norm(serch_array, axis=1) * np.linalg.norm(base_array, axis=1))], 0)参考資料: どこにでもいるSEの備忘録 Numpyでcos類似度の計算を高速化する
要約機能の実現
オマケ程度ですが、PaLM2の文章生成機能を活用することで、
(場合によってですが)文章を要約することが出来ます。
ここは、ChatGPT等では定番のプロンプトエンジニアリングを活用することで実現出来ます。
今回もちいたプロンプトを下記に示します。
与えられた文章を元に、ある単語についてまとめる作業を行ってください。
以下の文章1、文章2、文章3をもとに、{入力された検索文言}についてまとめてください。
文章1: {類似性が最も高い文章}
文章2: {類似性が二番目に高い文章}
文章3: {類似性が三番目に高い文章}このように検索結果上位3件の文言を要約させるといった流れとなります。
検索結果が説明に十分な内容の場合は要約された文章が返され、
不十分な内容の場合は、PaLM2側で予め学習済みのデータを基に返答されます。
適当にUI周りも含めて実装するとこのような形となります。
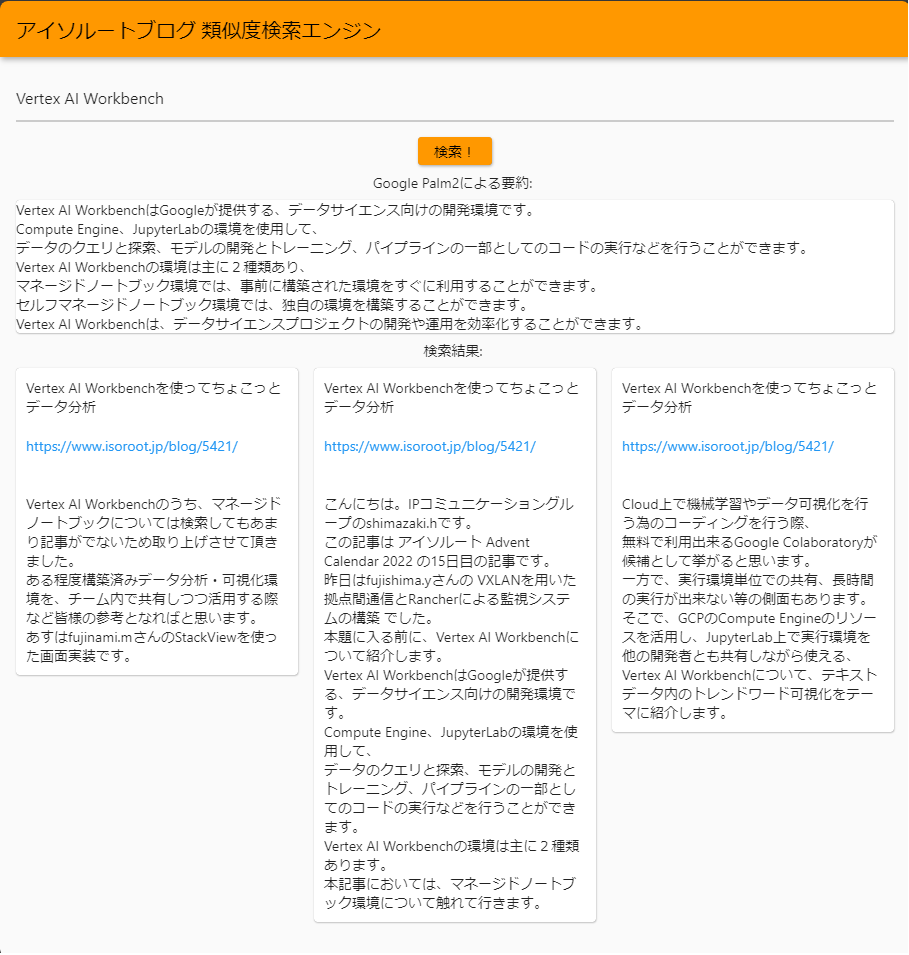
エビデンス欄に今回欲しているページのリンクが表示され、
上手くいくと要約のところに知りたい情報も得られるという1つで2度お得なものが出来上がります。
まとめ
今回PaLM2を用いて実装した内容はRetrieval Augmented Generation(RAG)と呼ばれる、
外部の情報元を用いた生成AIの活用方法の1つです。
PaLM2に限らず生成AIの傾向として、学習に用いたデータに基づいて回答を行うため、
質問に対して、正しい回答ができるかわからないという課題が発生しますが、
今回のようなモデルを構築することでこれらの課題の克服に一歩近づくことが可能です。
よろしければ、本記事をご覧いただいた皆さんも生成AIを活用して、
業務改善やデータ分析に役立てていただければと思います。
長くなりましたが、最後までご覧いただきありがとうございました。
