







Azure OpenAIの力を引き出す!ベクトル&セマンティック検索で回答精度を劇的改善

Azure OpenAIを業務で活用しようとすると、生成AIはあらかじめ学習しておいたことしか回答できず、
業務特有の用語や実測した数値に基づいて回答を行うことはできません。
それを解消するアプローチとして RAG(Retrieval-augmented generation/検索拡張生成) が広く知られており、
Azure OpenAI では Azure AI Search と組み合わせることで実現することが可能です。
しかし、デフォルトではいくつか課題もあるため、それを改善する手法を紹介していきましょう!
(実例では SharePoint Online との連携を含めて紹介します)
目次
はじめに
こんにちは。クラウドソリューショングループのwatanabe.tです。
今回は生成AIをさらに活躍させるための工夫について見ていきましょう。
デフォルトのAzure AI Searchの検索は、単純な「キーワード検索」です。
もちろんこの状態でもある程度の精度で回答をドキュメントから見つけ、GPTがドキュメントに基づいた回答をする手助けをしてくれます。
ただ、似た意味を持つ異なる単語が含まれていてもスコアが低く出てしまったり、文脈を理解していないためにユーザーの意図と真逆の回答をしてしまったり、
曖昧なクエリや同義語・多義語が含まれる場合は検索結果が不正確になってしまうことがありました。
このような課題を解決するため、今回紹介するベクトル検索とセマンティック検索が注目されています。
これらの手法を利用すると、データ・クエリの意味やコンテキストを理解することで、ユーザーの意図に沿った検索結果を提供してくれます。
ベクトル検索とは?
まず具体的にベクトル検索とは何なのか、から見ていきましょう。
ベクトル検索はデータを数値的なベクトルとして表現し、これを基に検索を行う手法です。
単純な文字列マッチングではなく、データの「意味」や「似た使われ方をする」といった関連性に基づいて、類似する項目を検索します。
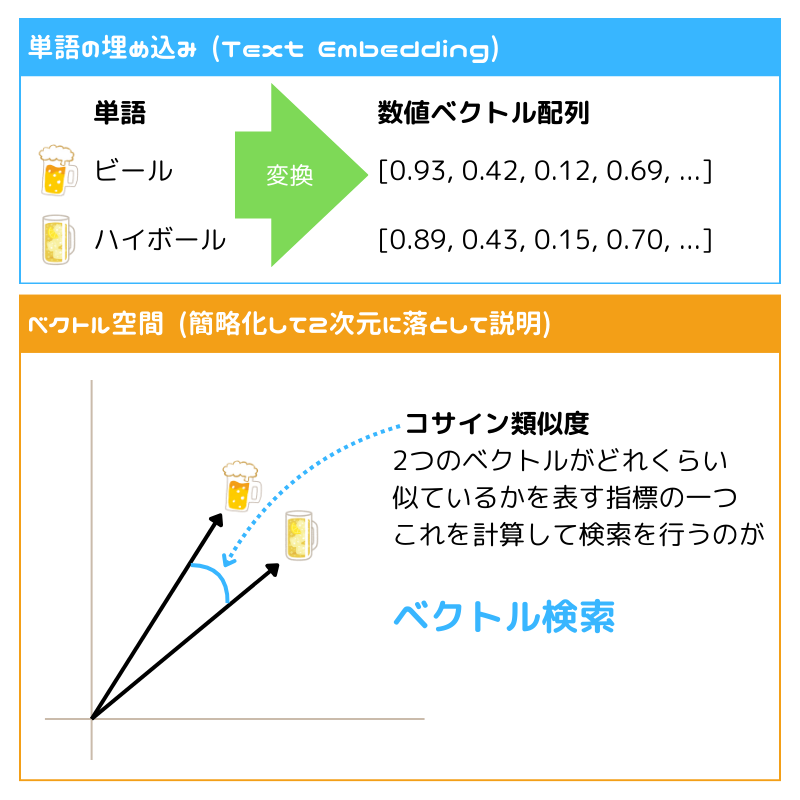
しかし、これだけだと単語それぞれにフォーカスするのみで、ユーザーの検索意図や文脈を理解しての検索は行えません。
そこで登場するのが「セマンティック検索」です。
セマンティック検索とは?
では次にセマンティック検索の解説をしていきましょう。
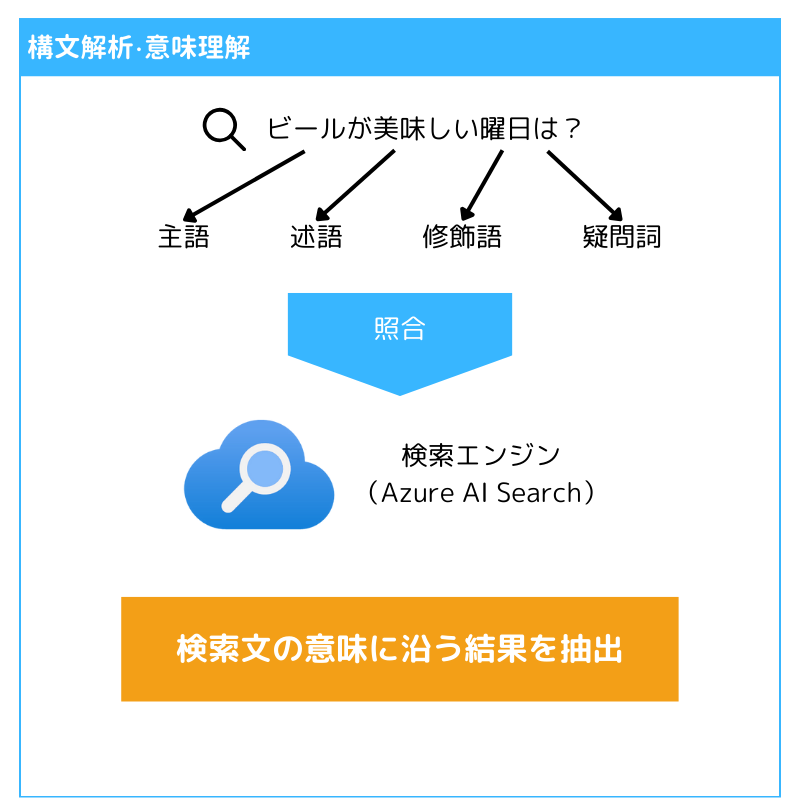
セマンティック検索は単なる文字列の一致ではなく、クエリの意図を理解して検索結果を提供する手法です。
構文解析・意味解析などを行いつつAIがスコアを算出することで、単なる単語の出現頻度や出現集中度以外も考慮し、より的確な結果を提供します。
これにより、カスタマーサポートのチャットボットや、膨大なドキュメントから関連情報を迅速に引き出すドキュメント検索など、クエリの意味を理解し、適切な応答を返すことが求められるシーンでより質の高い回答をすることができるようになります。
Azure OpenAI におけるベクトル検索とセマンティック検索の実現
ここからは実際の Azure ポータルの画面を交えつつ、 Azure OpenAI でベクトル検索・セマンティック検索を活用する方法を紹介していきます。
なお、データソースの設定は既に設定済みのものとしますので、公式の手順を参考にしてください。
SharePoint Online Indexer
まずはインデックス・インデクサーの設定を行います。
ベクトル変換自体は Azure OpenAI Service の Text Embedding モデルを利用するため、これも事前に別途デプロイしておきます。
インデックス設定
{
"@odata.context": "https://.search.windows.net/$metadata#indexes/$entity",
"@odata.etag": "\"\"",
"name": "",
"defaultScoringProfile": null,
"fields": [
{
"name": "id",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": true,
"facetable": true,
"key": true,
"indexAnalyzer": null,
"searchAnalyzer": null,
"analyzer": "keyword",
"normalizer": null,
"dimensions": null,
"vectorSearchProfile": null,
"vectorEncoding": null,
"synonymMaps": []
},
...,
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false,
"key": false,
"indexAnalyzer": null,
"searchAnalyzer": null,
"analyzer": null,
"normalizer": null,
"dimensions": null,
"vectorSearchProfile": null,
"vectorEncoding": null,
"synonymMaps": []
},
{
"name": "vector", // ベクトル変換後の配列を格納するフィールド
"type": "Collection(Edm.Single)",
"searchable": true,
"filterable": false,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false,
"key": false,
"indexAnalyzer": null,
"searchAnalyzer": null,
"analyzer": null,
"normalizer": null,
"dimensions": 1536, // text-embedding-ada-002 だと1536次元、text-embedding-3-large だと最大3072次元
"vectorSearchProfile": "vector-profile-1724745229934",
"vectorEncoding": null,
"synonymMaps": []
},
{
"name": "chunk",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false,
"key": false,
"indexAnalyzer": null,
"searchAnalyzer": null,
"analyzer": "standard.lucene",
"normalizer": null,
"dimensions": null,
"vectorSearchProfile": null,
"vectorEncoding": null,
"synonymMaps": []
}
],
"scoringProfiles": [],
"corsOptions": null,
"suggesters": [],
"analyzers": [],
"normalizers": [],
"tokenizers": [],
"tokenFilters": [],
"charFilters": [],
"encryptionKey": null,
"similarity": {
"@odata.type": "#Microsoft.Azure.Search.BM25Similarity",
"k1": null,
"b": null
},
"semantic": { // セマンティック検索の設定
"defaultConfiguration": null,
"configurations": [
{
"name": "sharepoint-semantic-config",
"prioritizedFields": {
"titleField": {
"fieldName": "metadata_spo_item_name"
},
"prioritizedContentFields": [
{
"fieldName": "content"
}
],
"prioritizedKeywordsFields": []
}
}
]
},
"vectorSearch": {
"algorithms": [
{
"name": "vector-config-1724745233391",
"kind": "hnsw",
"hnswParameters": {
"metric": "cosine",
"m": 4,
"efConstruction": 400,
"efSearch": 500
},
"exhaustiveKnnParameters": null
}
],
"profiles": [
{
"name": "vector-profile-1724745229934",
"algorithm": "vector-config-1724745233391",
"vectorizer": "vectorizer-1724745240528",
"compression": null
}
],
"vectorizers": [
{
"name": "vectorizer-1724745240528",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": "https://.openai.azure.com",
"deploymentId": "",
"apiKey": "",
"modelName": "",
"authIdentity": null
},
"customWebApiParameters": null,
"aiServicesVisionParameters": null,
"amlParameters": null
}
],
"compressions": []
}
}インデクサー設定
{
"@odata.context": "https://.search.windows.net/$metadata#indexers/$entity",
"@odata.etag": "\"\"",
"name": "",
"description": null,
"dataSourceName": "",
"skillsetName": "",
"targetIndexName": "",
"disabled": null,
"schedule": null,
"parameters": {
"batchSize": null,
"maxFailedItems": null,
"maxFailedItemsPerBatch": null,
"base64EncodeKeys": null,
"configuration": {
"indexedFileNameExtensions": ".xlsx, .pdf, .jpg, .pptx", // インデックス対象のファイル拡張子
"excludedFileNameExtensions": "",
"dataToExtract": "contentAndMetadata"
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_spo_site_library_item_id",
"targetFieldName": "id",
"mappingFunction": {
"name": "base64Encode",
"parameters": null
}
}
],
"outputFieldMappings": [],
"cache": null,
"encryptionKey": null
}
次に、インデクサーがデータを格納するときにベクトル変換を行うため、スキルセットの定義をしておきます。
スキルセット設定
{
"name": "",
"description": "",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill", // ベクトル変換はサイズ制限があるため、まずはテキストを適切なチャンクに分割
"name": "#1",
"description": "Split skill to chunk documents",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/content", // 変換元のコンテンツのパス
"inputs": []
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages" // 変換後のコンテンツ
}
],
"defaultLanguageCode": "ja",
"textSplitMode": "pages",
"maximumPageLength": 1000,
"pageOverlapLength": 100,
"unit": "characters"
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill", // チャンクをベクトル変換
"name": "#2",
"description": "Skillset for AI Search",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*", // #1でチャンク分割したデータを指定*/
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "embedding" // ベクトル変換後のデータパス
}
],
"resourceUri": "https://.openai.azure.com",
"deploymentId": "",
"apiKey": "",
"modelName": ""
}
],
"cognitiveServices": {
"@odata.type": "#Microsoft.Azure.Search.DefaultCognitiveServices"
},
"@odata.etag": "\"0x8DCF55D565FA71D\"",
"indexProjections": {
"selectors": [
{
"targetIndexName": "",
"parentKeyFieldName": "parent_id",
"sourceContext": "/document/pages/*",
"mappings": [ // インデックスに格納したいデータとその取得元(メタデータなど)をマッピングする
{
"name": "chunk",
"source": "/document/pages/*"
},
{
"name": "vector",
"source": "/document/pages/*/embedding" // #2のoutputsと連動
},
{
"name": "metadata_spo_item_name",
"source": "/document/metadata_spo_item_name"
},
{
"name": "metadata_spo_item_path",
"source": "/document/metadata_spo_item_path"
},
{
"name": "metadata_spo_item_content_type",
"source": "/document/metadata_spo_item_content_type"
},
{
"name": "metadata_spo_item_last_modified",
"source": "/document/metadata_spo_item_last_modified"
},
{
"name": "metadata_spo_item_size",
"source": "/document/metadata_spo_item_size"
},
{
"name": "content",
"source": "/document/content"
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
}
}これでベクトル検索を行うためのベクトルデータの準備は完了しました。
最後に、セマンティック検索の設定を行います。
セマンティック構成
実は、セマンティック構成はインデックス作成時に完了しています。
インデックス設定の以下のパートがセマンティック構成の設定になっており、これだけでドキュメント検索時にセマンティック検索を利用することができるようになっています。
{
"semantic": { // セマンティック検索の設定
"defaultConfiguration": null,
"configurations": [
{
"name": "sharepoint-semantic-config",
"prioritizedFields": {
"titleField": {
"fieldName": "metadata_spo_item_name"
},
"prioritizedContentFields": [
{
"fieldName": "content"
}
],
"prioritizedKeywordsFields": []
}
}
]
},
}ここまででベクトル検索&セマンティック検索を行うための準備は完了しました。
後はAPI実行時にこれらの設定をパラメータに指定するだけですので、この記事では割愛したいと思います。
(チャットプレイグラウンドからも非常に簡単に利用できるようになっていますので、ぜひ試してみてください!)
おわりに
ベクトル検索はデータの意味を数値的に捉え、セマンティック検索はクエリの意図を理解して結果を得ることができます。
両技術を組み合わせることで、より精度の高い検索結果が得られ、従来の検索では取りこぼしたり意図を取り違えていたデータにもアクセスできるようになります。
これにより、生成AIにRAGを利用する際、より精度の高い回答を得やすくなり、ユーザー体験の向上につながっていくでしょう。
今後も生成AIのモデルの進化だけでなく、周囲の情報を如何に活用するかといった点でも研究は進んでいくでしょう。
生成AIの特性を正しく理解し、どうすれば活用できるかを常に考え続けることが肝要ですね。
