







【dynamoose】DynamoDBから1MB以上のデータを取得する方法

Webアプリ開発の案件で、あるとき画面表示されるべきデータの欠損が発覚しました。表示に利用するデータはAPI経由でDynamoDBから取得していましたが、これまでそのようなことは起きていなかったので焦って原因調査したところ、あるDynamoDBの制約によってデータが十分に取得できていないことが判明しました。
今回は、その制約を回避するべくdynamoose(TypeScript)での実装方法をご紹介します。
もくじ
はじめに
DynamoDBの制約
ページング処理とは
前提条件
実装
おわりに
はじめに
こんにちは。
クラウドソリューショングループの kikuchi.s です。
この記事は アイソルート Advent Calendar 2022 の11日目の記事です。
昨日は takinami.s さんの 「業務外の活動を促進するべく、取り組んでいる内容を語りたい」 でした。エンジニアとしての成長に繋がる重要なファクターが語られています。こちらもぜひご覧ください。
DynamoDBの制約
テーブル操作には大きく分けて、Read(読み込み)とWrite(書き込み)があります。
ReadにはScanとQueryの2通りの方法がありますが、どちらもDynamoDBから一度に取得できるデータサイズが1MBまでという制約があります。1MB以上のデータを取得するにはページング処理が必要です。
ページング処理とは
例えば、合計10MBのデータを取得するとします。
Read処理を実行すると、以下のように1MBまではデータ取得できますが、9MBのデータは渡されません。その代わり、「末尾レコード情報はコレだよ」という情報がLastEvaluatedKeyとして渡されます。
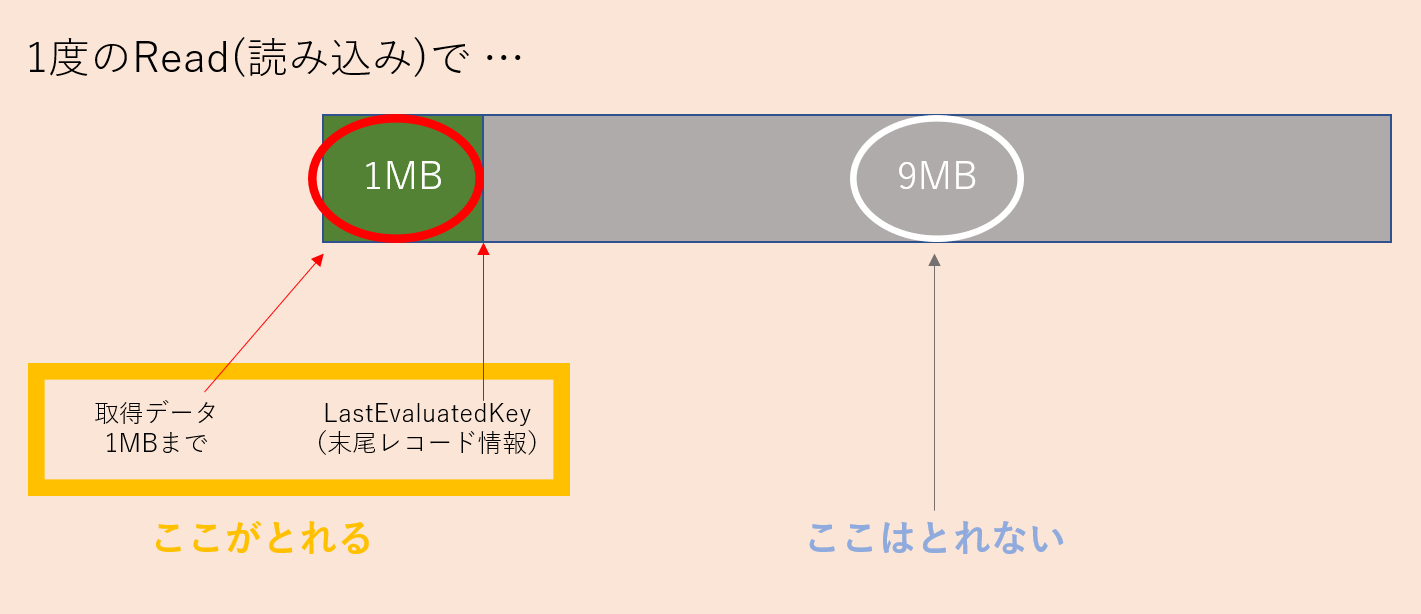
このLastEvaluatedKeyを使って再度Read処理を実行すると、末尾レコードの続きから次の1MB分のデータが取得できます。これがページング処理です。
つまり、今回の例で10MBのデータを全て取得するにはRead処理を計10回実行する必要があります。
前提条件
以下の環境で実装します。
| パッケージ名 | バージョン |
| node.js | 14.15.0 |
| TypeScript | 4.1.3 |
| dynamoose | 2.8.8 |
実装
今回は取得対象データが全体で何MBなのかに関わらず全量取り切るように再帰関数を組みます。際限なくデータが取れるのを嫌う場合はリクエスト回数の上限を設ける等のアレンジしていただければと思います。
実装は以下の通りになります。
■DBリポジトリの定義
import dynamoose from "dynamoose";
import { Schema } from "dynamoose/dist/Schema";
import { ModelOptions } from "dynamoose/dist/Model";
import { Document } from "dynamoose/dist/Document";
import { ModelType, ObjectType } from "dynamoose/dist/General";
import { Query } from "dynamoose/dist/DocumentRetriever";
const userSchema = new dynamoose.Schema({
PK: {
type: String,
hashKey: true,
},
SK: {
type: String,
hashKey: true,
},
id: String,
name: String,
age: Number,
gender: {
type: Number,
enum: [1, 2], // 1:男、2:女
}
});
interface User {
PK: string;
SK: string;
id: string;
name: string;
age: number;
gender: number;
}
interface UserDocument extends Document, User {}
const createRepository = <S extends Document, T extends { [name: string]: (...args: any[]) => Promise<any> }>(
tableName: string,
schema: Schema,
options: Partial<ModelOptions>,
methods: T
) => {
const repository = dynamoose.model<S>(tableName, schema, options);
Object.entries(methods).forEach(([name, fn]) => {
repository.methods.set(name, fn);
});
return repository as ModelType<S> & T;
};
const userRepository = createRepository<
UserDocument,
{
calcPK: (obj: { gender: number }) => Promise<number>;
calcSK: (obj: { age: number}) => Promise<number>;
}
>(
"t_user",
voteResultSchema,
{
create: false,
update: false,
waitForActive: false,
},
{
calcPK: async (obj) => obj.gender,
calcSK: async (obj) => obj.age,
}
);
■ページング処理
async exec(query: Query<UserDocument>, startAtLastKey?: ObjectType): Promise<UserDocument[]> {
let req = query;
if (startAtLastKey) {
req = query.startAt(startAtLastKey);
}
const res = await req.exec();
let results: UserDocument[] = [];
results = results.concat(res);
const { lastKey } = res;
if (lastKey) {
console.log("lastKeyが取得されたため、続けてDBクエリを投げます");
results = results.concat(await this.exec(query, lastKey));
}
return results;
};
■クエリ実行例(男 かつ 20歳以上 のユーザー一覧を取得)
const queryUser = userRepository
.query("PK")
.eq(await userRepository.calcPK({ gender: 1}))
.where("SK")
.ge(await userRepository.calcSK({ age: 20}));
const users = await this.exec(queryUser);
おわりに
dynamooseを知ろうと色々調べるとまだまだ日本語の記事が少ないなぁと感じる今日この頃です。少しでもこの記事が読んでいただいた方の課題解決に役立てば、と思い書きました。
明日は arai.y さんの 記事 です。ぜひこちらもご覧ください。
