







LangGraphを使ったLangChain Agentの思考フローの可視化

こんにちは、shibamです。
LangChainを使ったAIアプリケーション開発を行っていると、複雑なAgentの動作をデバッグしたいと思うことはありませんか?特に大規模な会話フローやツールを組み合わせた場合、「なぜこの応答になったのか」「どこでエラーが発生したのか」を追跡するのは非常に難しいものです。
前回の「LangchainのAgent機能を試してみる②:自然言語でSQLクエリを自動生成」の記事で少し触れましたが、LangGraphを使うとエージェントの思考プロセスを明示的に設計できます。今回は、LangChainのグラフベースフレームワークである「LangGraph」と、そのビジュアルデバッグツール「LangGraph Studio」を使って、AIエージェントの思考プロセスを可視化し、より効率よくLangGraphを構築する手順を紹介します。
目次
1. はじめに
LangChainを使ったAIアプリケーション開発において、複雑なワークフローのデバッグは大きな課題です。特に以下のような問題に直面することがあります。
- エージェントがなぜその判断をしたのか理解できない
- 複数の処理ステップのどこでエラーが発生したのか特定できない
- 状態の変化を追跡するのが難しい
こうした課題を解決するために開発されたのが「LangGraph」です。LangGraphを使うと、AIエージェントの複雑な思考フローをグラフ構造として設計・可視化でき、各ノードの実行状態やデータの流れを詳細に追跡できるようになります。
2. TL;DR
- LangGraphはLangChainのグラフベースフレームワークで、複雑なAIワークフローを構築・デバッグするためのツール
- LangGraph Studioを使うと、ワークフローをビジュアルに確認・デバッグできるが、LangSmithのアカウント登録が必要
- LLMを活用して各ステップでの判断を行う高度なノードを構築することで、より柔軟なワークフローが実現可能
- 条件付きエラー誘発を実装することで、エラーハンドリングのテストやデバッグが容易に
- 適切なグラフ構造設計により、LangGraph Studioでの可視化が明瞭になり、思考フローの追跡が容易になる
3. LangGraphとは
基本概念
LangGraphは、LangChainの拡張フレームワークで、グラフ構造を使って複雑なAIワークフローを設計・実行するためのツールです。以下の主要な概念で構成されています。
- ノード(Node): 特定の処理を行う関数。例えば「ユーザー入力の理解」「検索実行」「計算処理」など
- エッジ(Edge): ノード間の接続。データの流れや条件分岐を表現
- 状態(State): ワークフロー内で共有されるデータ
- ルーター(Router): 条件に基づいて次に実行するノードを決定する関数
LangChainの通常のChainsと比較して、LangGraphは以下のような利点があります。
- 明示的な制御フロー: 処理の流れを明確に設計できる
- 状態の追跡: 各ステップでの状態変化を追跡できる
- 条件分岐: 複雑な条件に基づく分岐を実装できる
- 可視化: グラフ構造を視覚的に表現できる
どのような場面で使うべきか
LangGraphは特に以下のような場面で威力を発揮します。
- 対話型エージェントの複雑な判断ロジックを実装する場合
- 複数のツールを組み合わせたマルチステップの処理が必要な場合
- 条件に応じて異なる処理パスを取る必要がある場合
- エージェントの判断プロセスを透明化したい場合
- 複雑なワークフローのエラー発生箇所を特定したい場合
基本的な構造
本リポジトリをクローンすると、my_agentディレクトリが含まれており、その中に基本的なLangGraphの実装例としてagent.pyがあります。この既存のファイルを見てみましょう。
from typing import TypedDict, Literal
from langgraph.graph import StateGraph, END
from my_agent.utils.nodes import call_model, should_continue, tool_node
from my_agent.utils.state import AgentState
# Define the config
class GraphConfig(TypedDict):
model_name: Literal["anthropic", "openai"]
# Define a new graph
workflow = StateGraph(AgentState, config_schema=GraphConfig)
# Define the two nodes we will cycle between
workflow.add_node("agent", call_model)
workflow.add_node("action", tool_node)
# Set the entrypoint as `agent`
# This means that this node is the first one called
workflow.set_entry_point("agent")
# We now add a conditional edge
workflow.add_conditional_edges(
# First, we define the start node. We use `agent`.
# This means these are the edges taken after the `agent` node is called.
"agent",
# Next, we pass in the function that will determine which node is called next.
should_continue,
# Finally we pass in a mapping.
# The keys are strings, and the values are other nodes.
# END is a special node marking that the graph should finish.
# What will happen is we will call `should_continue`, and then the output of that
# will be matched against the keys in this mapping.
# Based on which one it matches, that node will then be called.
{
# If `tools`, then we call the tool node.
"continue": "action",
# Otherwise we finish.
"end": END,
},
)
# We now add a normal edge from `tools` to `agent`.
# This means that after `tools` is called, `agent` node is called next.
workflow.add_edge("action", "agent")
# Finally, we compile it!
# This compiles it into a LangChain Runnable,
# meaning you can use it as you would any other runnable
graph = workflow.compile()
上記のコードで実装されている主要な概念を改めて確認してみましょう。
- ノード(Node): 特定の処理を行う関数。例えば
call_modelとtool_nodeの2つのノードがあります。 - エッジ(Edge): ノード間の接続。データの流れや条件分岐を表現します。
workflow.add_edge("action", "agent")のように定義します。 - 状態(State): ワークフロー内で共有されるデータ。上記の例では
AgentStateクラスで定義しています。 - 条件付きエッジ: 条件に基づいて次に実行するノードを決定します。
should_continue関数の結果によって、次のノードが選択されます。
実行設定ファイルの準備
クローンしたリポジトリに含まれているlanggraph.jsonファイルを、今回のデモ用に編集しましょう。
{
"dependencies": ["."],
"graphs": {
"agent": "./my_agent/agent.py:graph",
"debug_agent": "./my_agent/debug_agent.py:debug_agent_graph"
},
"env": ".env"
}
このファイルでは、LangGraph Studioで表示・実行するグラフを定義しています。graphsセクションでは、各グラフの名前と、それに対応するファイルパスとエントリーポイントを指定しています。今回のデモでは、リポジトリに含まれているagent.pyと、これから作成するdebug_agent.pyの両方を利用します。
4. LangGraph Studioを使ってみる
環境設定
まずは必要なライブラリをインストールします。
pip install langchain langgraph langchain-openai langchain-anthropic python-dotenv
本記事執筆時点のライブラリのバージョン情報は以下になります。
langchain: 0.2.17
langgraph: 0.2.76
langchain-openai: 0.1.25
langchain-anthropic: 0.1.23
python-dotenv: 1.0.1次に、必要なAPIキーを設定します。 .env ファイルを作成し、以下の内容を記述してください。
APIキーの取得について
langGraph studioを使用するには、OpenAIのAPIキーとTavilyのAPIキーが必要です。
OpenAIのAPIキーはOpenAI公式サイトから取得できます。
今回の記事執筆にあたり、いくつかのデバッグを重ねた上で発生した費用は約$0.17(25.5円)です。
TavilyのAPIキーはTavily公式サイトから取得できます。
Tavilyについては、無料プランでもAPIキーを取得できます。また、今回のサンプルでは無料プランを使用しており、Tavily側での料金は発生しません。
OPENAI_API_KEY=your_openai_api_key
TAVILY_API_KEY=your_tavily_api_key
LangGraph CLIのインストールと起動
LangGraph CLIをインストールします。
pip install langgraph[cli]
次にLangGraph Studioを起動します。
langgraph dev
このコマンドを実行すると、ローカルでトレーシングサーバーが起動します。
次に、LangSmithのダッシュボードにアクセスしてログインし、メニューから「Studio」を選択することでLangGraph Studioのインターフェースを使用できます。
LangSmithのダッシュボードでは、トレーシングデータとLangGraphの可視化が連携して表示されます。
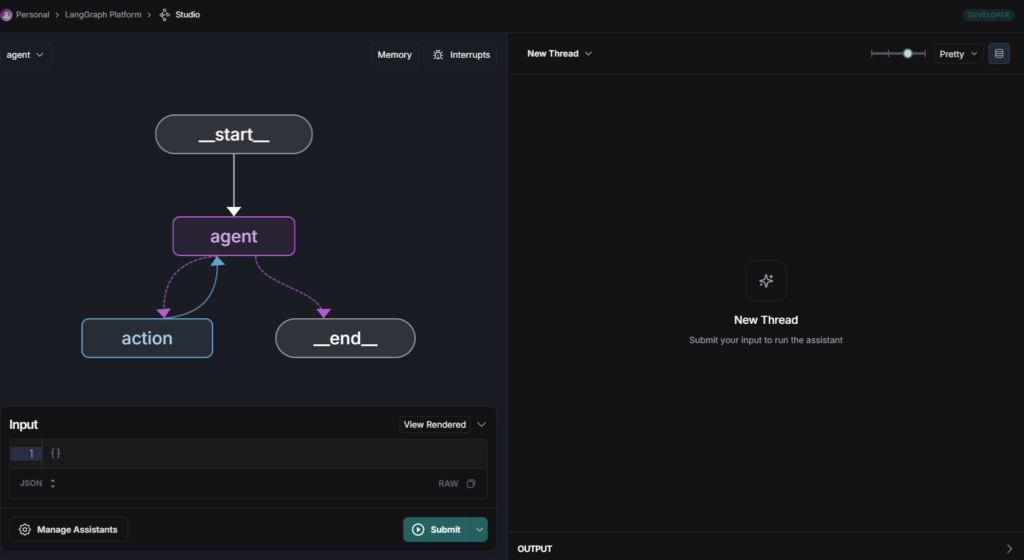
図1: LangGraph Studioの初期画面
5. 高度な判断機能を持つノードの作成
次に、より高度な判断機能を持つノードを作成していきましょう。LangGraphでは、各ノードがAIエージェントの思考プロセスの一部を担当します。
基本構造の設計
検索機能と計算機能を持つエージェントを作成するために、以下のようなノード構造を設計します。
- 初期ノード: ユーザー入力を解析し、検索か計算かを判断
- 検索ノード: 情報検索を実行
- 計算ノード: 数値計算を実行
- エラーハンドリングノード: エラー発生時の処理
- 最終ノード: 最終結果の生成
上記の設計に基づいて、デバッグ機能を持つエージェントを実装しましょう。以下のコードをmy_agentディレクトリ内にdebug_agent.pyという名前で保存します。
import os
import random
import time
from typing import Dict, List, Any, Optional, TypedDict
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from langgraph.graph import StateGraph, END, START
# 環境変数の読み込み
load_dotenv()
print("LangGraph デバッグサンプルを開始します...")
# デバッグ設定
DEBUG = True
# 状態の型定義
class DebugState(TypedDict):
"""デバッググラフの状態を表現するクラス"""
messages: List[Any] # メッセージ履歴
current_step: str # 現在のステップ
attempts: int # 試行回数
has_error: bool # エラーが発生したかどうか
error_message: Optional[str] # エラーメッセージ
result: Dict[str, Any] # 結果
force_error_search: bool # 検索エラーを強制するフラグ
force_error_calculate: bool # 計算エラーを強制するフラグ
# ノード関数の定義
def initial_node(state: DebugState) -> DebugState:
"""初期ノード: ユーザーの入力を処理する"""
print("初期ノードを実行中...")
messages = state["messages"]
if not messages:
# メッセージがない場合はデフォルトメッセージを追加
messages = [HumanMessage(content="AIについて調べてください")]
# JSON形式のメッセージを適切なメッセージオブジェクトに変換
processed_messages = []
for msg in messages:
if isinstance(msg, dict):
# 辞書形式のメッセージをオブジェクトに変換
if msg.get("type") == "human":
processed_messages.append(HumanMessage(content=msg.get("content", "")))
elif msg.get("type") == "ai":
processed_messages.append(AIMessage(content=msg.get("content", "")))
elif msg.get("type") == "system":
processed_messages.append(SystemMessage(content=msg.get("content", "")))
else:
# 不明なタイプの場合はヒューマンメッセージとして扱う
processed_messages.append(HumanMessage(content=str(msg.get("content", ""))))
else:
# すでにメッセージオブジェクトの場合はそのまま追加
processed_messages.append(msg)
# 処理済みメッセージに置き換え
messages = processed_messages
# LLMを使ってプロンプト内容を分析
llm = ChatOpenAI(model="gpt-4o", temperature=0)
system_message = SystemMessage(content="""
あなたはプロンプト分析アシスタントです。ユーザーの質問を分析し、必要な処理ステップを特定してください。
選択肢:
- search: 情報検索が必要な場合
- calculate: 数値計算や予測が必要な場合
回答は「search」「calculate」のいずれかのみを返してください。
""")
# プロンプト内容を分析して次のステップを決定
action_input = messages[-1].content if messages else "AIについて調べてください"
action_prompt = f"次のユーザープロンプトを分析し、最適な処理ステップを選択してください: {action_input}"
response = llm.invoke([system_message, HumanMessage(content=action_prompt)])
next_step = response.content.strip().lower()
# 有効なステップに正規化
valid_steps = ["search", "calculate"]
if next_step not in valid_steps:
next_step = "search" # デフォルト
# 解析結果をメッセージに追加
messages.append(AIMessage(content=f"プロンプト分析: '{next_step}' 処理が必要と判断しました。"))
# エラーフラグをチェック(メッセージに特定のキーワードがあるか)
force_error_search = "エラー" in action_input or "失敗" in action_input or "error" in action_input.lower()
force_error_calculate = "計算エラー" in action_input or "計算失敗" in action_input or "calculation error" in action_input.lower()
return {
**state,
"messages": messages,
"current_step": next_step,
"attempts": 0,
"has_error": False,
"error_message": None,
"force_error_search": force_error_search,
"force_error_calculate": force_error_calculate
}
def search_node(state: DebugState) -> DebugState:
"""検索ノード: 情報検索を行う"""
print("検索ノードを実行中...")
# 検索処理のシミュレーション
time.sleep(1)
# 検索結果をメッセージに追加
messages = state["messages"]
messages.append(AIMessage(content="検索結果: AIに関する最新情報を見つけました。"))
# エラーを強制するパラメータをチェック
force_error = state.get("force_error_search", False)
# エラーが強制されるか、デバッグモードでランダムにエラーが発生する場合
if force_error or (random.random() DebugState:
"""計算ノード: 数値計算を行う"""
print("計算ノードを実行中...")
# 計算処理のシミュレーション
time.sleep(1)
# 計算結果をメッセージに追加
messages = state["messages"]
messages.append(AIMessage(content="計算結果: AIの成長率は年間約70%と推定されます。"))
# エラーを強制するパラメータをチェック
force_error = state.get("force_error_calculate", False)
# エラーが強制されるか、デバッグモードでランダムにエラーが発生する場合
if force_error or (random.random() DebugState:
"""エラーハンドリングノード: エラーを処理する"""
print("エラーハンドリングノードを実行中...")
messages = state["messages"]
error_message = state.get("error_message", "不明なエラーが発生しました")
attempts = state.get("attempts", 0) + 1
# エラーメッセージをログに記録
print(f"エラー処理 (試行 {attempts}): {error_message}")
# エラーメッセージをメッセージに追加
messages.append(AIMessage(content=f"エラーが発生しました: {error_message}"))
# 再試行するかどうかの判断
if attempts DebugState:
"""最終ノード: 最終結果を生成する"""
print("最終ノードを実行中...")
messages = state["messages"]
has_error = state.get("has_error", False)
if has_error:
messages.append(AIMessage(content="エラーが発生したため、完全な結果を提供できませんでした。利用可能な情報に基づいて回答します。"))
# LLMを使って最終回答を生成
llm = ChatOpenAI(model="gpt-4o", temperature=0)
system_message = SystemMessage(content="あなたはデバッグテスト用のアシスタントです。収集した情報に基づいて、最終的な回答を提供してください。")
# これまでのメッセージ履歴に基づいて回答を生成
final_response = llm.invoke([system_message] + messages)
# 最終回答をメッセージに追加
messages.append(final_response)
# 結果をまとめる
result = {
"final_answer": final_response.content,
"error_occurred": has_error,
"attempt_count": state.get("attempts", 0)
}
return {
**state,
"messages": messages,
"current_step": "end",
"result": result
}
# ルーター関数
def router_node(state: DebugState) -> str:
"""次に実行するノードを決定する"""
current_step = state.get("current_step", "")
has_error = state.get("has_error", False)
print(f"ルーター: 現在のステップ = {current_step}, エラー = {has_error}")
if current_step == "end":
return "end"
return current_step
# グラフ作成関数
def create_debug_graph():
"""デバッググラフを作成"""
# ワークフローの定義
workflow = StateGraph(DebugState)
# ノードの追加
workflow.add_node("initial", initial_node)
workflow.add_node("search", search_node)
workflow.add_node("calculate", calculate_node)
workflow.add_node("error", error_node)
workflow.add_node("final", final_node)
# エントリーポイントの設定
workflow.add_edge(START, "initial")
# 初期ノードからの条件付きエッジ
workflow.add_conditional_edges(
"initial",
router_node,
{
"search": "search",
"calculate": "calculate",
"error": "error",
"final": "final"
}
)
# 各処理ノードからの条件付きエッジ
for node in ["search", "calculate", "error"]:
workflow.add_conditional_edges(
node,
router_node,
{
"search": "search",
"calculate": "calculate",
"error": "error",
"final": "final"
}
)
# 最終ノードからENDへのエッジのみを残す
workflow.add_conditional_edges(
"final",
router_node,
{
"end": END
}
)
# グラフのコンパイル
return workflow.compile()
# グラフのインスタンス化
debug_agent_graph = create_debug_graph()
上記のコードでは、5つの主要なノードを実装しています。
- initial_node: ユーザー入力を分析して次のステップを決定します
- search_node: 検索を実行し、結果を返します
- calculate_node: 計算を実行し、結果を返します
- error_node: エラーが発生した場合に処理します
- final_node: 最終的な回答を生成します
各ノードは、入力された状態を処理して次のステップを決定します。エッジはrouter_node関数によって制御され、現在のステップに基づいて次のノードを選択します。
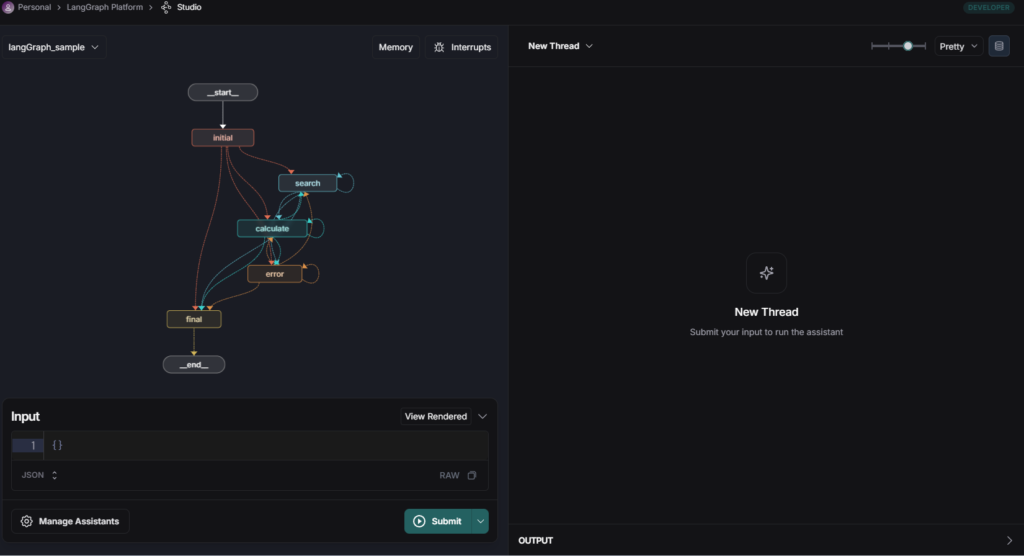
図2: 作成したlangGraphの構造可視化
6. エラーハンドリングを追加する
エラー検出と処理
実際のアプリケーションでは、さまざまなエラーが発生する可能性があります。例えば、
- 外部APIの呼び出し失敗
- レート制限による一時的なエラー
- 不正な入力データ
- 計算エラー(0除算など)
これらのエラーを適切に処理するために、先ほど実装したコードにはエラーハンドリングノードを組み込んでいます。
エラーハンドリングノードでは、エラーの種類に応じて以下のような処理を行います。
- エラーの記録(ログ記録)
- 再試行の判断
- 代替処理の実行
- ユーザーへのエラーフィードバック生成
条件付きエラー誘発
デバッグのため、特定の条件下でエラーを意図的に発生させる機能も実装しています。この機能を使うと、エラーハンドリングが適切に動作するかをテストできます。
実装したコードでは、以下のようなキーワードを入力に含めることでエラーを意図的に発生させることができます。
- 「エラー」「失敗」「error」:検索ノードでエラーを発生
- 「計算エラー」「計算失敗」「calculation error」:計算ノードでエラーを発生
エラーハンドリングを試す
それでは、先ほど作成したdebug_agent.pyを使ってLangGraph Studioでデバッグを試してみましょう。LangSmithのダッシュボードにアクセスし、Studioタブを開きます。
LangGraph Studioで実行するためには、以下のようなJSONをInputsフィールドに貼り付けて「Run」ボタンをクリックします。
{
"messages": [
{
"type": "human",
"content": "AIの成長率を計算して将来の予測をしてください"
}
]
}
エラーが発生するようなリクエストをテストする場合は、以下のようなJSONを使用します。
{
"messages": [
{
"type": "human",
"content": "AIについて調べてエラーを発生させてください"
}
]
}
LangGraph Studioでは、リクエストを実行すると以下のような可視化画面が表示されます。
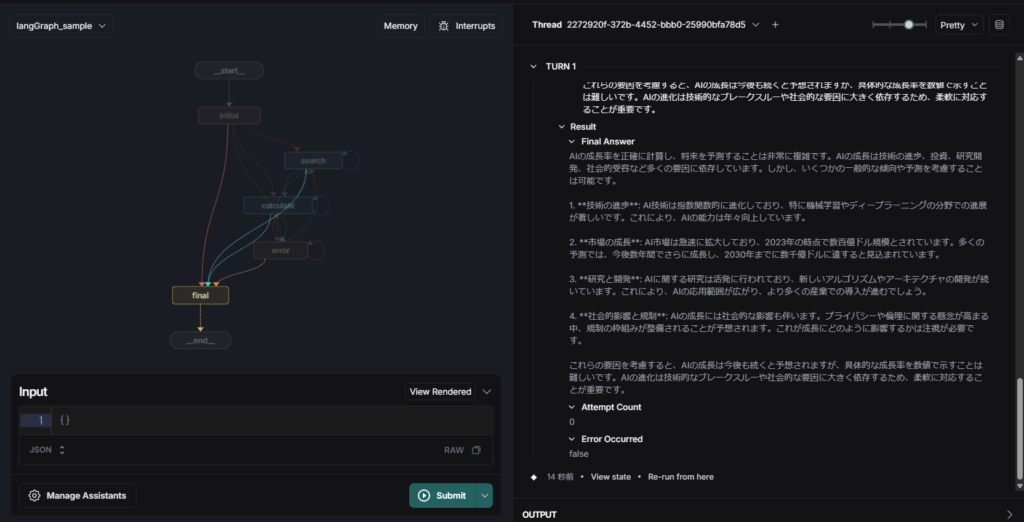
図3: 「AIの成長率を予測してください」実行時の処理フロー
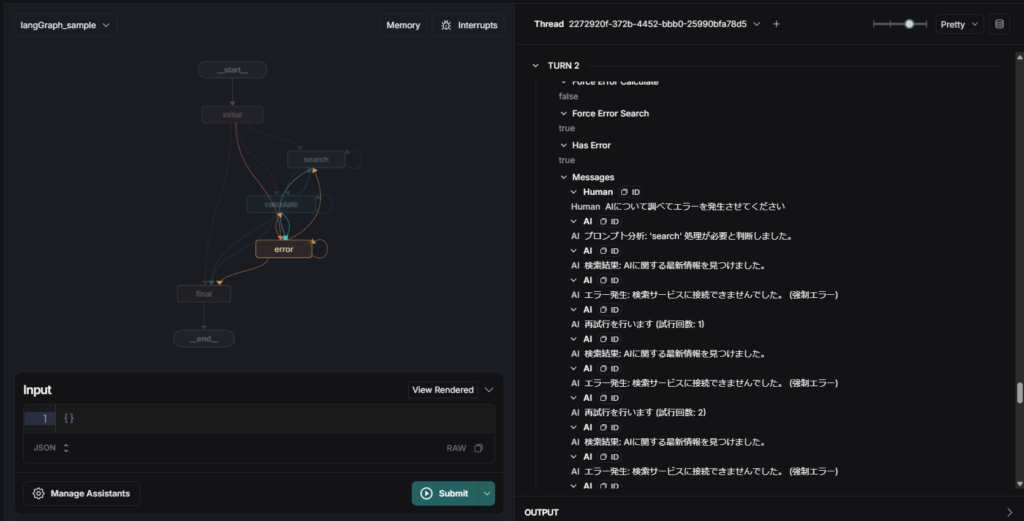
図4: エラー発生時のLangGraph Studioの可視化画面
このように、LangGraph Studioを使用することで、エージェントの思考フローを視覚的に確認できます。これにより、複雑なAIエージェントの動作を理解しやすくなり、デバッグも容易になります。
7. 最後に
この記事では、LangGraphを使ってAIエージェントの思考プロセスを可視化し、デバッグする方法を紹介しました。
LangGraphを使うことで、複雑なエージェントの振る舞いを理解しやすくなり、開発効率が向上します。
LangGraphとLangGraph Studioを組み合わせることで、エージェントの各ステップでの判断プロセスを透明化できるため、
より信頼性の高いAIアプリケーションを構築できるようになります。
今回紹介したテクニックを応用して、皆さんもぜひ自分のプロジェクトでLangGraphを活用してみてください。
