







Azure OpenAI に日本語ドキュメントの内容を回答させてみた

現在、 Azure OpenAI Service の On your data 機能を利用すると、簡単に独自データに基づいた回答をする GPT を実現することができます。
しかし、 Web UI から On your data を利用した場合、言語アナライザーがデフォルト(英語)固定となってしまい、日本語の検索・回答精度があまり良くありません。
そこで、今回は日本語ドキュメントを日本語の言語アナライザーでインデックス化し、 Azure OpenAI が日本語ドキュメントの内容に基づいて回答するようにしてみたいと思います。
目次
- はじめに
- 概要説明
- Azure AI Document Intelligence の準備
- Azure AI Search の準備
- データ準備ツールの準備と実行
- Azure OpenAI Service との連携
- おわりに
はじめに
こんにちは。
クラウドソリューション第二グループのwatanabe.tです。
この記事は アイソルート Advent Calendar 2023 の 2日目の記事です。
昨日は onodera.t さんの 業務向けモバイルアプリ開発会社の選び方 でした。
前述の通り、 Azure OpenAI Service には独自データに基づいて回答する機能があります。
この機能を利用することで、製品マニュアルやFAQなどから製品についての回答をするチャットボットなどを容易に作成することが可能です。
そして、それを日本語対応させるため、今回は Azure AI Search (旧Azure Cognitive Search)と Azure AI Document intelligence (旧Azure Form Recognizer)を利用して、日本語のPDFからインデックスを作成していきます。
Azure AI Search | Microsoft Azure
Azure AI Document Intelligence | Microsoft Azure
ちなみに、AI Search と AI Document Intelligence は元々それぞれ別の名前でしたが、 Azure としても AI 系サービスをより明確にするため、リブランディングする方向に舵を切ったようです。
Microsoft Ignite 2023: AI トランスフォーメーションと変革を推進するテクノロジー | Microsoft News Center Japan
概要説明
Azure AI Document Intelligence とは
Azure AI Document Intelligence は、 Azure が提供する OCR (光学的文字認識)サービスです。
ただ文字を認識するだけでなく、表形式のデータを構造を保ったまま読み取るなど、かなりハイレベルなサービスになっています。
Azure AI Search とは
Azure AI Search は、 Azure が提供する 高度な検索エンジンのサービスです。
特に検索クエリの意味を理解し、関連性の高い結果を提供するために、 NLP (自然言語処理)を利用しています。
今回の活用
今回は公式が用意している データ準備ツール を利用します。
このツールを利用することで、以下の手順を自動で行ってくれます。
- Document Intelligence を利用して、ドキュメントをテキスト化
- 適切にテキストをチャンク化
- 分割されたテキストを AI Search に登録
Azure AI Document Intelligence の準備
それでは早速それぞれのサービスを準備していきましょう。
まずはドキュメント解析するための Document Intelligence からです。
と言っても特段難しい設定は不要です。
気を付けなければいけないのは、価格レベルが「F0 Free」の場合、ドキュメントは2ページ分しか読み取ってくれません。
それ以上のページを読み込ませ、インデックス化したい場合は「S0 Standard」を利用するようにしましょう。
Azure AI Search の準備
次にテキストのインデックスを登録し、 OpenAI Service から検索するための AI Search です。
こちらも特段難しい設定は不要です。
気を付けなければいけないのは、 OpenAI Service と連携するためには、価格レベルを「基本(Basic)」以上にする必要があることです。
また、ネットワークを「プライベート」にすることも可能ですが、その場合は OpenAI Service からアクセスできるように別途申請が必要になります。
API キーで最低限のセキュリティは保たれていますので、今回は「パブリック」で作成しておきましょう。
データ準備ツールの準備と実行
事前に必要な2つのリソースの準備ができたため、ここからは実際にデータ準備ツールを利用していきます。
なお、公式ツールの利用には Python 3.10 以上が必要なため、事前にインストールをしておいてください。
まず、公式ツールをローカルにクローンし、必要な Python ライブラリをインストールしていきます。
$ git clone https://github.com/microsoft/sample-app-aoai-chatGPT.git
$ pip install -r requirements-dev.txt次に script ディレクトリ内の config.json を編集し、前述の手順で作成した Document Intelligence, AI Search のリソースを紐づけます。
[
{
"data_path": "",
"location": "",
"subscription_id": "",
"resource_group": "",
"search_service_name": "",
"index_name": "",
"chunk_size": 1024,
"token_overlap": 128,
"semantic_config_name": "default",
"language": "<Language to support for example use 'en' for English."
}
]それぞれの項目の説明、設定例は以下の通りです。
| 項目名 | 説明 | 設定例 |
| data_path | 読み込むドキュメントの相対パス | ../data |
| location | AI Search, Document Intelligence のリージョン | japaneast |
| subscription_id | AI Search, Document Intelligence のサブスクリプションID | |
| resource_group | AI Search, Document Intelligence のリソースグループ名 | |
| search_service_name | 前の手順で作成した AI Search のリソース名 | srch-openai-dev-japaneast-001 |
| index_name | AI Search のインデックス名(自動で作成される) | srchidx-openai-dev-ja-001 |
| chunk_size | ドキュメントをインデックス化する際のチャンクサイズ | 1024 |
| token_overlap | チャンクにするときのオーバーラップ量 | 128 |
| semantic_config_name | セマンティック検索に関する設定名(2023年11月にGAされたばかり) | default |
| language | 言語アナライザーの言語設定。今回この方式でやっているのはここを変えるのが目的なので、忘れずに設定してください。 | ja |
では準備ができたら、 Azure CLI でログイン後、データ準備ツールを実行します。
$ az login
$ python3 data_preparation.py --config config.json --njobs=1 --form-rec-resource <Document Intelligence のリソース名> --form-rec-key <Document Intelligence の API キー>
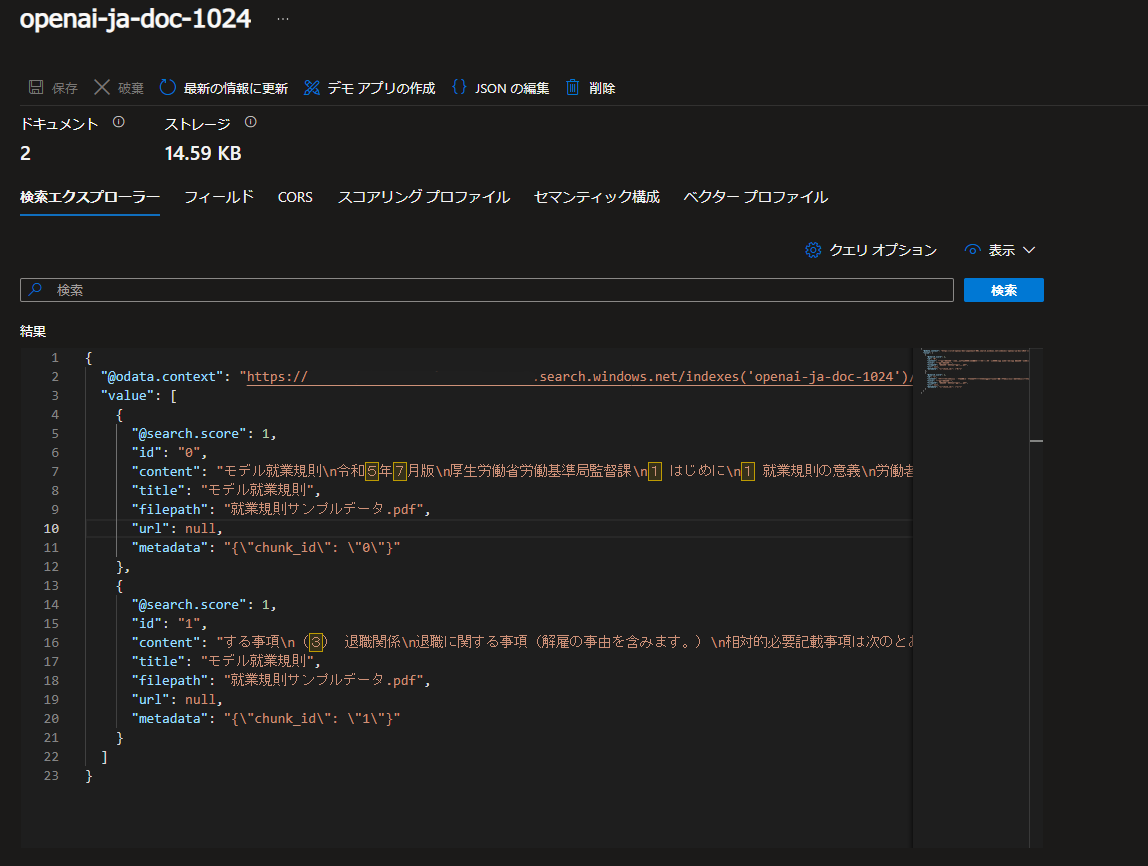
問題なくツールの実行が完了すると、 AI Search にインデックスが作成されていることが確認できます。
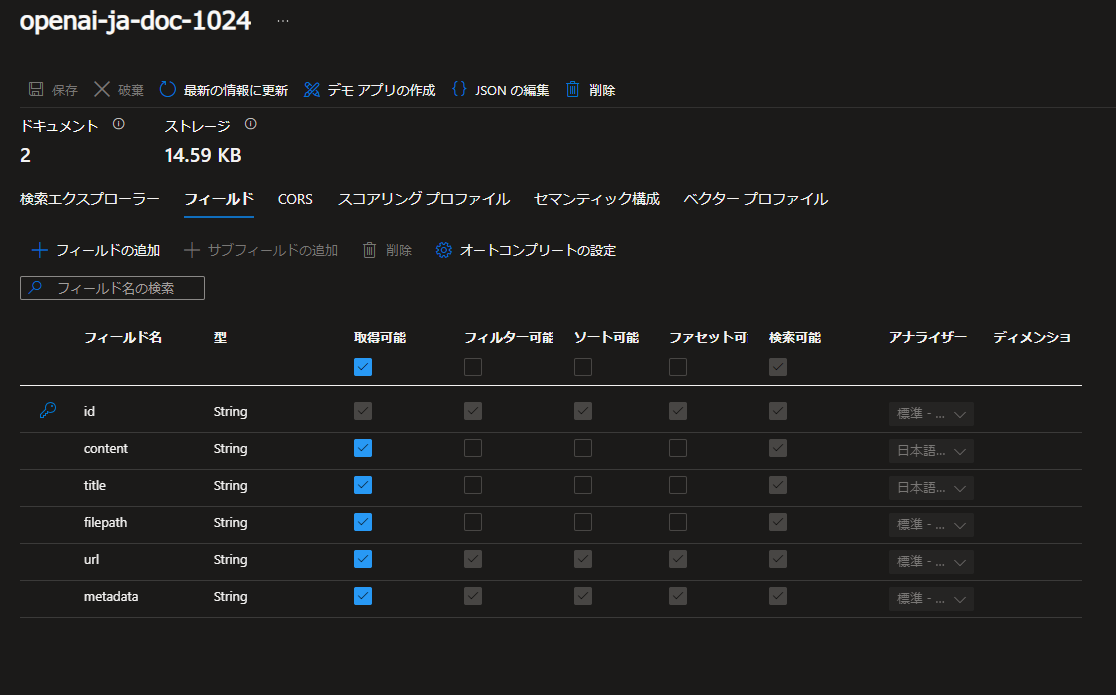
また、アナライザーの設定も日本語になっていることが確認できます。
Azure OpenAI Service との連携
それではいよいよ On your data で独自データに基づいて回答ができるかを確認していきましょう。
Azure OpenAI Studio へアクセスし、「データソースの追加」を選択します。設定値には先ほどまでに作成した AI Search のリソース名、インデックス名を選択してください。(フィールドのマッピングはツール側で考慮済みのため、デフォルトでOK!)
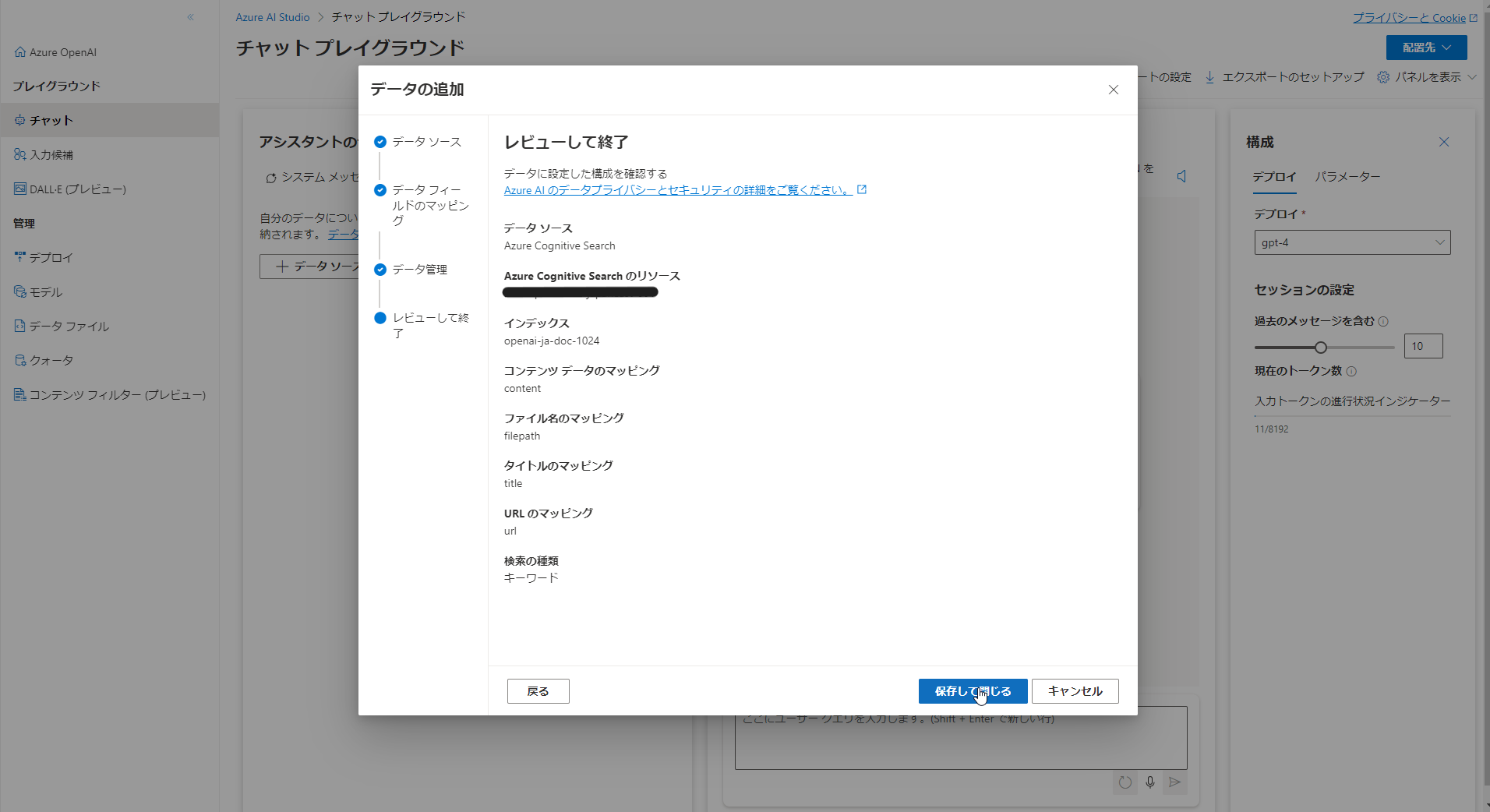
公式の推奨事項 を参考に、システムメッセージに以下のように設定しておいてください。
You are an AI assistant designed to help users extract information from retrieved Japanese documents.
Please scrutinize the Japanese documents carefully before formulating a response.
The user's query will be in Japanese, and you must response also in Japanese.試してみる
今回は以下の画像を読み込み、この内容について質問してみました。
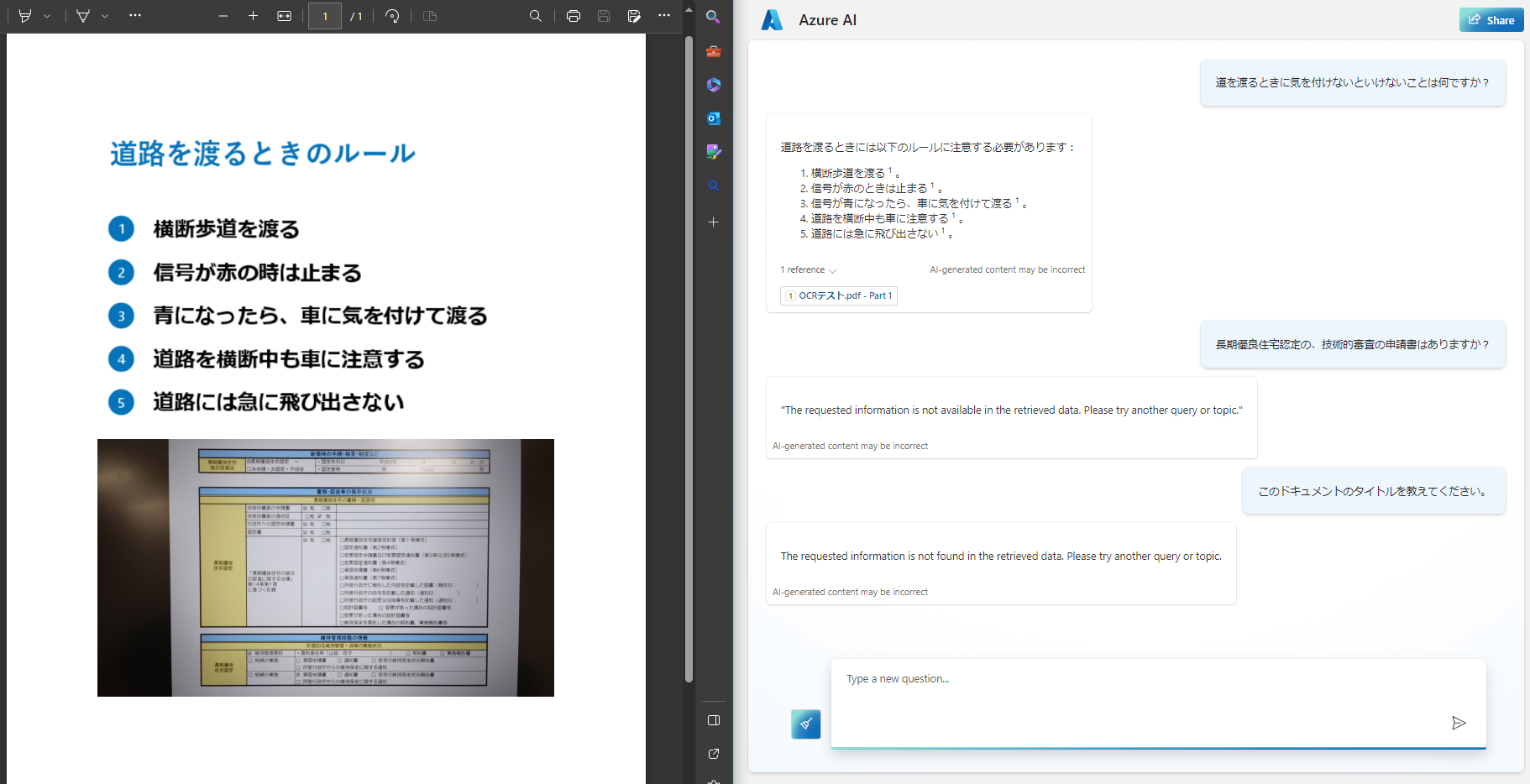
良い感じですね!ちゃんと独自データの内容に基づいて回答をしてくれています。
おわりに
今回は Azure OpenAI Service の On your data 機能を利用して、日本語ドキュメントの内容に基づいて回答させる方法について解説しました。
Azure AI Document Intelligence の精度も高く、活用の幅はかなり広いと感じたので、そちらの解説についても別で投稿しようと思います。
明日は fujinami.m さんの swiftのasync/awaitを使った非同期処理の実装 です。お楽しみに!
