







【AWS】東京リージョンでAmazon Kendra、S3を用いたセマンティック検索を実装してみた

こんにちは。システムサービス本部クラウドソリューショングループのshimizuyです。
社内業務で得た膨大なデータはあるんだけどイマイチ有効活用できていないのよね、、といった悩みを抱える企業が一昔前までは多かったと思いますが、昨今ではAIや機械学習の発達により社内データを活用したドキュメントサイトを作成しました!みたいなニュースが増えてきましたよね。
そこで重要になってくるのは高機能な「検索機能」です。
「RDS」「GitHub」「Gmail」などのデータソースや「PDF」や「Word」形式など様々なドキュメントタイプのデータを基に膨大な社内データに対して、利用者からの検索方法に柔軟に応え、必要な情報を素早く検索できる必要があります。
という訳で今回は、Kendraを用いた簡易的な非構造化データに対するセマンティック検索の実装方法をご紹介していこうと思います。
Amazon Kendraとは
Amazon Kendra(アマゾン ケンドラ)は、Amazon Web Services(AWS)が提供するクラウドベースの検索サービスで、機械学習(ML)を活用して、企業内のさまざまなデータやドキュメントから自然言語で情報を検索・取得することができます。
Amazon Kendra の主な特徴としては以下の4点が挙げられます。
- 自然言語で検索できる:話し言葉による質問を理解し、関連性の高い情報を探し出すことができる。
- FAQ照合が可能:よく出される質問(FAQ)に対してあらかじめ用意された回答を紐づけ、自動的に提供できる。
- さまざまなデータソース、ドキュメントタイプに対応している:
- データソース:Amazon S3、Amazon RDS、GitHub、Jira、Salesforce、OneDriveなど
- ドキュメントタイプ:html、pdf、csv、xlsx(Excel)、ppt(PowerPoint)など
- アプリケーションに組み込める:AWS CLIやAPIからAmazon Kendraを利用することで、アプリケーションやWebサイトに検索システムを組み込むことができる。
なお、サポートされているデータソース、ドキュメントタイプの詳細については下記リンク先の公式ドキュメントをご確認ください。
セマンティック検索とは
「セマンティック検索」と聞くとなじみがない方もいらっしゃるかもしれませんが、「あいまい検索」といえば皆さん一度は目にしたことがあるのではないでしょうか。
AWSによると以下のような状態を指して「セマンティック検索」と定義づけているみたいですね。
> 入力された自然言語の意味を理解して、その意味に沿った回答をする技術です。言い換えると、検索をする際にキーワードではなく会話文のような文章を入力しても適切な回答が返ってくる
参考①:Amazon Kendra で簡単に検索システムを作ってみよう !
参考②:Azure OpenAIの力を引き出す!ベクトル&セマンティック検索で回答精度を劇的改善
それではさっそくAmazon Kendraを用いたセマンティック検索の実装に移っていきましょう。
Amazon Kendraを用いたセマンティック検索検証環境の実装
0. 事前準備
AWS Consoleに入ったらまずは東京リージョンで操作していることを確認してください。
また、今回はS3バケットに配置したファイル内の情報をリソース元としたAmazon Kendraのセマンティック検索機能を実装していきますので、事前にお好みでKendraが対応しているデータソースやドキュメントを配置してください。
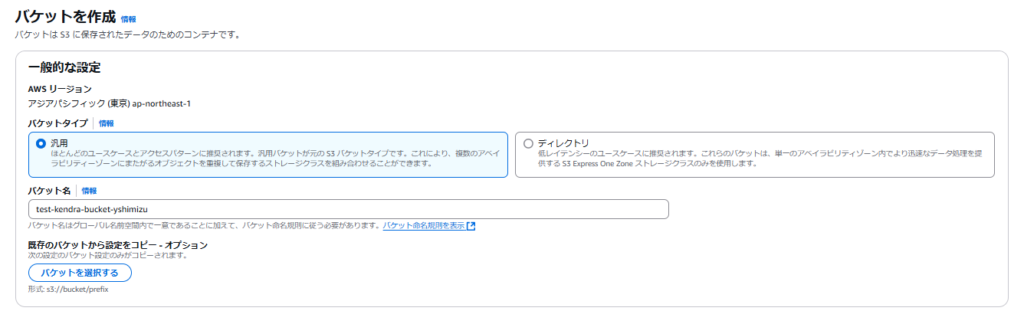
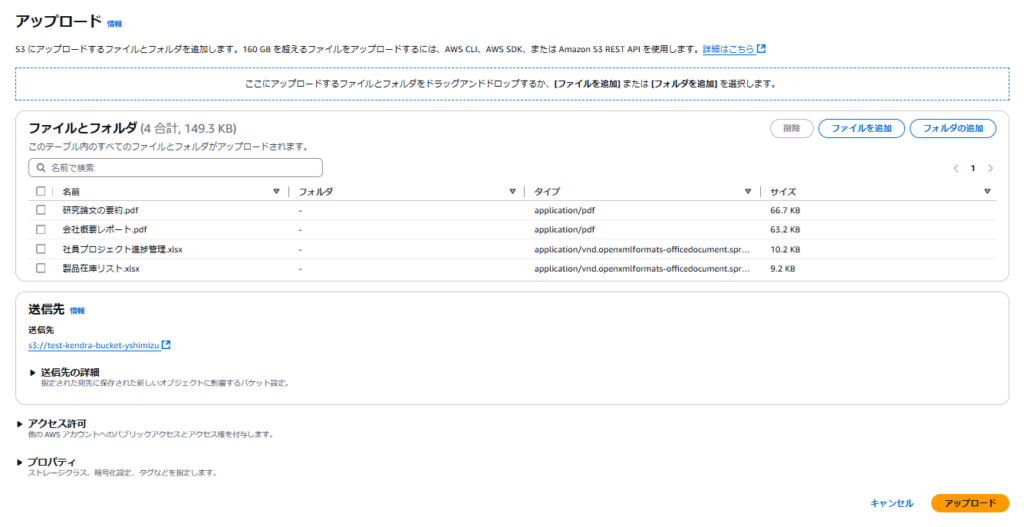
本検証ではpdfとexcelファイルを利用して作業を進めていきます。
なお、今回のサンプルデータはChatGPTを利用して以下のサンプルデータを生成してもらいました。
こういう時ChatGPTって便利ですよね。
PDFサンプルデータ①:会社概要レポート.pdf
/* markdown */
# 株式会社サンプルテック 会社概要レポート
## 概要 株式会社サンプルテックは、革新的なITソリューションを提供する企業です。主な事業分野は以下の通りです:
- ソフトウェア開発
- クラウドサービス
- データ解析
## 主要プロジェクト
1. クラウドプラットフォーム構築プロジェクト
最新のクラウド技術を用いた、柔軟かつスケーラブルなシステムの構築。
2. AIによるデータ解析プロジェクト
機械学習技術を利用し、顧客のビジネス課題の解決を支援。
## 今後の展望
- グローバル市場への進出
- 新規事業の開発と既存事業の強化
- 技術革新と持続可能な成長の実現
PDFサンプルデータ②:研究論文の要約.pdf
/* markdown */
# 研究論文要約:データセマンティック検索の新手法
## 研究背景
近年、ビッグデータ時代の到来に伴い、データ検索の効率化が急務となっています。特に、セマンティック検索技術は、単なるキーワード一致を超えた文脈理解に基づく検索結果を提供します。
## 研究目的
- 文脈と意味に基づいた高度な検索アルゴリズムの開発
- 従来手法との比較実験による有効性の検証
## 主要手法
- 自然言語処理(NLP)の最新技術を採用
- 機械学習モデルによるトピック抽出と文脈分析
## 結果と考察
- 従来の検索システムに比べ、検索精度が約25%向上
- ユーザー満足度の向上が期待されるExcelサンプルデータ①:製品在庫リスト.xlsx
Excelサンプルデータ②:社員プロジェクト進捗管理.xlsx
1. Indexの作成
Amazon Kendraのサービスページを開いて、空のインデックスを作成していきましょう。
Indexは、Indexesタブの「Create index」から作成可能です。
「Specify index details」では、「Index name」に適当な名称を入力し、「IAM role」は新規作成して同様に適当な名称を入力して次に進みます。
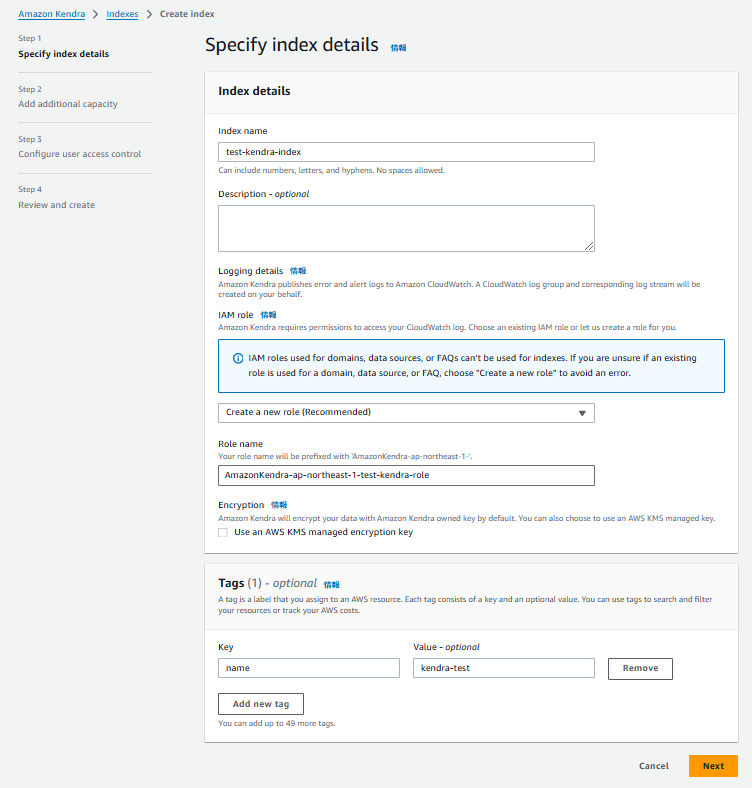
「Add additional capacity」は、検証が目的なので「Developer edition」を選択して進めます。
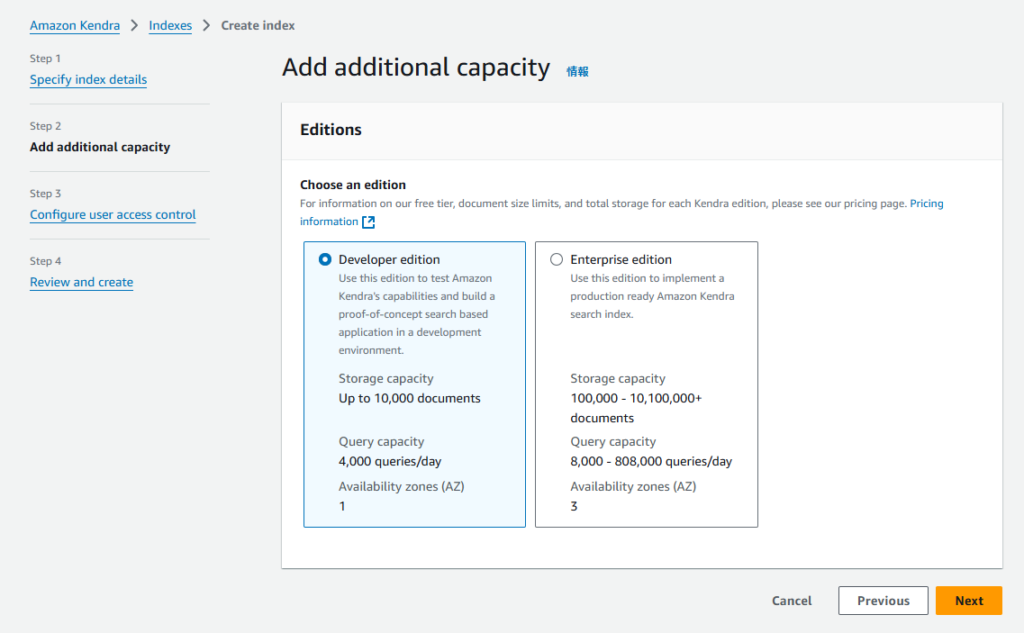
「Configure user access control」のアクセスコントロールや AWS IAM Identity Centerに関しても検証が目的ですので、連携はせずに進めます。
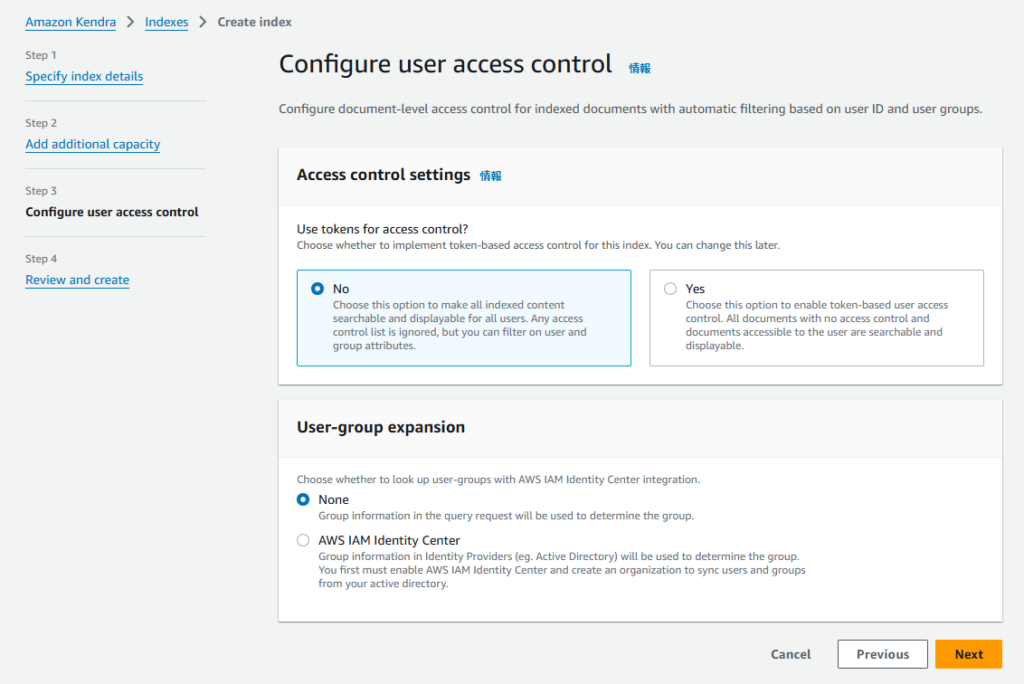
「Review and create」ではこれまでの画面で設定した設定の一覧が表示されます。
「Create」を押下することで、Indexの作成が始まります。
Indexの作成完了までにはだいたい10~20分程度かかります。
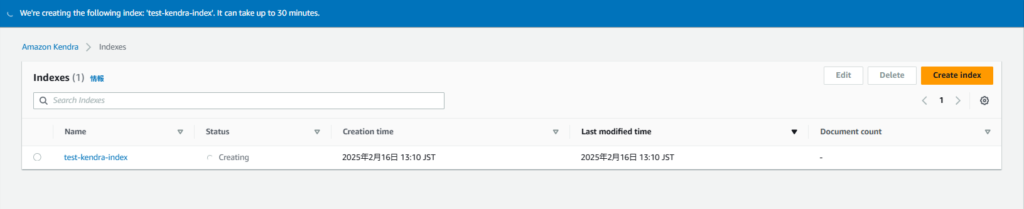
2. データソースの追加
Indexの作成が完了次第、データソースを追加していきましょう。

今回は事前準備としてS3バケットに追加したPDFファイルとExcelファイルをデータソースとして利用していきます。
作成したIndexを選択して、Data sourceタブから「Sample S3 connector」の「Add dataset」を選択します。
「Sample AWS documentation」と間違えないよう気を付けてください。
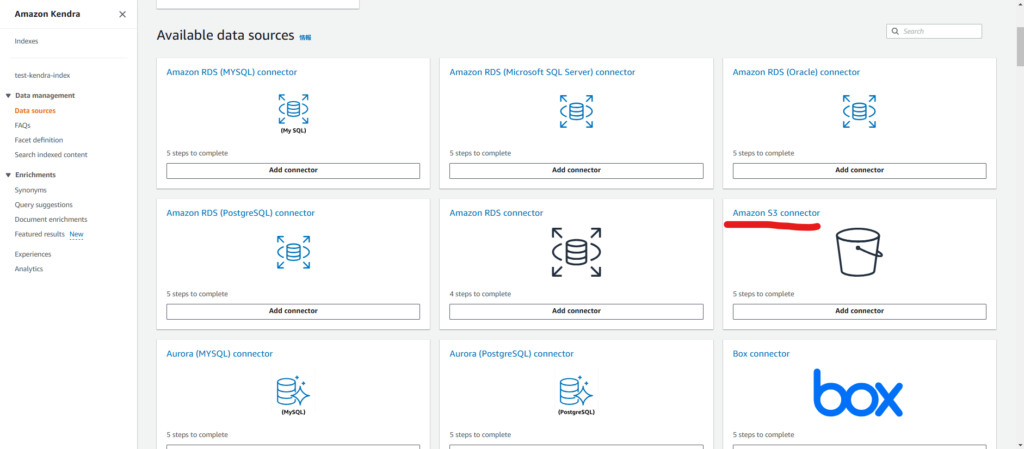
「Specify data source details 」では「Data source name」に適当な名称を入力し、「Default language of source documents」をJapaneseに変更して次に進みます。
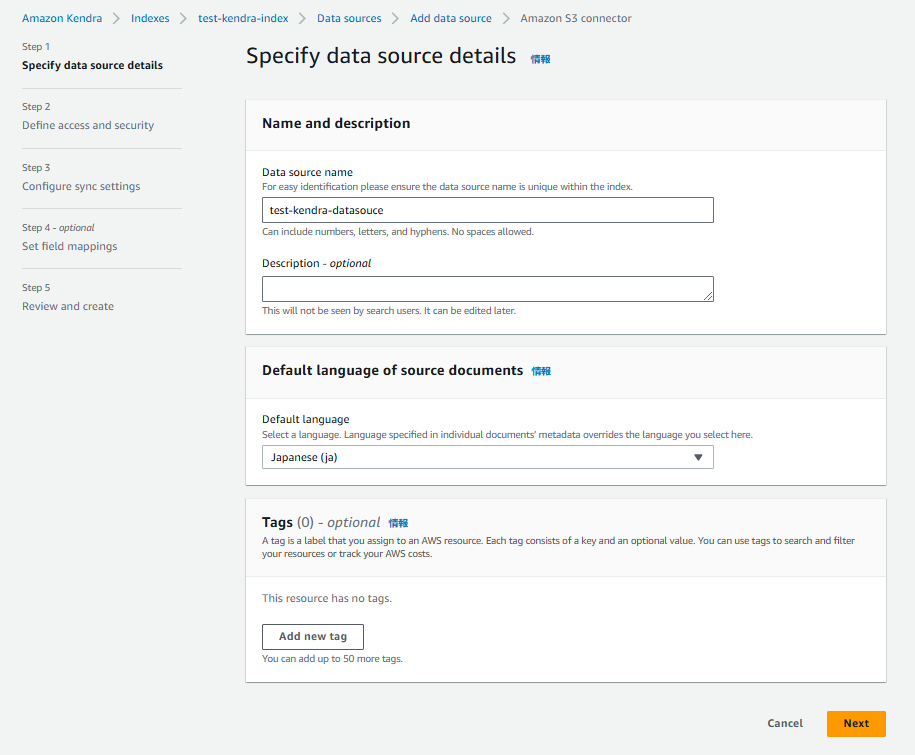
「Define access and security」では「IAM role」を新規作成し、適当な名称を入力します。
「Configure VPC and security group」に関しては一時的な検証目的なので設定せず次に進みます。
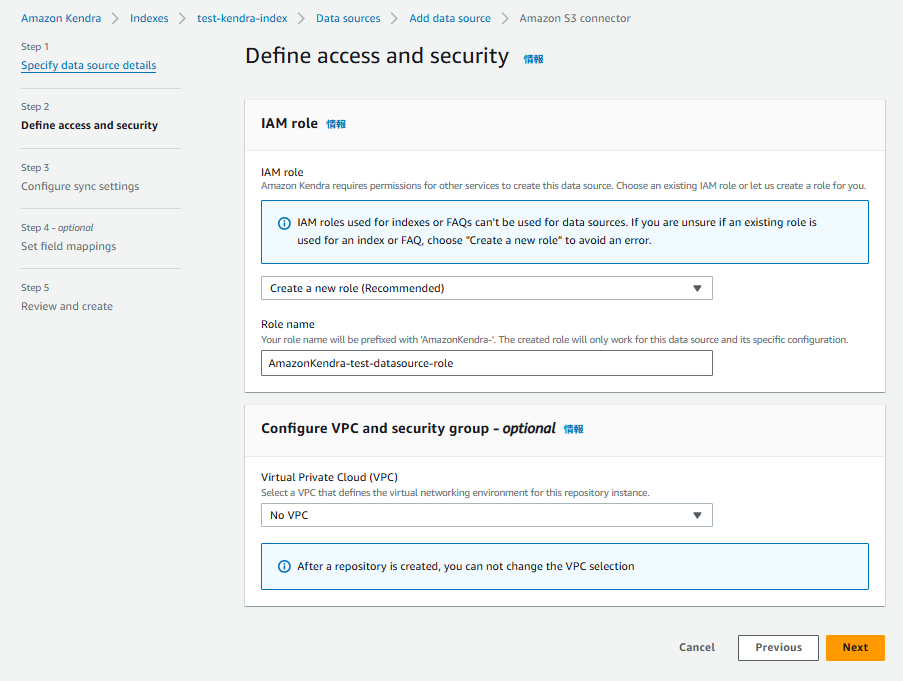
「Configure sync settings」では「Enter the data source location」で事前準備として作成したS3バケットを選択して、「Sync run schedule」で「Run on demand」を選択したら次に進みます。
「Set field mappings」はデフォルトのまま次へ進みます。
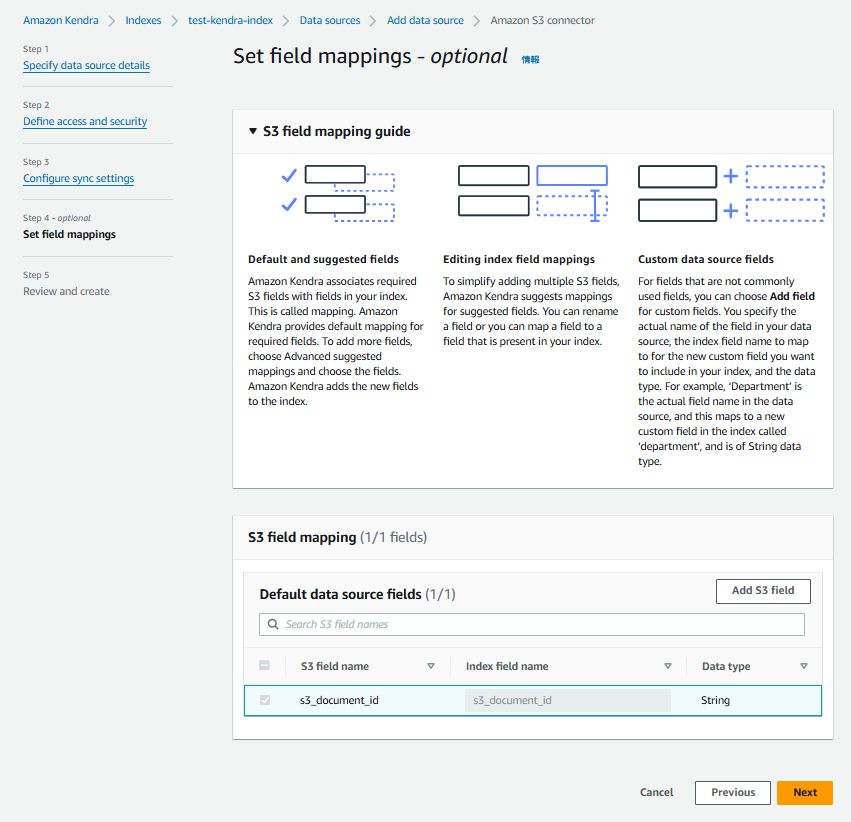
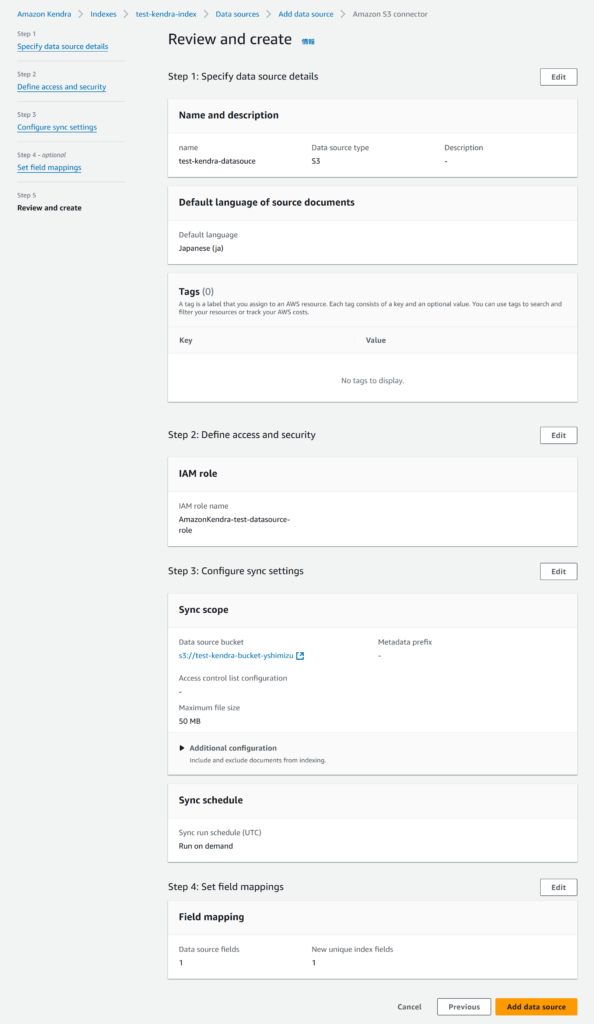
最後にこれまでの設定を確認して問題なければデータソースを作成しましょう。
データソースの作成が完了したら「Sync now」を押下してS3バケット内の情報を同期させます。
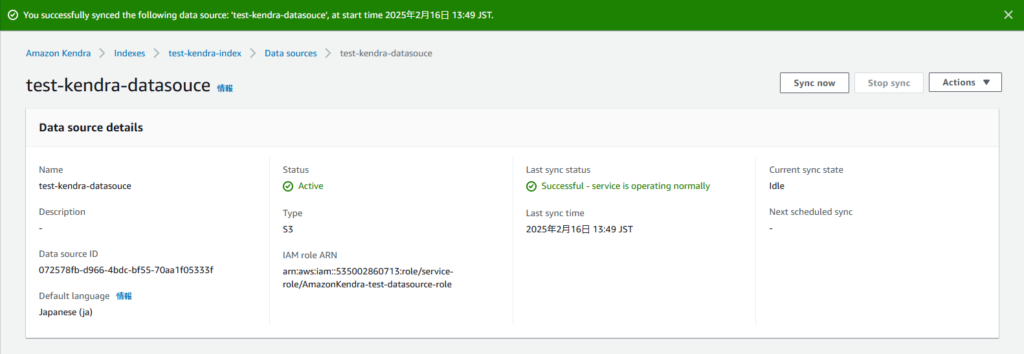
ここまでで設定自体はすべて完了となります。
それではセマンティック検索機能の検証に移っていきましょう。
セマンティック検索の検証
画面左のメニューから「Search indexed content」を押下して検索画面に遷移します。
設定(スパナアイコン)から言語をJapaneseに変更して保存すれば日本語でのセマンティック検索が可能になるようです。
配置したファイルに関連する質問文をテキストフィールドに入力してエンターを押すと回答が返ってきます。
質問①
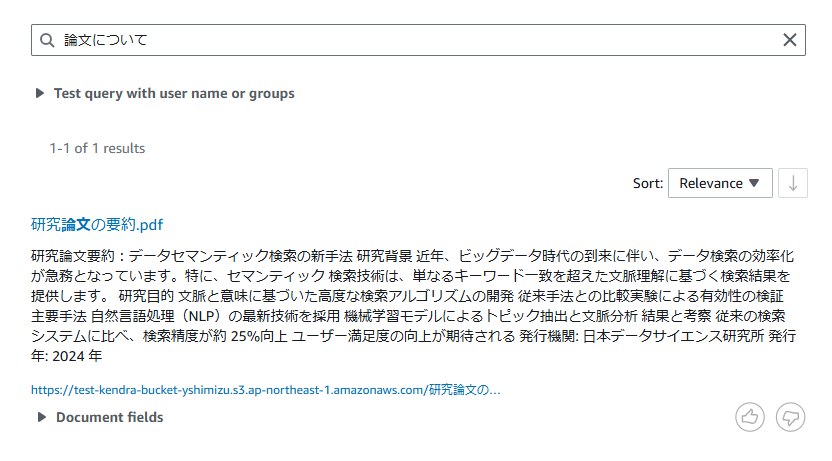
質問②
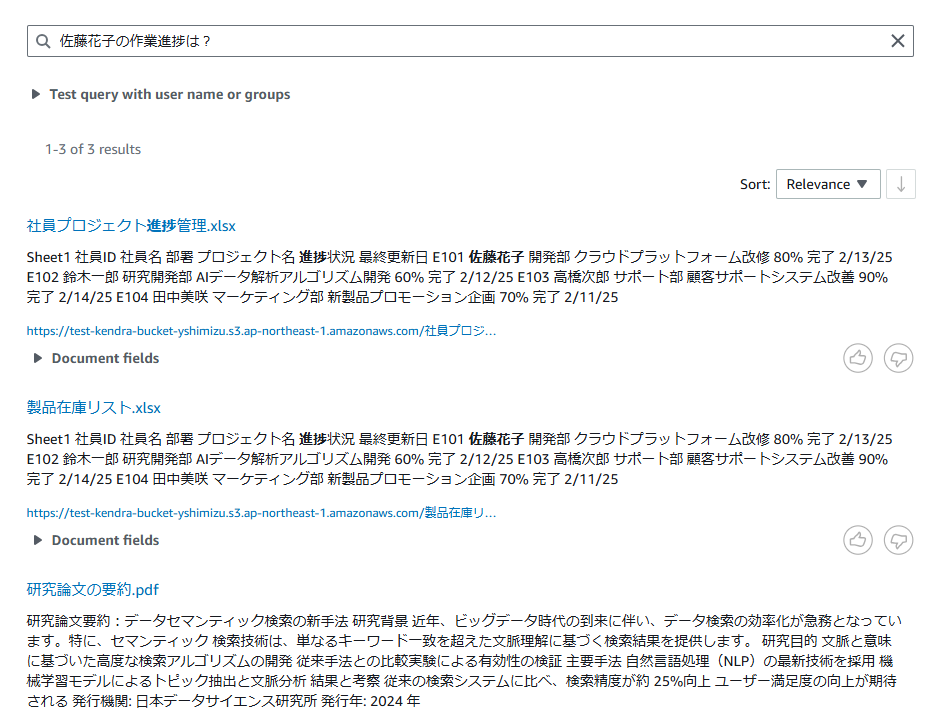
質問③
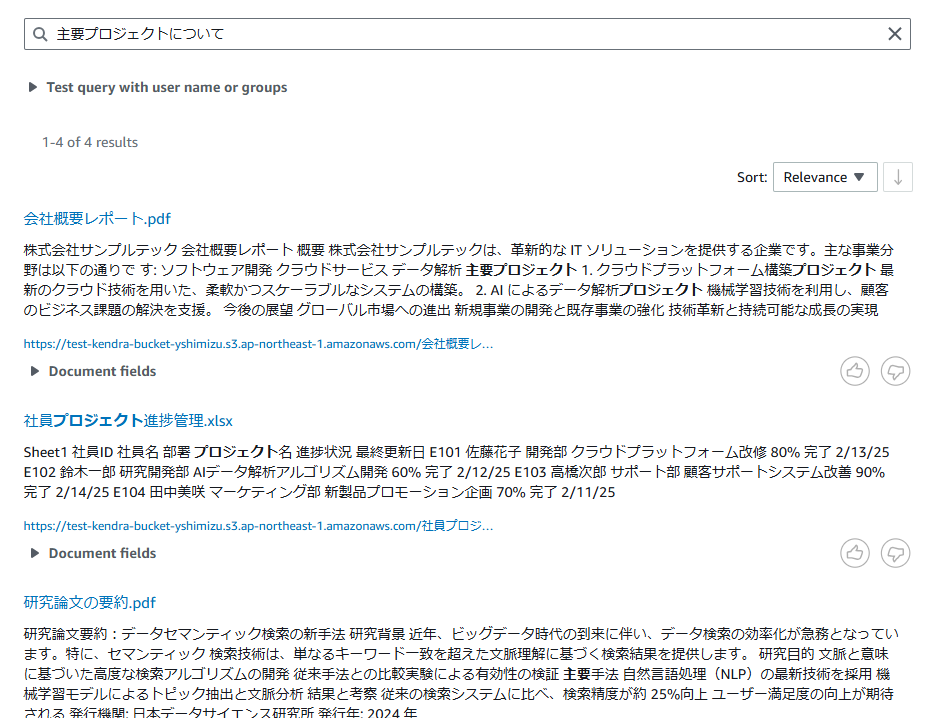
質問内容に対して関連度順で対応するファイルが一覧表示されるみたいですね。
おわりに
今回の記事では、Amazon KendraとS3を用いたセマンティック検索機能の実装を試してみました。
Kendraの機能はあくまで「企業の非構造化データを検索可能にする」という部分に留まるので、より精度の高い検索機能を実現するためにはAmazon Bedrockを利用するなり組み合わせるなりする必要があるのかなとも思っています。
また、調べてみたところ「Amazon Kendra GenAI Index」という機能が2024年12月にリリースされていたらしく、従来の Kendra の検索機能に加え、生成AI向けの拡張ができるようになっていて、さらなる検索精度向上が見込めるとのこと…。
今後はその辺りも組み合わせも調査してみて、より実践的なRAG構築のスキルを身に付けていこうと思います!
参考:Index types in Amazon Kendra – Amazon Kendra
