







【AWS】Knowledge base for Amazon Bedrockをお手軽に使ってみよう

はじめに
みなさま、こんにちは。
クラウドソリューション第2グループ入社2年目のkugishimakです。
この記事ではKnowledge base for Amazon Bedrockでモデルを使用できるまでの流れを説明いたします。
目次
Knowledge base for Amazon Bedrockとは?
Amazon BedrockのKnowledge baseは、生成AIを活用した情報検索や質問応答を強化するための機能です。
従来、生成AIモデルに特定の知識やデータを反映させるには、ファインチューニングや独自のデータセットを用意する必要がありましたが、
Knowledge baseを使えば、これをより簡単に実現できます。
具体的には、S3に保存したドキュメントやデータソースをKnowledge baseに取り込み、検索インデックスを生成します。
ユーザーが生成AIに質問をすると、このKnowledge baseから関連情報を取得し、モデルがそれを参照して回答を生成するため、
最新の情報や特定のドメインに特化した応答が可能になります。
たとえば、製品マニュアルやFAQをKnowledge baseに取り込んでおけば、
ユーザーが「この製品の最新バージョンの対応OSは?」といった質問をした場合に、生成AIが最新の情報を反映した回答を返してくれます。
これにより、生成AIの「知識不足」や「誤回答」のリスクが減り、より正確かつスムーズな回答が期待できます。
このブログでは、Knowledge base for Amazon Bedrockのセットアップから基本的な動作確認まで、実際に触っていきます。
使用までの流れ
使用までの簡単な流れは下記のとおりです。
今回の実践では事前に、Amazon Bedrockでモデル使用のアクセス許可を行っておく必要があります。
アクセス許可の方法について分からない方は下記のブログに記載しておりますので参考にどうぞ!
【AWSの生成AI】Amazon Bedrock ~実践編~| 開発者ブログ | 株式会社アイソルート
実際に触ってみる
では、実践していきます。
1. データの準備
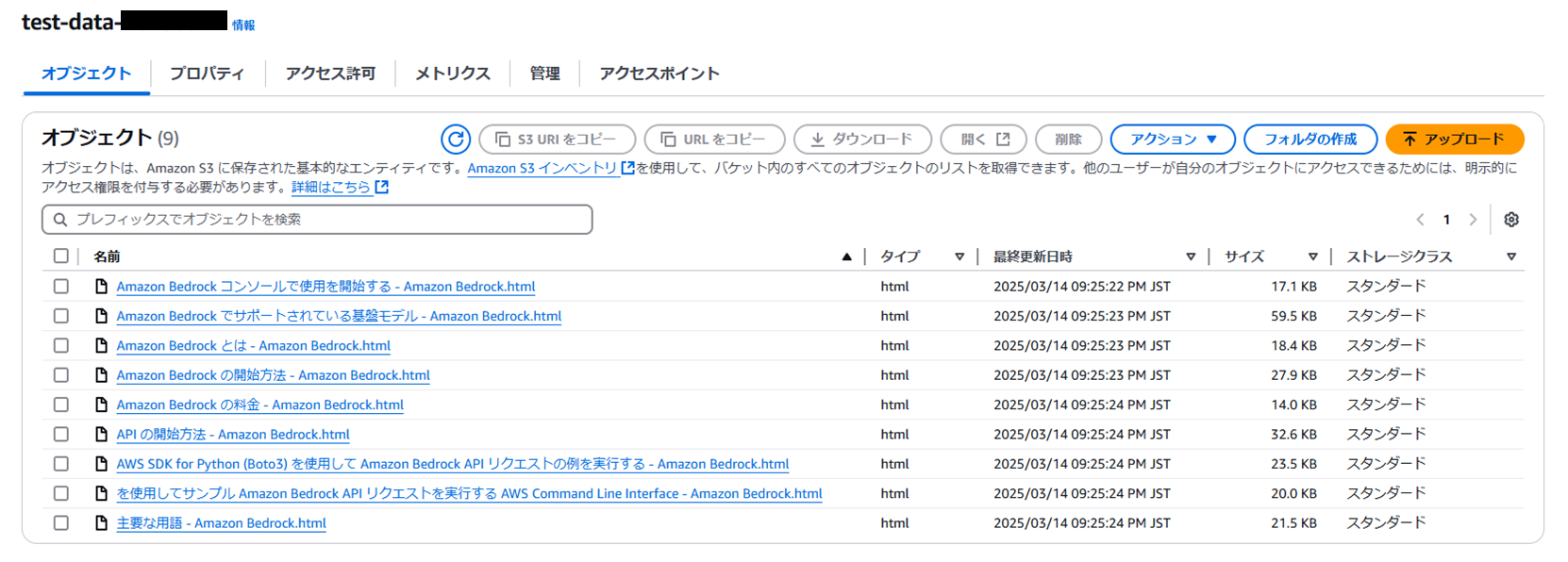
今回使用するデータは、Amazon BedrockのAWS公式ドキュメントのhtmlファイルを9つ用意しました。
こちらをS3バケットにアップロードしておきます。
2. ナレッジベースを作成する
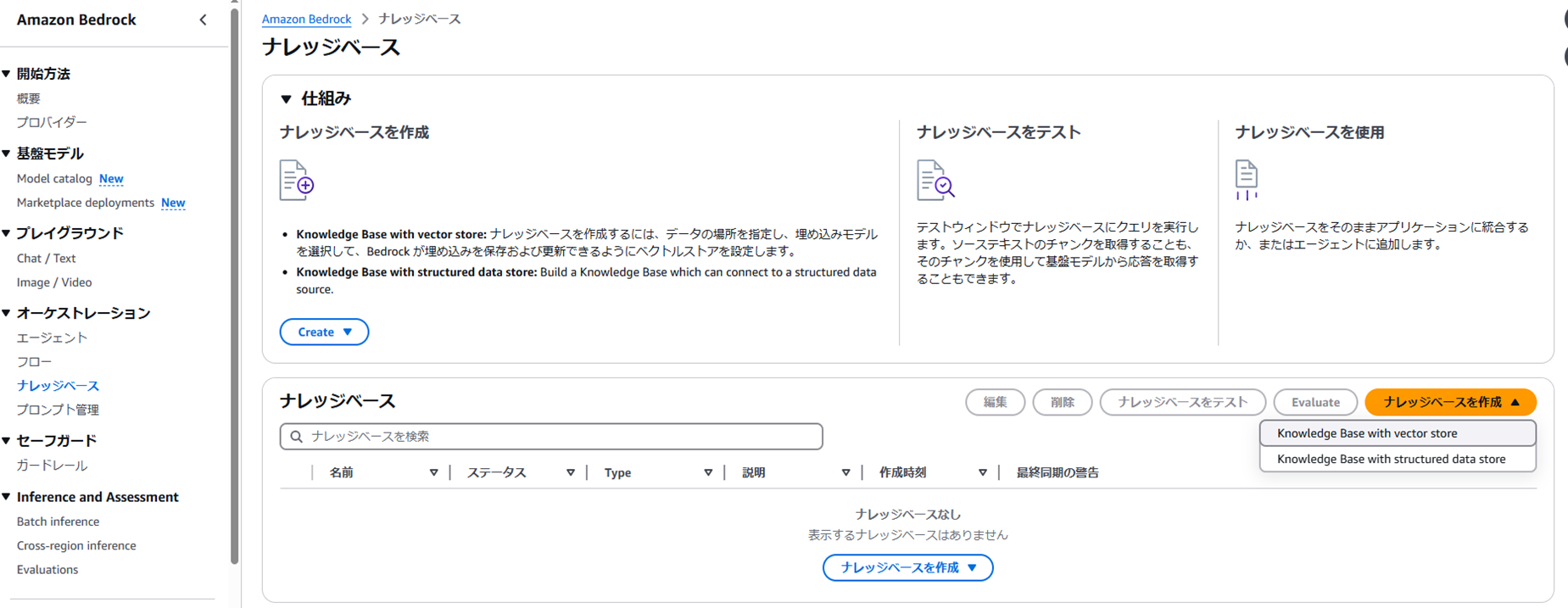
Amazon Bedrockからオーケストレーション>ナレッジベースを選択します。
画像のような画面が表示されますので、ここからナレッジベースの作成>Knowledge Base with vector storeを今回は選択します。
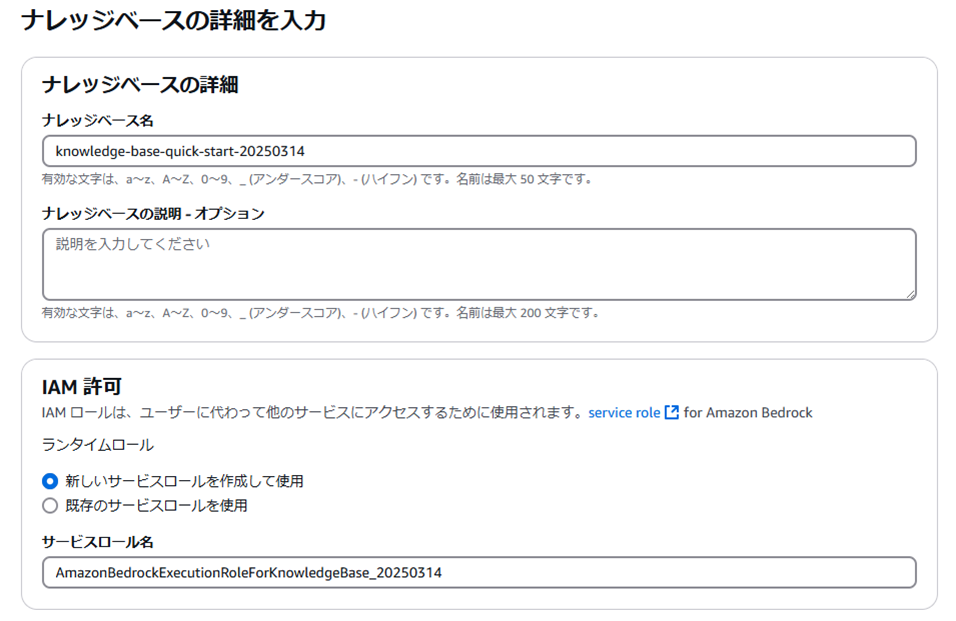
ナレッジベース名やサービスロール名は最初から入力されており、任意で変更しても問題ないです。
IAMロールの設定を事前に行わなくても、新しいものを自動で作成してくれます。
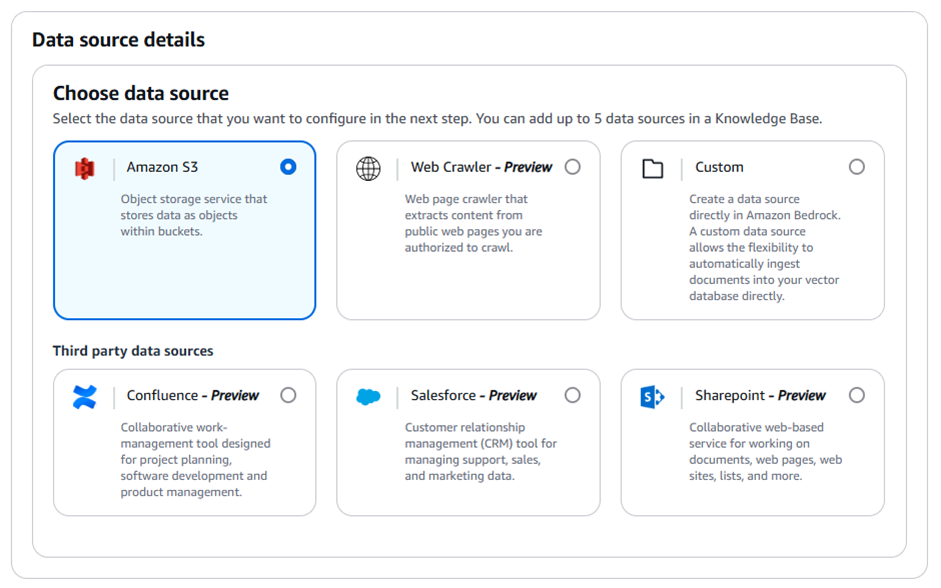
次に使用するデータソースを選択します。
ナレッジベースには最大5つのデータソースを追加できます。
今回使用するデータソースはS3なのでS3を選択します。
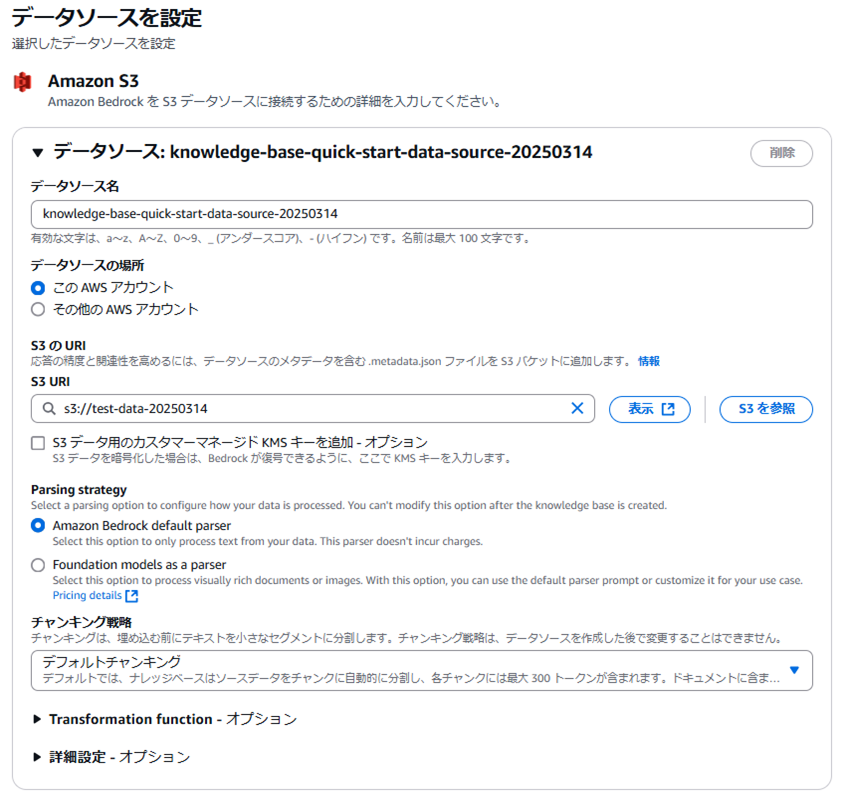
データソースを設定します。
データソース名も最初から入力されており、任意で変更しても問題ないです。
S3の場所やバケット名の指定、Parsing strategyの選択は各々の設定に合わせて行ってください。
Parsing strategyとは?
解析オプションを選択して、データの処理方法を設定できます。
ナレッジベース作成後にこのオプションを変更することはできません。
Amazon Bedrockデフォルトのパーサー
データからテキストのみを処理するには、このオプションを選択します。このパーサーには料金はかかりません。
パーサーとしてのファウンデーションモデル
視覚的に豊かな文書や画像を処理するには、このオプションを選択します。
このオプションを使用すると、デフォルトのパーサープロンプトを使用したり、ユースケースに合わせてカスタマイズしたりできます。
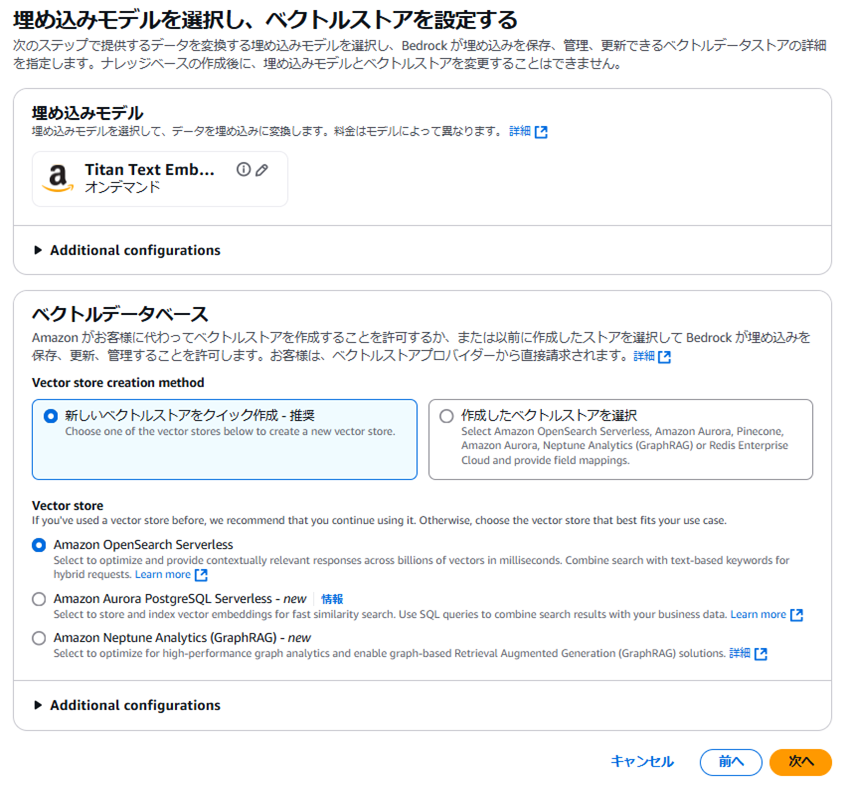
使用する埋め込みモデルを選択します。
今回は「Titan Text Embeddings V2 」を使用しました。
ベクトルデータベースについて、ベクトルストアを作成するのは今回が初めてですので
「新しいベクトルストアをクイック作成」を選択します。
以前にベクトルストアを使用したことがある場合は、引き続き使用することをお勧めします。
今回ベクトルストアは「Amazon OpenSearchサーバーレス」を選択しました。
Amazon OpenSearchサーバーレス
何十億ものベクトルに対して、ミリ秒単位で最適化し、コンテキストに関連したレスポンスを提供するために選択します。
検索とテキストベースのキーワードを組み合わせて、ハイブリッドなリクエストを実現します。
Amazon Aurora PostgreSQLサーバーレス
高速な類似検索のために、ベクトル埋め込みを保存しインデックス化するために選択します。
SQLクエリを使用して、検索結果をビジネスデータと組み合わせます。
Amazon Neptune Analytics (GraphRAG)
高性能なグラフ分析に最適化し、グラフベースの検索拡張世代(GraphRAG)ソリューションを実現するために選択します。
設定が完了したら確認を行い、問題なければ作成します。
私の環境の場合、作成には5分ほどかかりました。
作成が完了すると、ナレッジベースとデータソースが確認できます。

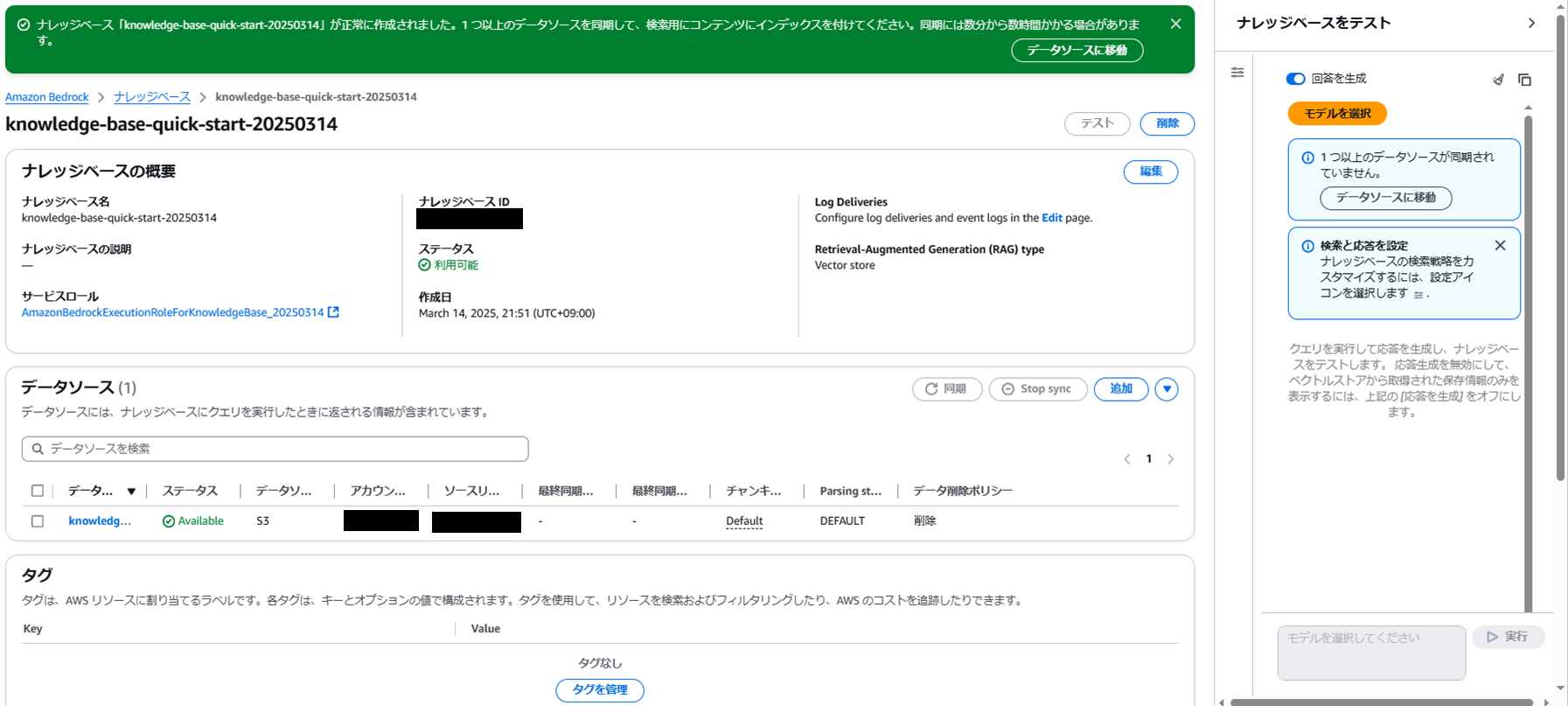
3. データソースの同期
次にデータソースの同期を行います。
作成したデータソースを選択して「同期」を押下します。
私の環境の場合、作り立てでデータの追加も行っていないので1分ほどで完了しました。

4. モデルのテスト
同期まで完了すればいよいよモデルのテストです。
「テスト」を押下すると使用するモデルの選択とその設定画面が表示されます。
今回のテストでは下記2つのモデルを使用しました。
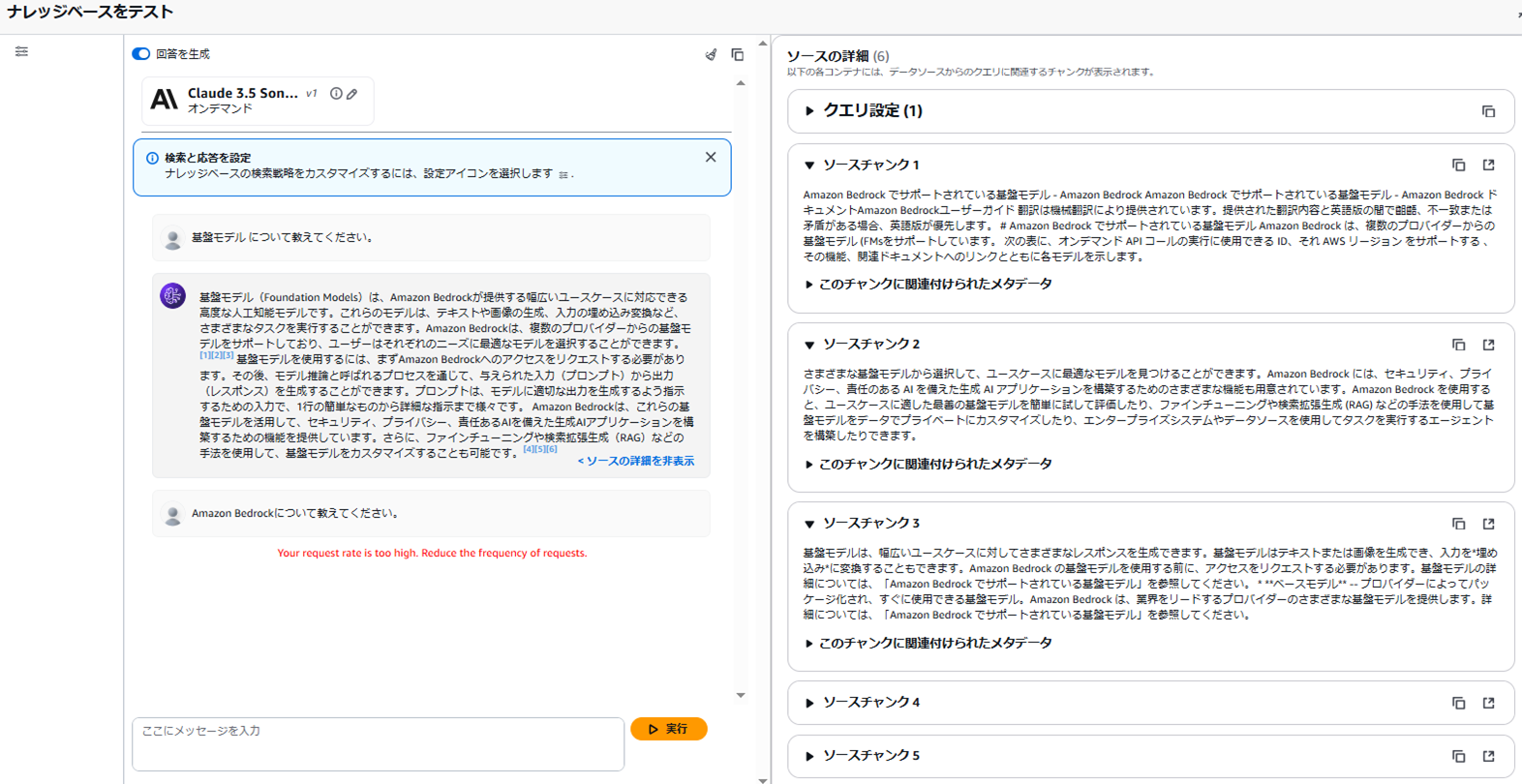
モデル1:Claude 3.5 Sonnet
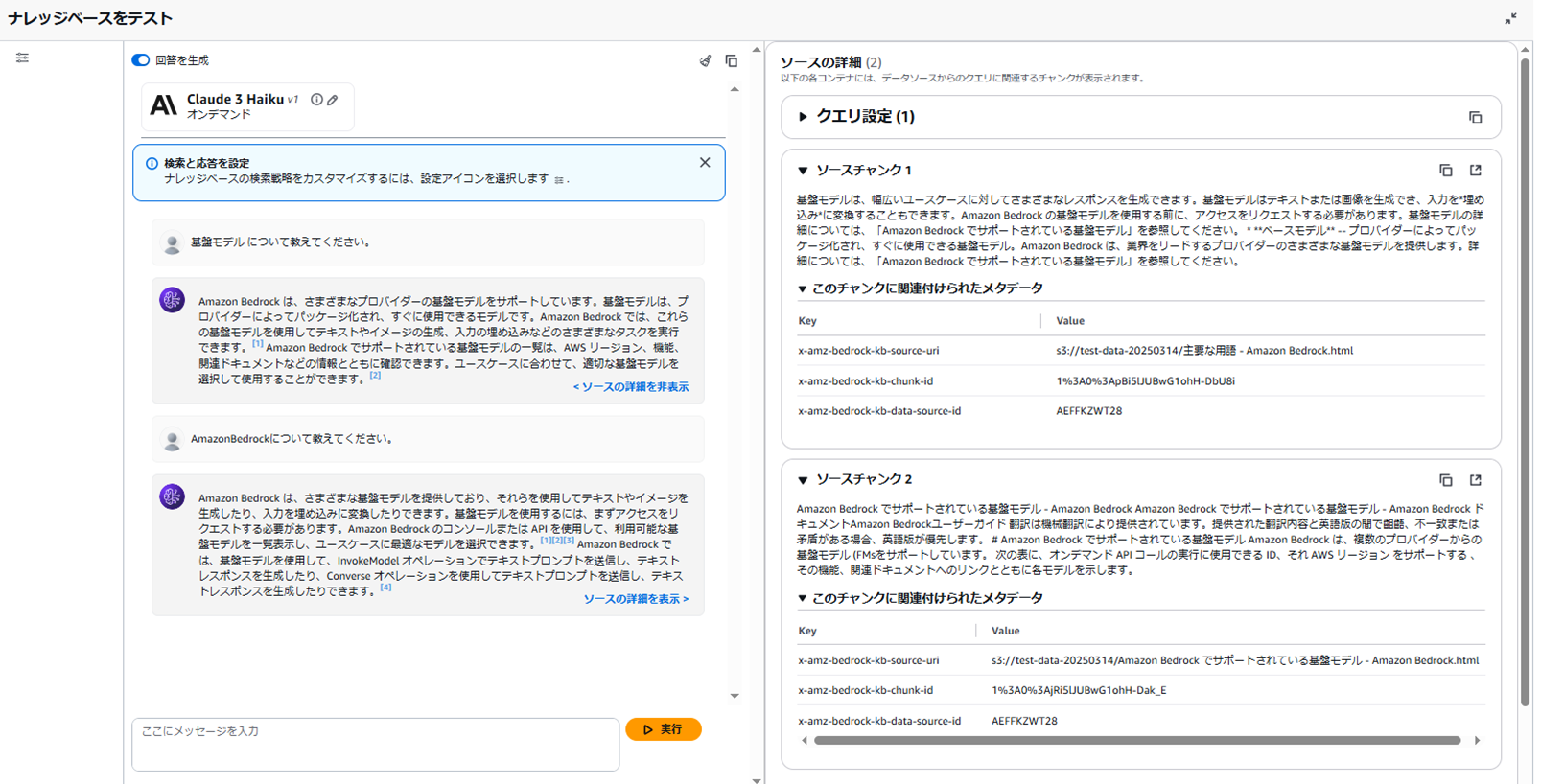
モデル2:Claude 3 Haiku
結果は以下の通りです。
回答に対してソース元が何かまで表示されています。
Claude 3.5 Sonnetは、より丁寧で詳細な説明が印象的でした。
プロンプトとは何かといった専門用語への補足や、実際の使い方の簡単な説明もあり、
読み手が「実際に使う」ことを意識している文章のように感じます。
一方、Claude 3 Haikuは情報量を抑えつつも、要所を的確に抑えている端的な解答が印象的で、
概要だけを知りたい場面には適していると感じます。
▼モデル1:Claude 3.5 Sonnet
▼モデル2:Claude 3 Haiku
おわりに
本記事では、Knowledge base for Amazon Bedrockで実際にモデルを使用しテストするまでの流れを説明しました。
今回はhtmlファイルをデータとして使用してみましたが、ほかのデータを使用した際の結果も見てみたいですね。
構築まで非常に簡単でシンプルなので皆様も是非お試しください。
それではまた👋
