








自然言語でデータ分析をするアプリを作ってみた – LLM × DuckDBで実現するインタラクティブ分析
こんにちは。アイソルートのshiba.mです。
今回は、「今月のモバイルユーザー数は?」「デバイス別のセッション割合を円グラフで表示して」といった日本語での質問に対して、自動でデータを分析し、グラフ付きの回答を返すデータ分析アプリのPoCを作ったので、その技術的な内容をご紹介します。
LangChain + OpenAI GPT-4o-mini + DuckDBを組み合わせることで、Parquet形式のデータに対して自然言語でクエリを投げられるシステムを構築しました。開発期間は約2週間で、実用レベルのパフォーマンスとコスト効率を実現できています。
目次
TL;DR
- 自然言語でのデータ分析: 日本語での質問に対して自動でSQL生成・実行し、グラフ付きで回答
- 技術スタック: LangChain + OpenAI GPT-4o-mini + DuckDB + FastAPI + React
- Parquet汎用対応: GA4に限らず、Parquet形式のデータがあればどんなデータでも分析可能
- 実用的なパフォーマンス: クエリ応答時間3-5秒、月1000クエリで$10未満の運用コスト
システム概要
何ができるのか
このシステムは、Parquet形式で保存されたデータに対して自然な日本語で質問すると、LLMが意図を理解してSQLを生成し、データを分析して結果を返すものです。
今回はGoogle Analytics 4のデータを例として使いましたが、ECサイトの売上データ、IoTセンサーデータ、アプリのログデータなど、Parquet形式で保存されているデータであれば、スキーマ情報を与えるだけで同様に分析できます。
主な機能:
- 自然言語からのSQL自動生成
- データ分析とグラフ可視化(折れ線グラフ、棒グラフ、円グラフ)
- エラー時の適切なフィードバック
基本的な処理フロー
ユーザー質問
↓
OpenAI GPT-4o-mini (SQL生成)
↓
DuckDB (Parquet直接読み込み)
↓
結果の可視化 (Plotly)
↓
インサイト生成
↓
回答表示
技術構成とアーキテクチャ
使用した技術スタック
AI・処理系:
- LangChain: LLM操作の抽象化とプロンプト管理
- OpenAI GPT-4o-mini: コスト効率を重視したモデル選定
- DuckDB: 分析用の高速データベースエンジン
アプリケーション:
- FastAPI: バックエンドAPIフレームワーク
- Plotly: インタラクティブなグラフ生成
データ形式:
- Parquet: 列指向フォーマットで効率的なデータ保存
実際の動作デモ
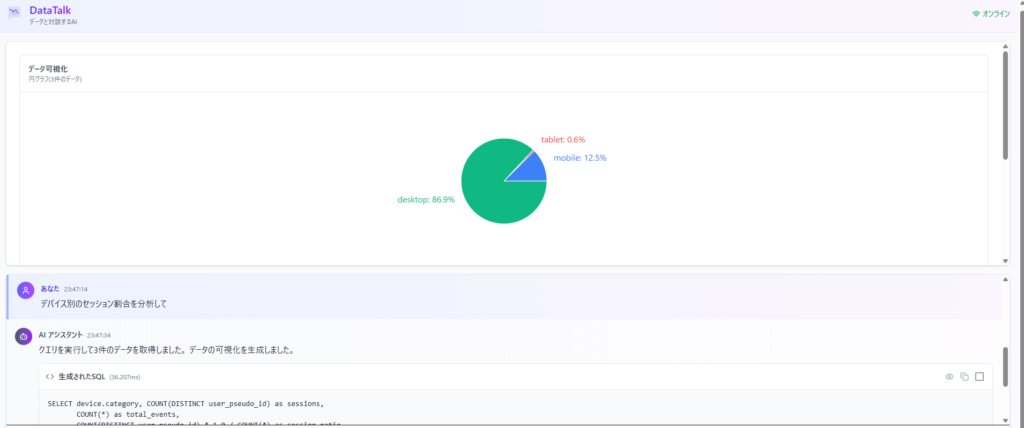
デモ1: デバイス別のセッション割合分析
ユーザー質問: 「デバイス別のセッション割合を分析して」
システムの処理:
- LLMが「デバイス別」「割合」のキーワードから意図を理解
- DuckDB用のSQLを自動生成(GROUP BYとCOUNT集計)
- クエリ実行(処理時間: 約2秒)
- 「割合分析」として円グラフを表示
実行結果:
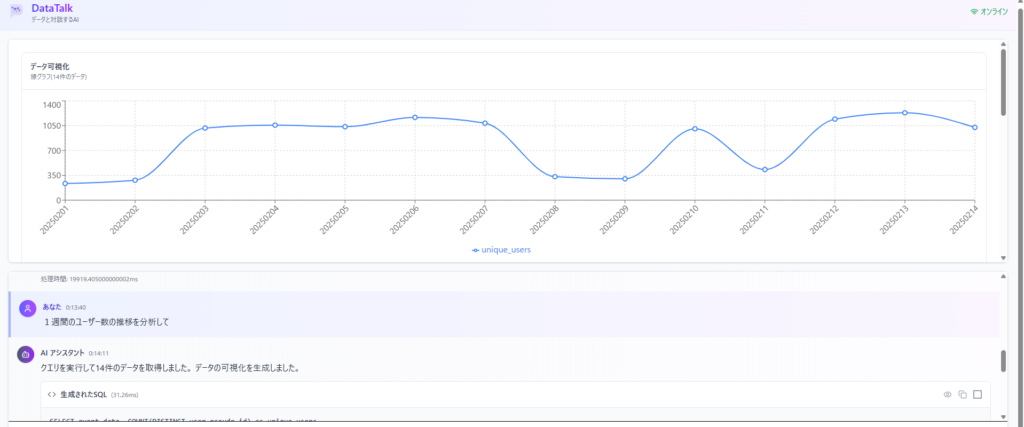
デモ2: 時系列でのユーザー数推移分析
ユーザー質問: 「1週間のユーザー数推移を分析して」
システムの処理:
- 「推移」というキーワードから時系列分析と判断
- 日付ごとのユニークユーザー数を集計するSQLを生成
- LLMがトレンド分析に最適な折れ線グラフを選択
実行結果:
実装の技術的なポイント
1. データソース特化のプロンプトエンジニアリング
LLMにデータのスキーマ情報を与えるだけでなく、実際のクエリ例をいくつか含めることで、SQL生成の精度を高めました。
プロンプト構成:
# スキーマ情報
schema_info = """
テーブル構造:
- event_date: 日付(YYYYMMDD形式)
- device.category: デバイス種別(desktop/mobile/tablet)
- geo.country: 国情報
- user_pseudo_id: ユーザーID
...
"""
# クエリ例
examples = """
例1: 「デバイス別の件数」
SELECT device.category, COUNT(*)
FROM read_parquet('/data/*.parquet')
GROUP BY device.category
例2: 「先週のモバイルユーザー」
SELECT COUNT(DISTINCT user_pseudo_id)
FROM read_parquet('/data/*.parquet')
WHERE device.category = 'mobile'
AND event_date >= '20250920'
"""
汎用化のポイント:
新しいデータソースを追加する際は、以下を更新するだけで対応できます:
- スキーマ情報の定義
- 3-5個のクエリ例の追加
- データソース固有のビジネスロジック(あれば)
今回はGA4データを使いましたが、売上データなら「売上」「購入」「顧客」などの用語を、IoTデータなら「センサー」「温度」「測定値」などの用語を、クエリ例に含めることで対応できます。
2. DuckDBの活用
データがParquet形式であれば、DuckDBを使うことで高速かつシンプルに分析できます。DuckDBはParquetファイルを直接読み込めるため、データベースへのインポートが不要です。
DuckDBの利点:
- Parquetファイルを直接クエリ可能
- 分析用途に最適化された高速処理
- SQLiteのように埋め込み型で運用が簡単
- 複数のParquetファイルをワイルドカードで読み込み可能
実装例:
import duckdb
# Parquetファイルを直接クエリ
conn = duckdb.connect(':memory:')
result = conn.execute("""
SELECT device.category, COUNT(*) as count
FROM read_parquet('/data/ga4/*.parquet')
GROUP BY device.category
""").fetchall()
別のデータソースでも同様:
# ECサイトの売上データ
result = conn.execute("""
SELECT product_category, SUM(amount) as total_sales
FROM read_parquet('/data/orders/*.parquet')
WHERE order_date >= '2025-09-01'
GROUP BY product_category
""").fetchall()
3. パフォーマンス測定と最適化
開発時に各処理の時間を計測し、ボトルネックを特定しました。
実測データ:
- SQL生成: 平均3.2秒
- SQL実行: 平均1.8秒
- グラフ生成: 平均0.8秒
- インサイト生成: 平均11.2秒
- 合計: 平均17秒
インサイト生成に時間がかかることが分かったため、この部分は非同期処理にして、先に結果を表示するなどの改善も検討できます。
実装の流れ:
- データの特性(カテゴリ数、数値範囲、時系列の有無)を分析
- ユーザーの質問意図(比較、推移、割合など)を抽出
- メインのグラフタイプを決定
- データの別の側面を可視化できる代替案を生成
これにより、ユーザーは提示されたグラフだけでなく、「こういう見方もできる」という新たな気づきを得られるようになりました。
4. 運用コストの試算
月1000クエリを実行した場合のコスト:
OpenAI API (GPT-4o-mini):
- SQL生成: 1000回 × $0.002 = $2.00
- インサイト生成: 1000回 × $0.001 = $1.00
インフラ (AWS等): 約$5.00
合計: 約$8.00/月
コスト効率を重視してGPT-4o-miniを選定したことで、実用的な範囲に収まりました。
さいごに
今回は、LangChain + OpenAI GPT-4o-mini + DuckDBを組み合わせた自然言語データ分析システムの構築について紹介しました。
実装のポイント:
- LangChainによる抽象化: LLM操作やプロンプト管理を体系的に実装
- DuckDBの活用: Parquetファイルの直接クエリで、ETL不要の高速分析を実現
- 代替グラフ提案: LLMによる多角的な可視化提案で、ユーザーの気づきを促進
実用性の検証:
- クエリ応答時間: 3-5秒(SQL生成 + 実行 + 可視化)
- 月1000クエリで$10未満の運用コスト
- Parquet汎用対応により、GA4以外のデータソースにも応用可能
自然言語でデータに質問できるという体験は、SQLを書けないビジネスサイドの方々にとって、データ分析のハードルを大きく下げる可能性があります。また、LLMが代替グラフを提案する機能は、データ分析の新しい視点を提供し、より深い洞察につながります。
今後の拡張案としては、以下のような機能を検討しています。
- 過去の質問履歴からの推奨クエリ提案
- 定期レポートの自動生成機能
- CSV、JSON、データベース接続など、他のデータ形式への対応
技術的にはまだ改善の余地がありますが、実用レベルのシステムを短期間で構築できることは実証できたと思います。興味のある方は、ぜひ試してみてください。
