







Firebase ML Kit AutoML Vision Edgeを使ってみた

GoogleI/O 2019にて発表されたFirebaseの新機能「Firebase ML Kit AutoML Vision Edge 」について
概要や実際に使用する際の流れを解説したいと思います!
また、「機械学習体験してみたいけど、なんか難しそう。。。」と感じている方の第一歩になれば良いかと思います!
こんにちは。
モバイルソリューショングループのyamasaki.sです。
Firebase ML Kit AutoML Vision Edgeとは?
Firebaseコンソール上に画像をアップロードするだけで、
MLの知識がなくてもお手軽にカスタムモデルを作成する事ができる機能です。
1.Firebaseプロジェクトの作成
Firebaseコンソールにアクセスして、プロジェクトを作成します。
プロジェクトの作成手順は、過去に投稿した以下の記事にも記載されています!是非、見てください!
2.データセットの作成
まずは、データセットの作成から行います。
データセット名とラベルの分類方法を選択します。
- 単一ラベル分類
- 一つの画像に対して、一つのラベルを割り当てる事ができます。
- 例) 画像:猫、ラベル:動物
- 一つの画像に対して、一つのラベルを割り当てる事ができます。
- マルチラベル分類
- 一つの画像に対して、複数のラベルを割り当てる事ができます。
- 例)画像:車、ラベル:乗り物、機械、無機物 etc
- 一つの画像に対して、複数のラベルを割り当てる事ができます。
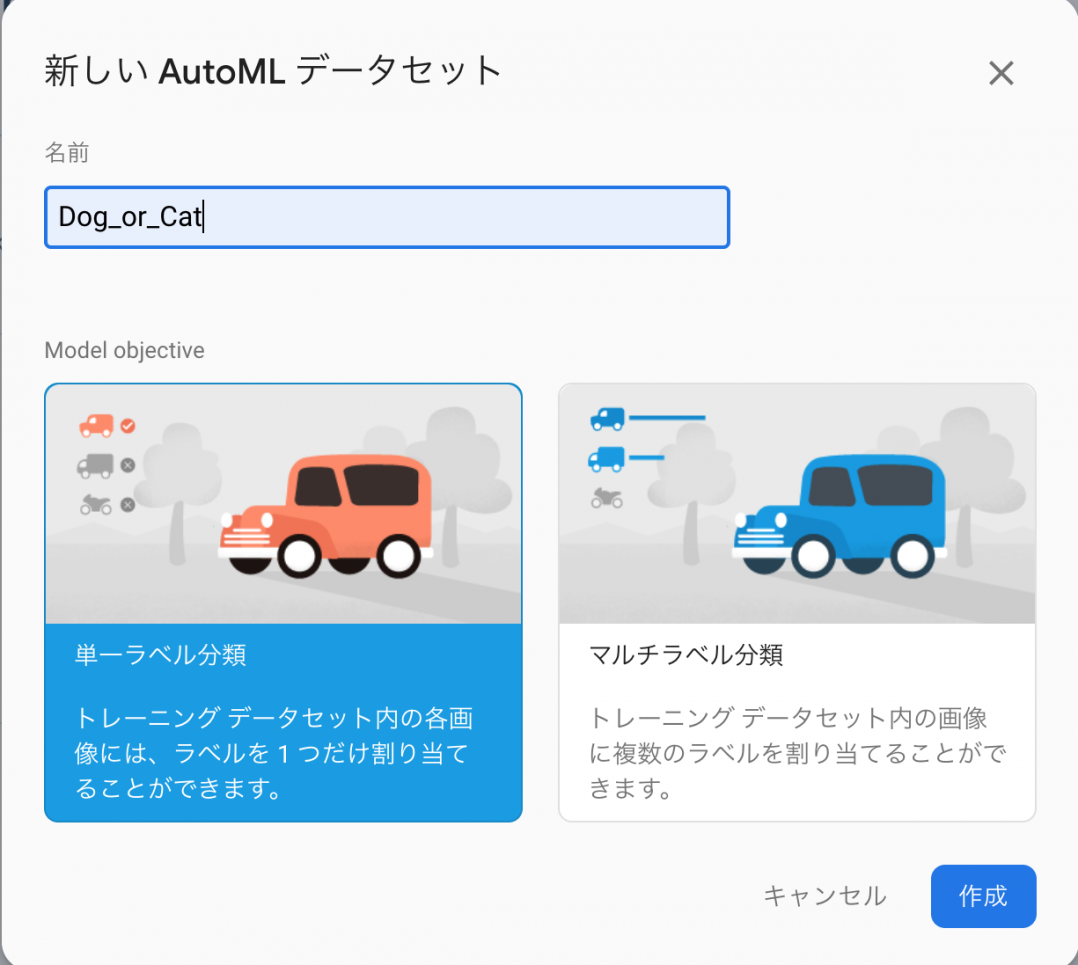
今回は、無難に犬と猫を見分けるカスタムモデルを作成してみます。
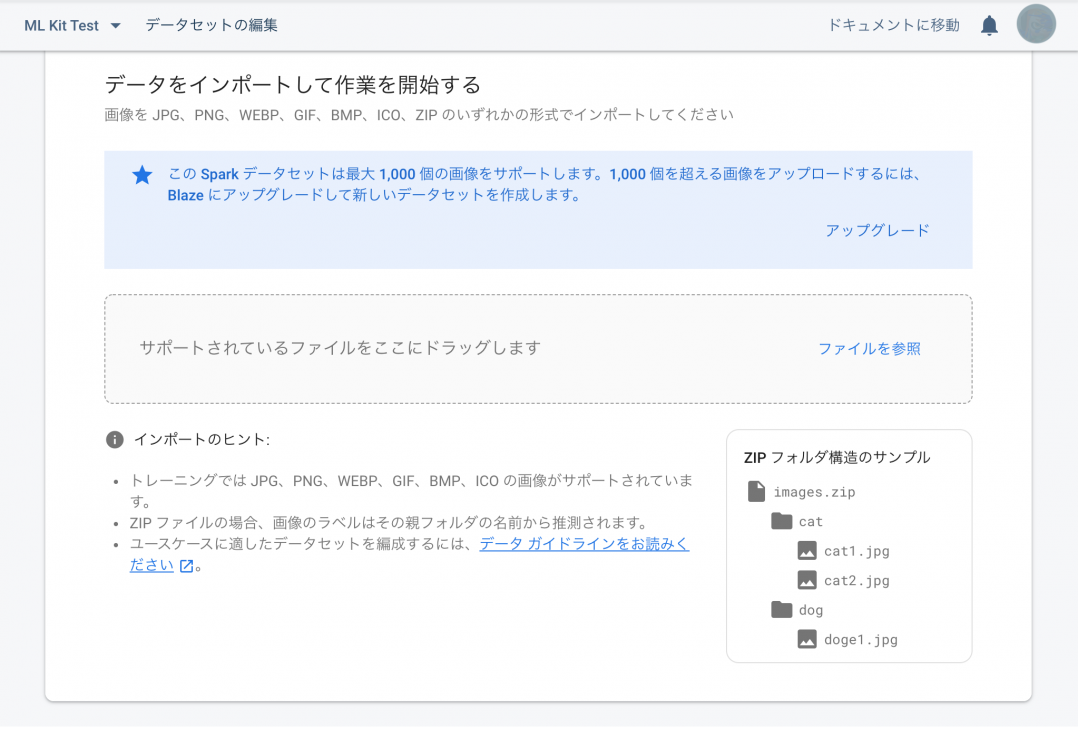
3.データの取り込み
さっそく、データを取り込んでみましょう!
1つのラベルに対して、最低10枚の画像を用意する必要があります。
また、画像が10枚以下のラベルがある場合はトレーニングを開始する事はできません!
今回は、精度をあげる為に犬と猫の画像を100枚ずつ用意して取り込みます。
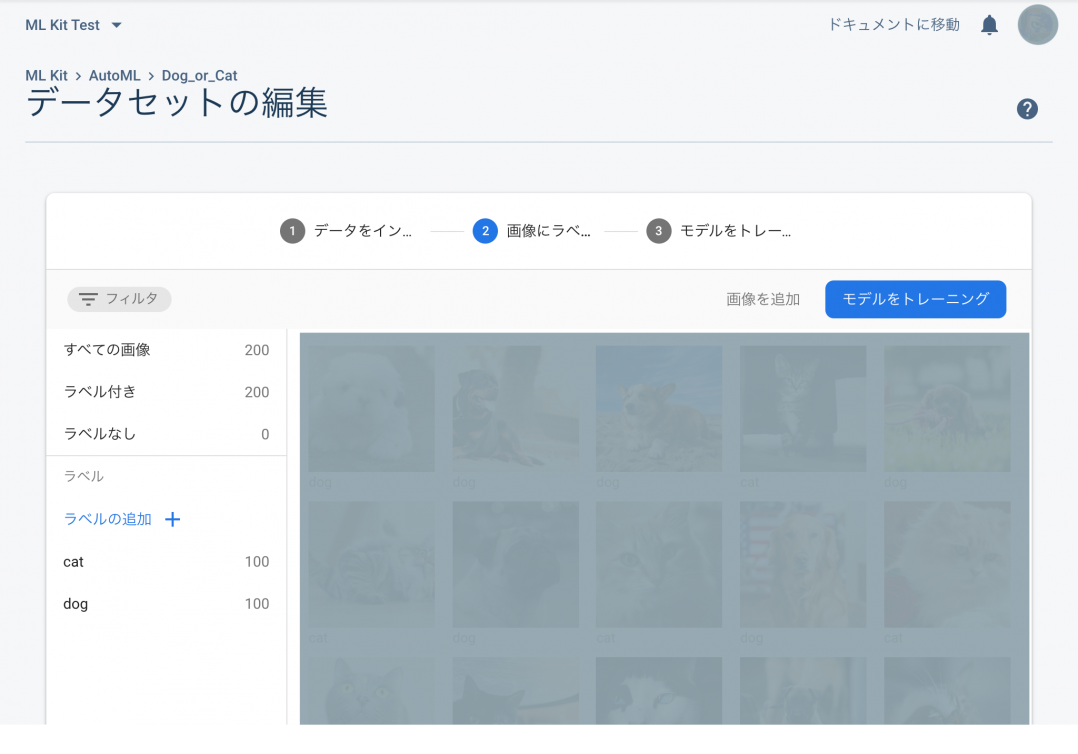
4.トレーニング開始
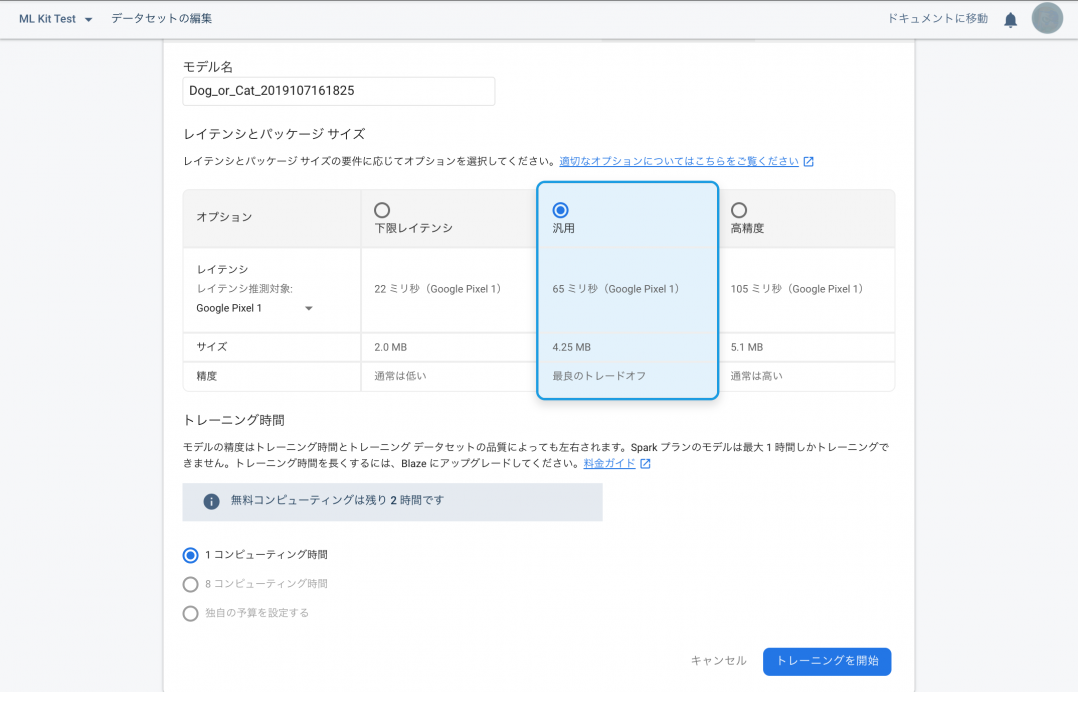
トレーニングを開始する前に、
- レイテンシとパッケージサイズのオプション
- トレーニング時間
を選択します。
レイテンシとパッケージサイズのオプション
精度より、速度やサイズを重視する場合は「下限レイテンシ」。
速度やサイズより、精度を重視する場合は「高精度」。
今回は、中間の「汎用」を選択します。
トレーニング時間
無料プランだと最大で1時間しか選択できない為、
「1コンピューティング時間」を選択します。
「レイテンシとパッケージサイズのオプション」と「トレーニング時間」の選択が終わったら、早速トレーニングを開始します!
トレーニングが完了するとメールで通知が送られてくるのでそれまで待機。。。
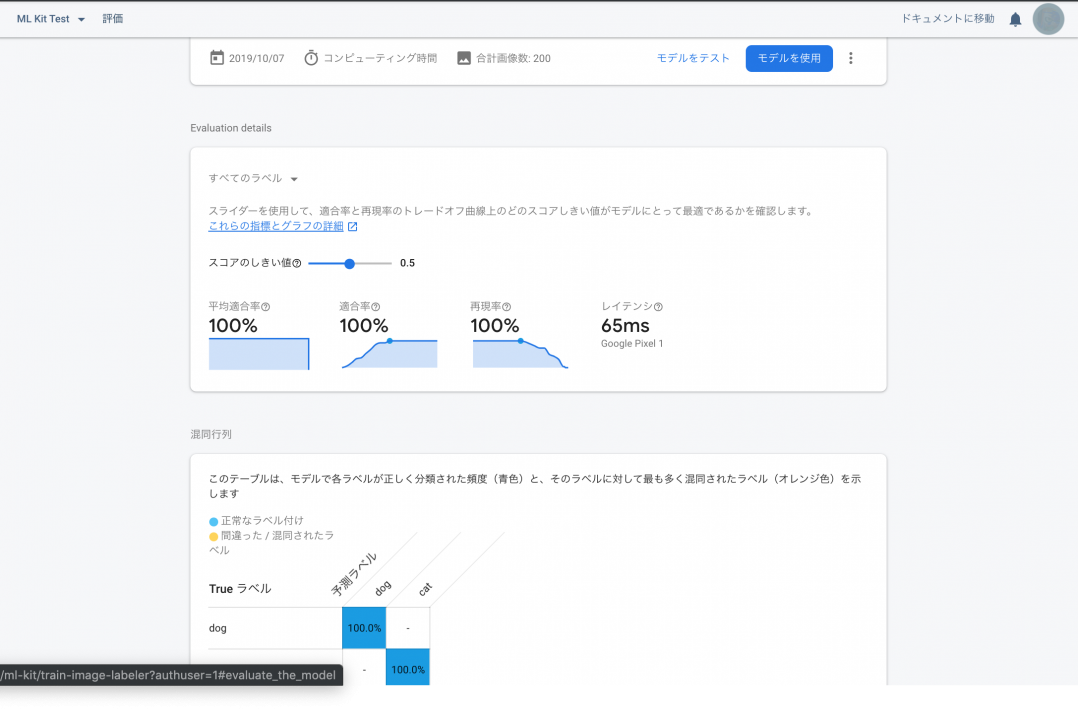
トレーニングが完了するとモデルの評価を確認する事ができます。
5.実際にモデルをテストしてみる
では、ちゃんと識別してくれるのか確認してみましょう!
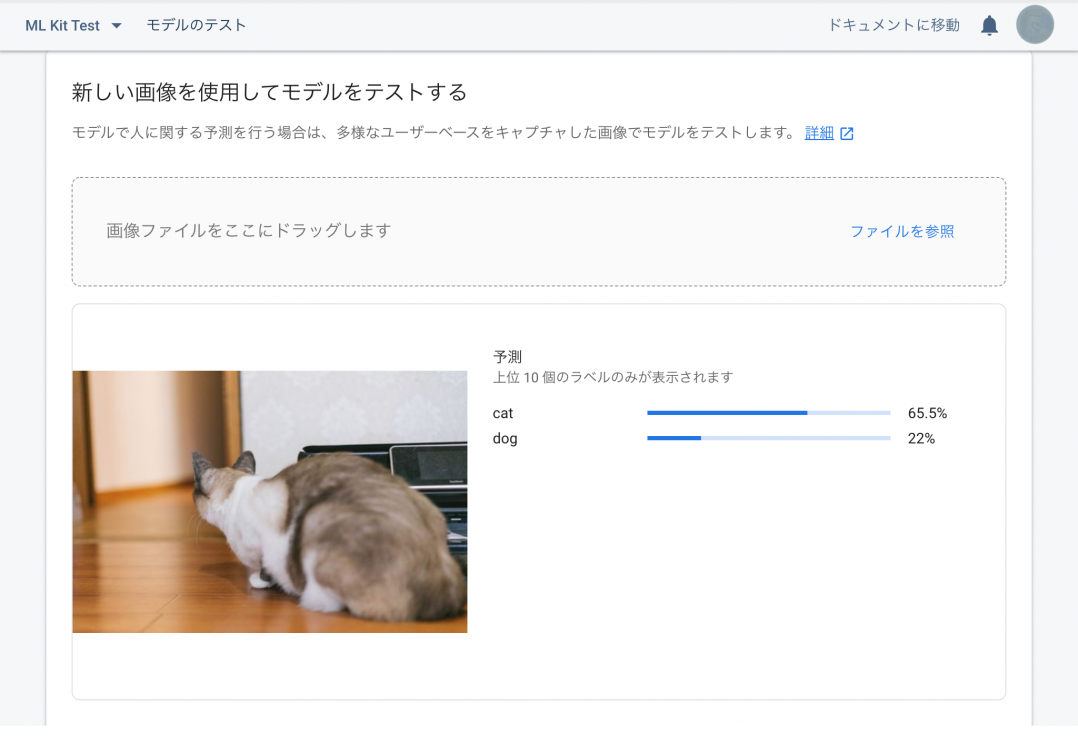
しっかり、識別してくれていますね!
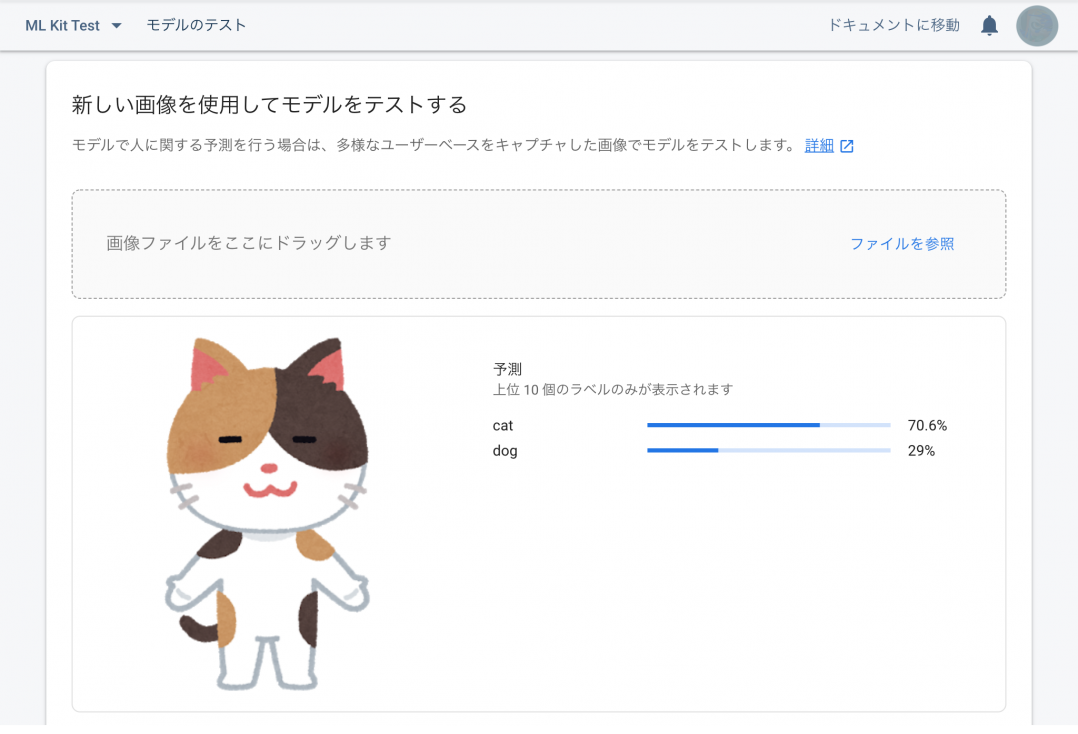
取り込んだデータは写真のみでしたが、イラストでもしっかり識別できています!
その他にも色々な画像で試してみましたが、それなりに精度は高いように感じました。
最後に
今回のような、犬と猫の画像識別であればML Kitの「画像のラベル付け」機能でも十分ですが、
ニッチな画像の識別であれば、お手軽にカスタムモデルが作成する事ができるのでかなり便利ですね!
「AutoML Vision Edge」は、まだβ版(2019年10月)ですが、
今後どういった機能が追加されるのか!注目していきたいと思います!
作成したカスタムモデルをアプリに組み込む方法に関しては、
「【iOS】Firebase ML Kit AutoML Vision Edgeを使ってみた – アプリ組み込み編 – 」で紹介しています!
